
本章概述
- K8S环境介绍
- K8S集群部署
- K8S常用命令
3.1 K8S环境介绍
1、K8S集群规划
| 组件名称 | 操作系统 | 数量 | ip地址 | 备注 |
|---|---|---|---|---|
| ansible | centos7 | 1台 | 172.31.7.101 | K8S集群部署服务器,可以和其他服务器混用,这里把ansible和master1混用 |
| master | centos7 | 3台 | 172.31.7.101 172.31.7.102 172.31.7.103 |
K8S控制端,通过一个VIP做高可用,这里VIP地址配置为172.31.7.188 |
| harbor | centos7 | 2台 | 172.31.7.104 172.31.7.105 |
高可用进行服务器 |
| etcd | centos7 | 最少3台 | 172.31.7.106 172.31.7.107 172.31.7.108 |
保存K8S集群数据的服务器 |
| haproxy | centos7 | 2台 | 172.31.7.109 172.31.7.110 |
高可用etcd代理服务器,keepalived部署在haproxy节点上,并配置VIP地址为172.31.7.188 |
| node | centos7 | 3台 | 172.31.7.111 172.31.7.112 172.31.7.113 |
真正运行容器的服务器,高可用环境至少两台 |
2、K8S集群逻辑架构图
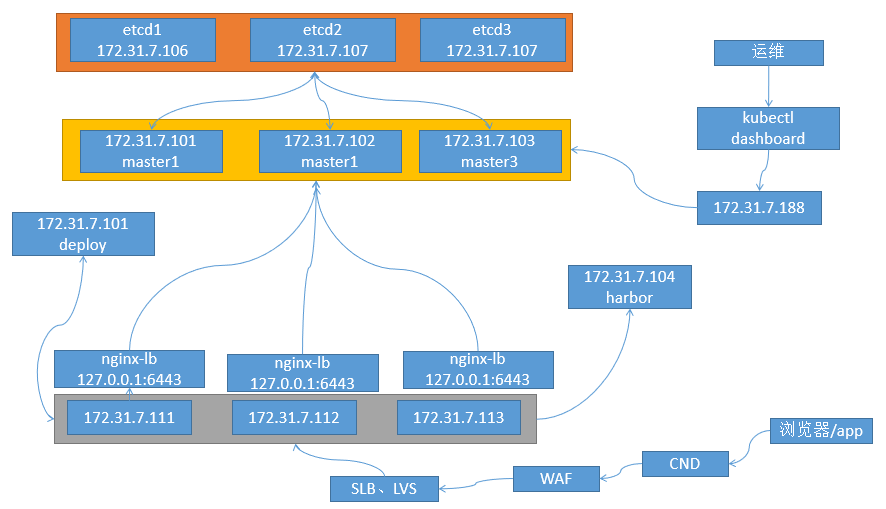
架构说明:
(1)k8s集群内部有三个小集群:etcd集群,master集群,node集群
(2)deploy部署服务器和master1混用,在同一个节点(172.31.7.101)
(3)etcd只能由master访问,其他节点不能访问etcd
(4)node节点通过在本地启用nginx作为负载(监听本地的6443端口),访问master集群(也可以单独启用一个节点,负载node节点上的所有pod,但该节点容易成为瓶颈)。注意:如果master节点增加,node节点上的nginx会动态更新,node节点增加,nginx配置则不会变化。
(5)在公司内部搭建私有harbor镜像仓库,为node节点提供镜像,pod拉起容器时,从私有镜像仓库拉取镜像
(6)运维人员通过访问keepalived VIP地址来访问K8S集群,keepalived服务提供高可用,haproxy作为master节点的负载
(7)客户端通过浏览器或者APP从外网经过CDN,WAF,内部负载访问K8S集群的node上的应用
3、服务器初始化脚本
#!/bin/bash
#Author:yuandangsheng
#filename:server-reset
#使用sed语法添加alias别名到/root/.bashrc中
sed -i '/Source/i alias cdnet="cd /etc/sysconfig/network-scripts/" ' /root/.bashrc
#定义别名切换到网络配置目录下
sed -i '/Source/i alias vie3="vim /etc/sysconfig/network-scripts/ifcfg-ens33"' /root/.bashrc
sed -i '/Source/i alias vie7="vim /etc/sysconfig/network-scripts/ifcfg-ens37"' /root/.bashrc
#定义别名编辑脚本
sed -i '/Source/i alias vimsh="/root/bin/createscript.sh"' /root/.bashrc
#更改提示符
echo 'PS1="\[\e[1;34m\][\u@\h \W]\\$\[\e[0m\]"' > /etc/profile.d/tishifu.sh
source /etc/profile.d/tishifu.sh
#关闭selinux
sed -i 's/SELINUX=enforcing /SELINUX= disabled/g' /etc/selinux/config
#centos7关闭防火墙,关闭开机自启动
systemctl stop firewalld
systemctl disable firewalld
iptables -F
#关闭NetworkManager,关闭开机自启动
systemctl stop NetworkManager
systemctl disable NetworkManager
#开启ipv4转发
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
sysctl -p3.2 K8S集群部署
K8S集群部署可参考github项目:https://github.com/easzlab/kubeasz
K8S集群部署步骤:https://github.com/easzlab/kubeasz/blob/master/docs/setup/00-planning_and_overall_intro.md
3.2.1 keepalived部署
(1)在172.31.7.109上配置keepalived:
节点172.31.7.109:
使用yum安装keepalived,修改配置文件
yum -y install keepalived
修改master节点上的keepalived配置文件,把172.31.7.109作为master角色
[root@k8s-haproxy1 ~]#cp /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp /etc/keepalived/keepalived.conf
[root@k8s-haproxy1 ~]#cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER #设置为MASTER角色,vip默认在该节点上
interface ens33 #注意修改本机网卡名称
garp_master_delay 10
smtp_alert
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.31.7.188 dev ens33 label ens33:0
172.31.7.189 dev ens33 label ens33:1
172.31.7.190 dev ens33 label ens33:2
}
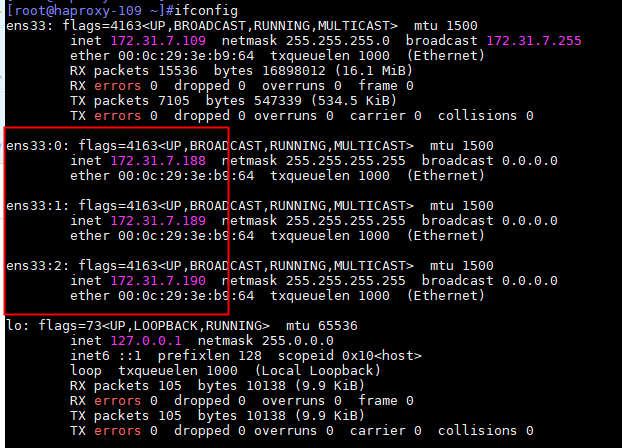
}重启keepalived服务,并设置为开机自启动
[root@k8s-haproxy1 ~]#systemctl restart keepalived
[root@k8s-haproxy1 ~]#systemctl enable keepalived
查看本机网卡地址,是否出现配置的vip地址
(2)在172.31.7.110上配置keepalived:
使用yum安装keepalived,修改配置文件
yum -y install keepalived
修改master节点上的keepalived配置文件,把172.31.7.110作为backup角色
[root@k8s-haproxy2 ~]#cp /usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp /etc/keepalived/keepalived.conf
[root@k8s-haproxy2 ~]#cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP #设置为MASTER角色,vip默认在该节点上
interface ens33 #注意修改本机网卡名称
garp_master_delay 10
smtp_alert
virtual_router_id 51
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.31.7.188 dev ens33 label ens33:0
172.31.7.189 dev ens33 label ens33:1
172.31.7.190 dev ens33 label ens33:2
}
}重启keepalived服务,并设置为开机自启动
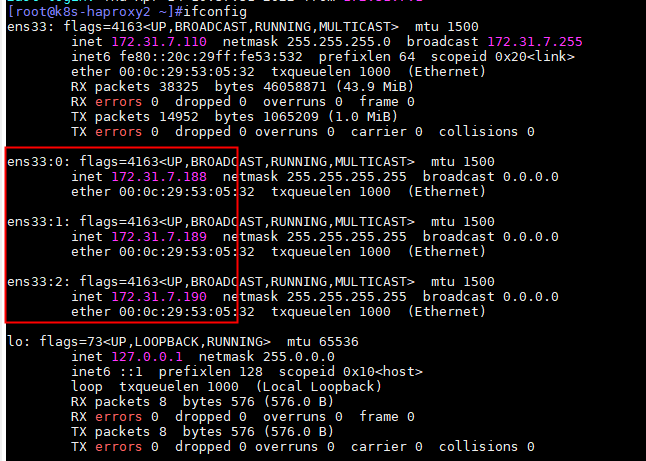
[root@k8s-haproxy2 ~]#systemctl restart keepalived
[root@k8s-haproxy2 ~]#systemctl enable keepalived
查看本机网卡地址,是否出现配置的vip地址
由于172.31.7.109默认为master,因此vip地址在172.31.7.109上
验证keepalived是否生效:
在172.31.7.109上停止keepalived服务,查看本机上是否出现vip地址。
测试完成后,在172.31.7.109上再启用keepalived服务
3.2.2 haproxy部署
(1)在172.31.7.109上配置haproxy
yum安装haproxy
yum -y install haproxy
更改haproxy配置文件,只需在defaults配置后增加以下配置即可
vim /etc/haproxy/haproxy.cfg
listen k8s-api-6443
bind 172.31.7.188:6443 #绑定本机的6443端口
mode tcp #设置为tcp模式
server master1 172.31.7.101:6443 check inter 3s fall 3 rise 1 #设置后端服务名称为master1,健康检查每隔3S检查一次,检测失败3次就踢出该节点,成功1次加入该节点
server master2 172.31.7.102:6443 check inter 3s fall 3 rise 1 #设置后端服务名称为master2,健康检查每隔3S检查一次,检测失败3次就踢出该节点,成功1次加入该节点
server master3 172.31.7.103:6443 check inter 3s fall 3 rise 1 #设置后端服务名称为master2,健康检查每隔3S检查一次,检测失败3次就踢出该节点,成功1次加入该节点重启haproxy服务,并设置为开机自启动
systemctl restart haproxy
systemctl enable haproxy
查看本机监听端口是否存在6443端口

(2)在172.16.31.110上配置haproxy
yum安装haproxy
yum -y install haproxy
更改haproxy配置文件,只需在defaults配置后增加以下配置即可
vim /etc/haproxy/haproxy.cfg
listen k8s-api-6443
bind 172.31.7.188:6443 #绑定本机的6443端口
mode tcp #设置为tcp模式
server master1 172.31.7.101:6443 check inter 3s fall 3 rise 1 #设置后端服务名称为master1,健康检查每隔3S检查一次,检测失败3次就踢出该节点,成功1次加入该节点
server master2 172.31.7.102:6443 check inter 3s fall 3 rise 1 #设置后端服务名称为master2,健康检查每隔3S检查一次,检测失败3次就踢出该节点,成功1次加入该节点
server master3 172.31.7.103:6443 check inter 3s fall 3 rise 1 #设置后端服务名称为master2,健康检查每隔3S检查一次,检测失败3次就踢出该节点,成功1次加入该节点重启haproxy服务,并设置为开机自启动
systemctl restart haproxy
systemctl enable haproxy
注意:在第二台机器上启用haproxy服务会出现以下报错:
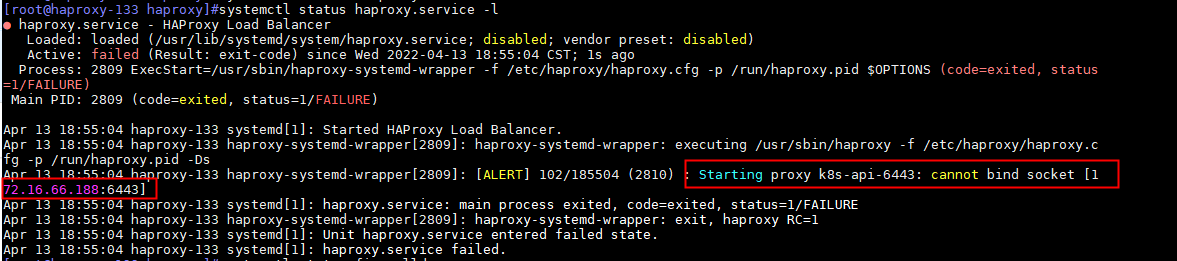
原因:vip地址172.31.7.188只能同时存在一台服务器上,而vip地址172.31.7.188在master节点172.31.7.109上,backup节点172.31.7.110上不存在该地址,因此无法绑定socket在172.31.7.188上。
解决方法:增加内核参数:允许绑定非本机的IP
vim /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind=1添加后执行命令,使配置生效:
sysctl -p
注意:如果配置后还存在无法绑定socket的报错,检查本机selinux是否关闭
另外,在master节点172.31.7.109也配置该参数,防止VIP地址漂移之后,本地haproxy服务无法正常启动
3.2.3 基于https的harbor部署
在172.31.7.104和172.31.7.105上部署harbor
部署前准备工作:
安装harbor需要先把docker和docker-compose安装好,因此需要以下几个安装包:
docker的二进制安装包,下载url:
https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/static/stable/x86_64/docker-20.10.14.tgz
docker-compose的offline安装包,下载url:
https://github.com/docker/compose/releases/download/v2.4.1/docker-compose-linux-x86_64
harbor的安装包,下载url:
https://github.com/goharbor/harbor/releases/download/v2.4.2/harbor-offline-installer-v2.4.2.tgz
安装包下载完成后上传到172.31.7.109/110的/usr/local/src/目录下
创建存放脚本目录
mkdir -p /root/scripts
创建脚本,并执行脚本安装harbor,脚本内容如下:
vim /root/scritps/harbor_install.sh
#!/bin/bash
echo "############1.docker 开始安装#####################################"
#设置变量
package_path="/usr/local/src"
#安装清华大学epel镜像
yum -y install epel-release
sed -e 's!^metalink=!#metalink=!g' \
-e 's!^#baseurl=!baseurl=!g' \
-e 's!//download\.fedoraproject\.org/pub!//mirrors.tuna.tsinghua.edu.cn!g' \
-e 's!//download\.example/pub!//mirrors.tuna.tsinghua.edu.cn!g' \
-e 's!http://mirrors!https://mirrors!g' \
-i /etc/yum.repos.d/epel*.repo
#安装基础工具
yum -y install vim wget tree lrzsz openssl openssl-devel iproute net-tools iotop zip
#如果存在docker,需要先把docker删除
yum -y remove docker docker-common docker-selinux docker-engine
#安装docker依赖
yum install -y yum-utils device-mapper-persistent-data lvm2 wget
#安装docker镜像源
wget -O /etc/yum.repos.d/docker-ce.repo https://download.docker.com/linux/centos/docker-ce.repo
#把镜像源中docker官网镜像源改成清华大学镜像源,下载更快
sed -i 's+download.docker.com+mirrors.tuna.tsinghua.edu.cn/docker-ce+' /etc/yum.repos.d/docker-ce.repo
#生成缓存镜像并安装docker
yum makecache fast
yum -y install docker-ce
#启动docker
systemctl daemon-reload
systemctl start docker
#设置开机自启动
systemctl enable docker
#把docker用户加入docker组
useradd docker
useradd docker -G docker
#创建普通用户,加入docker组
id -u magedu > /dev/null
if [ $? -eq 0 ];then
echo "user exist"
else
useradd magedu -G docker
fi
#更改内核参数
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-ip6tables = 1" >> /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-ip6tables = 1" >> /etc/sysctl.conf
sysctl -p
#docker安装成功
echo "docker安装成功!!!"
echo "############2.docker-compose 开始安装#####################################"
#设置变量
compose_version=v2.4.1
#切换存放安装包的目录
cd ${package_path}
#下载harbor安装包
ls docker-compose-linux-x86_64
if [ $? -eq 0 ];then
echo "file exist,not need to download"
else
wget https://github.com/docker/compose/releases/download/${compose_version}/docker-compose-linux-x86_64
fi
#把docker-compse复制到/usr/bin/目录下,并赋予执行权限
cp docker-compose-linux-x86_64 /usr/bin/docker-compose
chmod a+x /usr/bin/docker-compose
#docker-compose安装成功
echo "docker-compose安装成功!!!"
echo "############3.harbor 开始安装#####################################"
#设置变量
harbor_version=v2.4.2
harbor_path="/usr/local/src/harbor"
harbor_domian="harbor.magedu.com"
cert_path="/usr/local/src/harbor/certs"
#创建相应目录
mkdir -p ${harbor_path}
mkdir -p ${cert_path}
#切换harbor安装目录,注意compose_path变量的值
cd ${package_path}
#下载harbor安装包
ls ${package_path}/harbor-offline-installer-${harbor_version}.tgz
if [ $? -eq 0 ];then
echo "file exist,not need to download"
else
wget https://github.com/goharbor/harbor/releases/download/${harbor_version}/harbor-offline-installer-${harbor_version}.tgz
fi
#解压harbor安装包
tar -xvf harbor-offline-installer-${harbor_version}.tgz
#生成证书
cd ${cert_path}
openssl genrsa -out ./harbor-ca.key
openssl req -x509 -new -nodes -key ./harbor-ca.key -subj "/CN=harbor.magedu.local" -days 36500 -out ./harbor-ca.crt
#更改harbor配置文件
cd ${harbor_path}
cp harbor.yml.tmpl harbor.yml
#创建存储harbor镜像的目录
mkdir -p /data/harbordata
#更改harbor配置文件
#更改harbor域名
sed -i 's#hostname: reg.mydomain.com#hostname: harbor.magedu.local#g' harbor.yml
#更改harbor的公钥
sed -i 's#certificate: /your/certificate/path#certificate: /usr/local/src/harbor/certs/harbor-ca.crt#g' harbor.yml
#更改harbor的私钥
sed -i 's#private_key: /your/private/key/path#private_key: /usr/local/src/harbor/certs/harbor-ca.key#g' harbor.yml
#更改harbor的登录密码
sed -i 's#harbor_admin_password: Harbor12345#harbor_admin_password: 123456#g' harbor.yml
#更改harbor存储镜像的目录
sed -i 's#data_volume: /data#data_volume: /data/harbordata#g' harbor.yml
#注意:如果使用证书,忽略以下命令;如果不使用证书,去掉以下命令前的注释
#sed -i 's/port: 443/#port: 443/g' harbor.yml
#sed -i 's/certificate:/#certificate:/g' harbor.yml
#sed -i 's/private_key:/#private_key:/g' harbor.yml
#执行安装命令,开启扫描器
cd ${harbor_path}/harbor
./install.sh --with-trivy
#安装成功,返回success
echo "harbor安装成功"执行脚本安装harbor
bash /root/scripts/harbor_install.sh
注意:在脚本中harbor配置有四个地方需要注意,如果想要自定义,则需要更改脚本内容
(1)harbor的域名:harbor.magedu.local
(2)开启443端口的公私钥文件
(3)harbor的密码:123456
(4)harbor的存储路径:/data/harbordata
脚本执行完成后,在浏览器输入harbor节点ip地址https://172.31.7.104访问
如果要想通过域名访问,则需要在访问harbor的机器本地hosts文件中加入域名解析
172.31.7.104 harbor.magedu.local
172.31.7.105 harbor.magedu.local
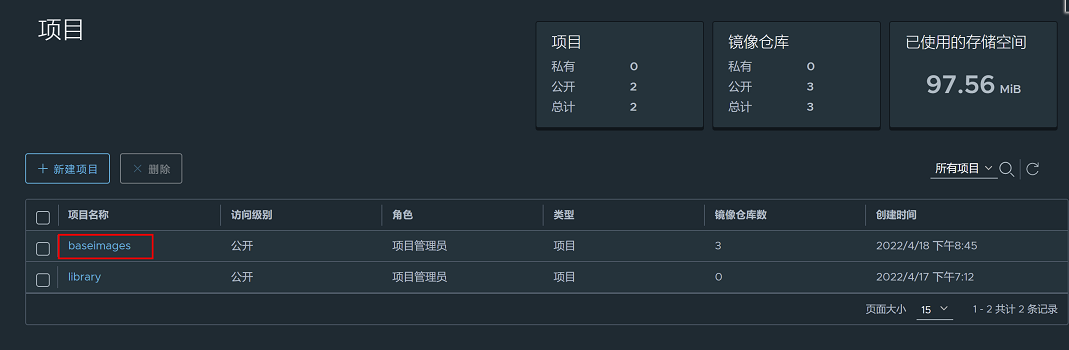
在网站上创建存放基础镜像的项目:baseimages
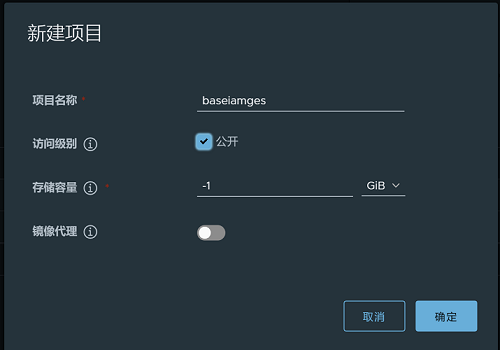
项目名称:baseimages
访问级别:勾选公开,如果不勾选,会自动创建私有仓库,无论上传还是下载都需要登录
存储容量:-1表示对容量不做限制
查看项目是否创建成功
注意:要想将镜像上传至该项目,上传时要加上该项目才可以,如:
docker push nginx:1.20.2 harbor.magedu.local/baseimages/nginx:1.20.2
在客户端本地访问基于https协议的harbor私有镜像仓库
注意:哪台机器需要访问https的私有镜像仓库,在哪台机器上进行配置
这里以master1节点172.31.7.101为例
在172.31.7.101上执行命令:
mkdir -p /etc/docker/certs.d/harbor.magedu.local
注意:创建目录时,在harbor配置文件中配置的harbor域名是什么,就要在/etc/docker/certs.d目录下创建什么目录,这里创建的是harbor.magedu.local目录
在172.31.7.104(harbor镜像服务器地址)上执行命令
scp /usr/local/src/harbor/certs/harbor-ca.crt 172.31.7.101:/etc/docker/certs.d/harbor.magedu.local/
在172.31.7.101上配置本地域名解析
vim /etc/hosts
172.31.7.104 harbor.magedu.local
在172.31.7.101上登录验证

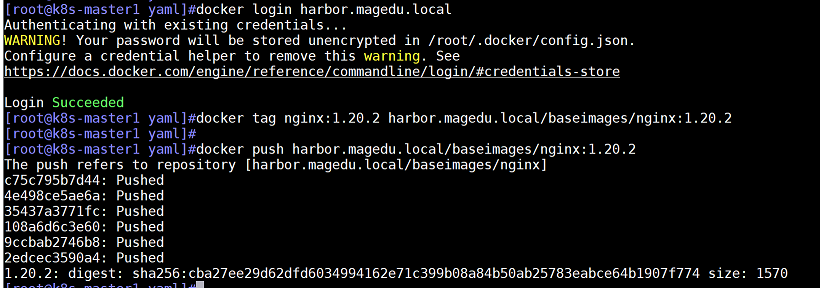
下载测试镜像并更改镜像标签
docker pull nginx:1.20.2
docker tag nginx:1.20.2 harbor.magedu.local/baseimages/nginx:1.20.2
docker push harbor.magedu.local/baseimages/nginx:1.20.2
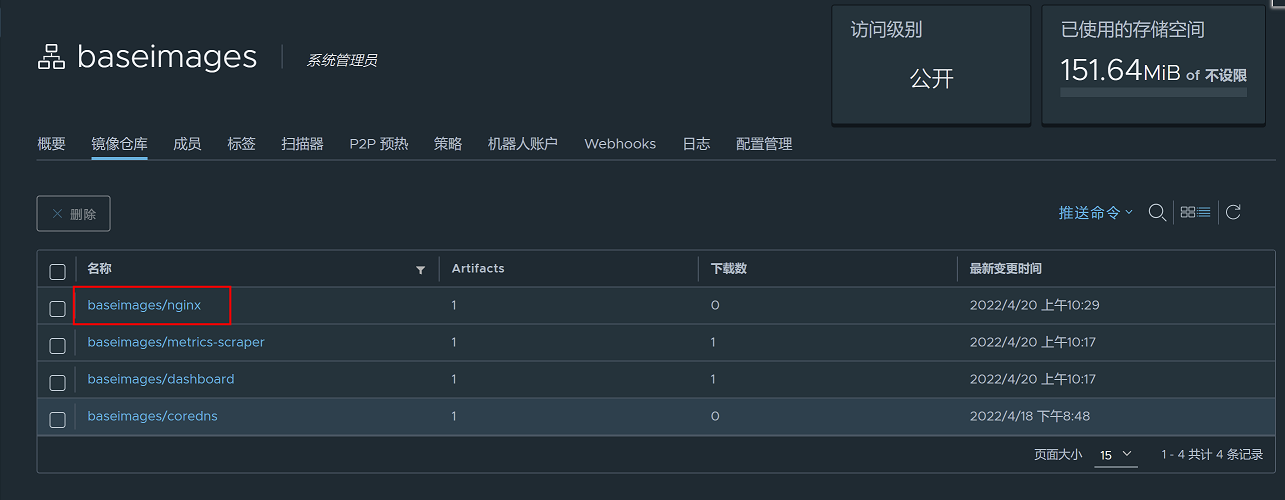
登录镜像仓库网站查看baseimages项目下是否存在该镜像
3.2.4 Deploy部署服务器配置
1、安装ansible
由于deploy部署服务器和master1节点公用,因此需要在172.31.7.101上安装ansible
执行命令:
yum -y install ansible
注意:安装ansible报错:GPG key retrieval failed: [Errno 14] curl#37 - "Couldn't open file /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7"
解决方法:
cd /etc/pki/rpm-gpg/
wget https://archive.fedoraproject.org/pub/epel/RPM-GPG-KEY-EPEL-7
下载完成后再次安装即可解决。2、把deploy部署服务器和其他几台服务器(包括master1/2,node1/2/3,etcd1/2/3)做免密认证
免密认证操作如下:
ssh-keygen
ssh-copy-id x.x.x.x #这里x.x.x.x是指需要免密访问的机器
注意:如果服务器较多,则可以通过脚本进行分发
免密认证做完以后进行验证,查看是否可以免密访问
ssh 172.31.7.102 #这里以master2为例进行验证在节点执行python命令,如果不能单独执行,则需要为每个节点设置python软链接
通过whereis python查看本机python路径,然后根据查询到的python路径做软链接
ln -sv /usr/bin/python3 /usr/bin/python
注意:只要是通过ansible管理的节点都需要做软链接
3.2.5 K8S安装部署
3.2.5.1 安装前准备工作
1、在部署节点(172.31.7.101)编排k8s安装
下载工具脚本ezdown,使用kubeasz版本3.2.0
export release=3.2.0 #声明环境变量,指定ezdown版本
wget https://github.com/easzlab/kubeasz/releases/download/${release}/ezdown
chmod a+x ./ezdown
2、自定义更改脚本配置
编辑ezdown脚本
vim ezdown
DOCKER_VER=19.03.15 #指定docker版本为19.03.15使用工具脚本下载
./ezdown -D
注意:该脚本会自动检测节点上是否存在docker,如果不存在则会安装docker
由于自动安装的docker路径无法自定义,因此可根据需求自己手动安装docker
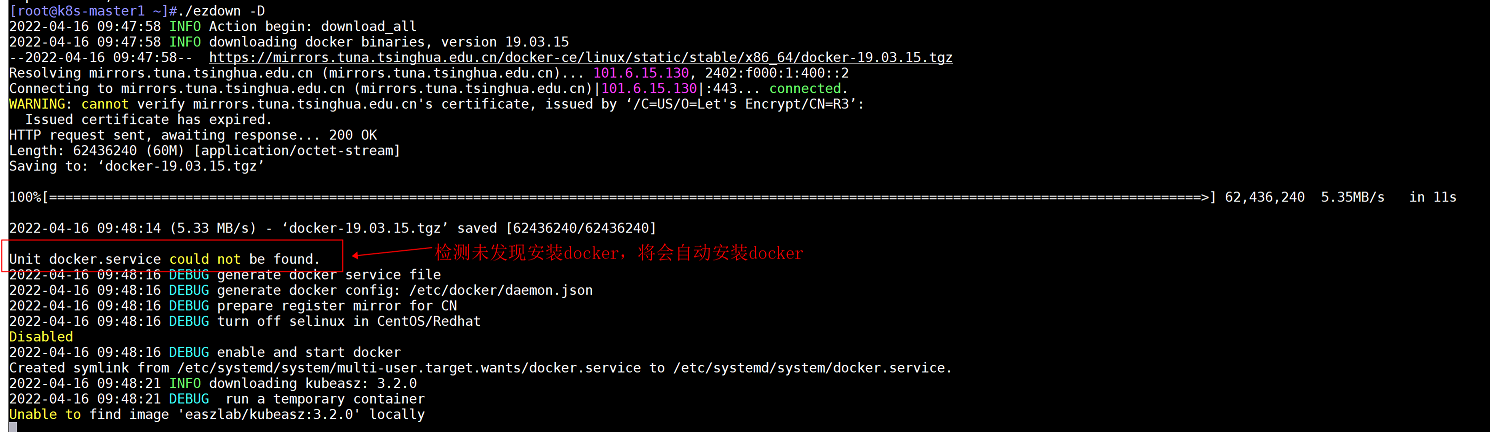
脚本执行过程中会自动下载镜像,下载完成后进行下一步配置
3、创建集群配置文件,并根据实际情况进行修改
cd /etc/kubeasz/
./ezctl new k8s-cluster1 #这里k8s-cluster1是指K8S集群名称
执行完该命令后会在/etc/kubezsz目录下自动生成k8s集群的配置文件


根据前面节点规划修改hosts 文件和其他集群层面的主要配置选项;其他集群组件等配置项可以在config.yml 文件中修改。
注意:规划时有3个master和3个node,为了后续便于演示如何扩容master节点和node节点,配置文件中k8s集群的master和node节点先部署两台
(1)修改hosts文件
vim /etc/kubeasz/clusters/k8s-cluster1/hosts
[etcd] #etcd节点地址,根据规划进行更改
172.31.7.106
172.31.7.107
172.31.7.108
# master node(s) #master节点地址,根据规划进行更改
[kube_master]
172.31.7.101
172.31.7.102
# work node(s) #node节点地址,根据规划进行更改
[kube_node]
172.31.7.111
172.31.7.112
[ex_lb] #更改负载均衡器VIP地址为172.31.7.188和端口为6443
172.31.7.6 LB_ROLE=backup EX_APISERVER_VIP=172.31.7.188 EX_APISERVER_PORT=6443
172.31.7.7 LB_ROLE=master EX_APISERVER_VIP=172.31.7.188 EX_APISERVER_PORT=6443
#注意:这里的负载均衡不会使用脚本部署,而是会在后续在进行部署,这里只更改VIP地址和端口号
CONTAINER_RUNTIME="docker" #更改K8S集群运行时为“docker”
CLUSTER_NETWORK="calico" #网络组件试用calico。注意:私有云环境可以使用calico,公有云环境不支持calico,可以使用flannel或者公有云自己提供的网络插件
PROXY_MODE="ipvs" #service网络使用ipvs模式,不变
SERVICE_CIDR="10.100.0.0/16" #service网段,这里更改为10.100.0.0
CLUSTER_CIDR="10.200.0.0/16" #pod网络,这里更改为10.200.0.0
#注意:service和pod网络在规划时要和宿主机网络以及其他机房网络区分开,为了便于后期扩容,子网范围最少要使用21位,推荐使用16位子网,有足够的ip地址可以使用
NODE_PORT_RANGE="30000-65000" #用于暴露k8s集群中服务的端口号给外网访问,这里更改范围为30000-65000。
#注意:一旦端口规划完成,一定要在公司内部约定该范围内的端口只能给K8S集群使用,其他应用或服务不能使用
CLUSTER_DNS_DOMAIN="magedu.local" #自定义K8S集群内部创建service的域名后缀,这里更改为magedu.local
bin_dir="/usr/local/bin" #K8S集群二进制目录,这里更改为/usr/local/bin。包括kubectl,kubelet,apiserver,kube-scheduler,kube-controller-manager等。该目录可自定义,脚本会自动把该目录软链接到/usr/bin
base_dir="/etc/kubeasz" #K8S集群部署路径
cluster_dir="{{ base_dir }}/clusters/k8s-cluster1" #集群配置文件路径,集群配置文件hosts和config.yml文件都在该目录下
ca_dir="/etc/kubernetes/ssl" #集群证书路径,K8S集群存放自签证书路径(2)修改config.yml配置文件
vim /etc/kubeasz/cluster/k8s-cluster1/config.yml
INSTALL_SOURCE: "online" #选择安装模式在线安装或离线安装,如果本地有镜像会优先使用本地,如果本地没有则会在线安装。如果环境无法联网,则需要提前下载好镜像
ntp_servers: #修改时间服务器
- "ntp1.aliyun.com"
- "time1.cloud.tencent.com"
- "0.cn.pool.ntp.org"
#注意:如果宿主机时间不准确,可通过以下配置修改服务器时间,修改完成后重启服务器生效
#修改服务器为24小时形式显示
#echo “LC_TIME=enDK.UTF-8” >> /etc/default/locale
#设置计划任务,定期进行时间同步
#echo “*/5 * * * * ntpdate time1.aliyun.com &> /dev/null && hwclock -w” > /var/spool/cron/crontables/root
#执行命令创建软链接
#ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
CA_EXPIRY: "876000h" #ca证书有效时间,默认为100年
CERT_EXPIRY: "438000h" #cert证书有效时间,默认为50年
ENABLE_MIRROR_REGISTRY: true #启用镜像仓库
#注意:如果想要在集群部署前,在docker内加入参数,可以查看以下文件进行修改
#/etc/kubeasz/roles/docker/templates/docker.service.j2 该文件是docker的docker.service文件,可以加入启动参数
#/etc/kubeasz/roles/docker/templates/daemon.json.j2 该文件是docker的daemon.json文件,可以加入镜像仓库或加速器等
INSECURE_REG: '["127.0.0.1/8","172.31.7.109"]' #配置信任的非安全(HTTP)镜像仓库地址,如果部署的私有仓库没有配置https,需要在这里把私有镜像仓库harbor的ip地址172.31.7.109加入,如果部署的私有镜像仓库是基于https部署的,则不需要在这里配置
MASTER_CERT_HOSTS: #k8s集群master节点ip
- "172.31.7.188"
- "k8s.test.io"
#- www.test.com
#注意:如果k8s集群使用公网负载均衡和域名,可以把负载均衡地址和域名写入该配置,写入之后K8S集群就会像负载均衡地址和域名签发证书,就可以通过地址和域名访问k8s,这里地址配置为VIP地址172.31.7.188
MAX_PODS: 500 #node节点最大pod数,这里更改为300
CALICO_IPV4POOL_IPIP: "Always" #是否开启IPIP,默认开启,如果关闭则只能在局域网访问,将不能跨子网访问
# coredns 自动安装
dns_install: "no" #是否安装coredns,默认为yes,为了后续演示dns安装,关闭coredns的安装
corednsVer: "1.8.6"
ENABLE_LOCAL_DNS_CACHE: false #是否开启主机dns缓存,开启之后会自动生成一个dns容器,减轻coredns的压力,可以开启。这里为了后续演示dns安装,配置为false
dnsNodeCacheVer: "1.21.1"
# 设置 local dns cache 地址
LOCAL_DNS_CACHE: "169.254.20.10" #如果开启dns缓存,可以指定缓存容器的地址
# metric server 自动安装
metricsserver_install: "no" #是否安装metric server,默认为yes,这里为了后续演示,配置为no
metricsVer: "v0.5.2"
# dashboard 自动安装
dashboard_install: "no" #是否安装dashboard,默认为yes,这里为了后续演示,配置为no
dashboardVer: "v2.4.0"
dashboardMetricsScraperVer: "v1.0.7"
# ingress 自动安装
ingress_install: "no" #这里默认为no,后续进行手动安装,如果想要安装可以配置为yes
ingress_backend: "traefik"
traefik_chart_ver: "10.3.0"
# prometheus 自动安装
prom_install: "no" #这里默认为no,后续进行手动安装,如果想要安装可以配置为yes
prom_namespace: "monitor"
prom_chart_ver: "12.10.6"
# nfs-provisioner 自动安装
nfs_provisioner_install: "no" #默认为no,如果想要安装可以配置为yes,这里不启用
nfs_provisioner_namespace: "kube-system"
nfs_provisioner_ver: "v4.0.2"
nfs_storage_class: "managed-nfs-storage"
nfs_server: "192.168.1.10" #指定nfs地址
nfs_path: "/data/nfs" #指定nfs存储目录
#如果开启nfs,k8s创建pv和pvc的时候,都会调用nfs。可以用来存储K8S集群的数据,包括容器的数据,数据库的数据等,用来持久化容器内的业务数据(3)虽然我们使用自建的负载均衡器,但部署时,脚本仍会对负载均衡器进行初始化,为了避免这一操作,可以通过修改01.prepare.yml文件,删除“- ex_lb”和“- chrony”,使脚本不对负载均衡进行初始化
vim /etc/kubeasz/playbooks/01.prepare.yml
# [optional] to synchronize system time of nodes with 'chrony'
- hosts:
- kube_master
- kube_node
- etcd
- ex_lb #注意要删除该行
- chrony #时间服务器也不需要,也可以删除
roles:
- { role: os-harden, when: "OS_HARDEN|bool" }
- { role: chrony, when: "groups['chrony']|length > 0" }
# to create CA, kubeconfig, kube-proxy.kubeconfig etc.
- hosts: localhost
roles:
- deploy
# prepare tasks for all nodes
- hosts:
- kube_master
- kube_node
- etcd
roles:
- prepare3.2.5.2 开始安装K8S
cd /etc/kubeasz/
./ezctl setup k8s-cluster1 01 #对k8s-cluster1集群进行01操作,环境准备工作

./ezctl setup k8s-cluster1 02 #对k8s-cluster1集群进行02操作,部署etcd
./ezctl setup k8s-cluster1 03 #对k8s-cluster1集群进行03操作,部署runtime
./ezctl setup k8s-cluster1 04 #对k8s-cluster1集群进行04操作,部署master
./ezctl setup k8s-cluster1 05 #对k8s-cluster1集群进行05操作,部署node
./ezctl setup k8s-cluster1 06 #对k8s-cluster1集群进行06操作,部署网络组件
在执行过程中存在以下提示,可忽略

安装完成后,进行测试验证:
创建容器进行测试:
kubectl run net-test1 --image=centos:7.9.2009 sleep 3600000
kubectl run net-test2 --image=centos:7.9.2009 sleep 3600000
查看容器是否创建成功:
kubectl get pod -o wide

进入容器进行ping测试,查看两个不同node上的容器是否可以通信
kubectl exec -it net-test1 bash
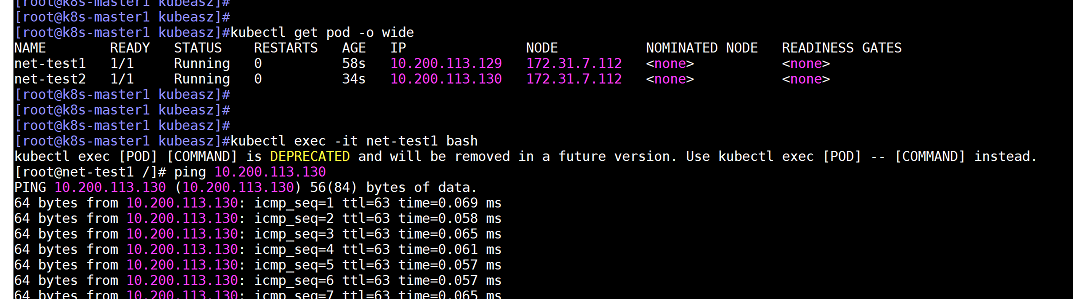
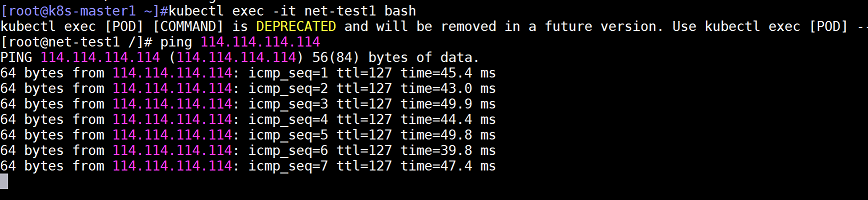
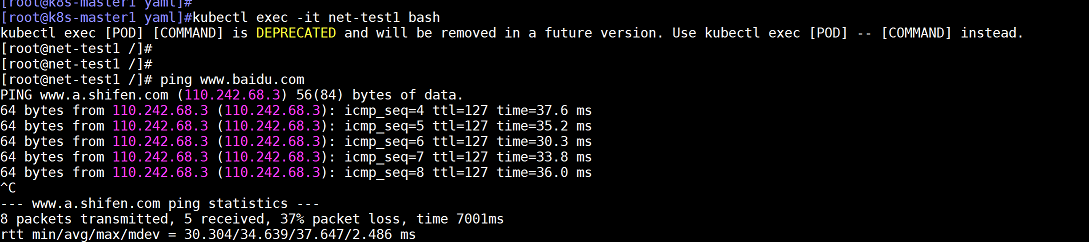
注意:这里由于没有配置dns,公网域名是无法ping通的,但是公网ip地址必须保证可以ping通,否则网络是有问题的
备注:114.114.114.114是公网dns服务器地址,可以使用该地址用来测试和公网是否联通
查看K8S集群node状态

注意:可以看到上图中master节点处于SchedulingDisabled状态,即master节点不参与调度,这是为了防止master节点被占用过多资源导致master节点资源不足而无法及时响应。因此一般情况下,master节点不能被调度
查看pod状态,发现一个calico状态异常,且该容器在节点172.31.7.112上
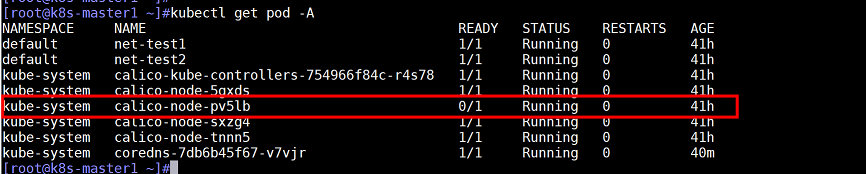
查看容器日志,报错如下:(BGP邻居关系获取不到)

排查发现由于两台node节点主机名一样(node1和node2的主机名均为k8s-node),导致BGP邻居创建失败

解决方法:
(1)先更改两台node节点的主机名,分别为k8s-node1,k8s-node2
(2)把两台node节点删除再重新加入
cd /root/kubeasz
先把状态异常calico所在节点172.31.7.112删除,再重新加入
./ezctl del-node k8s-cluster1 172.31.7.112
./ezctl add-node k8s-cluster1 172.31.7.112
再把状态异常calico所在节点172.31.7.113删除,再重新加入
./ezctl del-node k8s-cluster1 172.31.7.113
./ezctl add-node k8s-cluster1 172.31.7.1133.2.6 Coredns安装部署
通过yaml文件的方式部署coredns
3.2.6.1 安装前准备工作
1、获取yaml文件:
(1)进入github官网https://github.com
搜索kebernetes

(2)点击进入kubernetes项目
(3)点击右侧release
(4)查找需要下载的版本
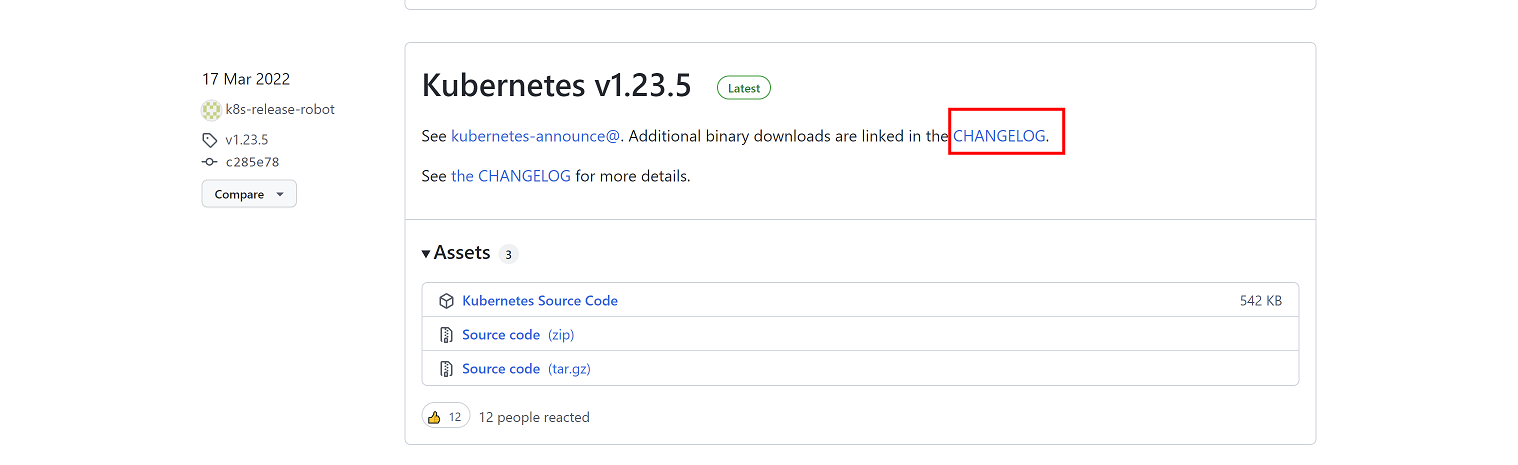
(5)找到想要的版本,点击CHANGLOG,这里下载1.23.5版本
(6)点击进入
(7)注意需要下载以下文件
a、源码文件,包括脚本,yaml文件等
下载链接:https://dl.k8s.io/v1.23.5/kubernetes.tar.gz
b、client二进制文件,包括kubectl
下载链接:https://dl.k8s.io/v1.23.5/kubernetes-client-linux-amd64.tar.gz
c、server二进制文件,包括kube-apiserver,kube-controller-manager等
下载链接:https://dl.k8s.io/v1.23.5/kubernetes-server-linux-amd64.tar.gz
d、node二进制文件,包括kubelet,kube-proxy
下载链接:https://dl.k8s.io/v1.23.5/kubernetes-node-linux-amd64.tar.gz
2、下载完成后,把压缩包上传到master1的/usr/loca/src/目录下,然后解压,这些文件会集中解压到kubernetes目录下
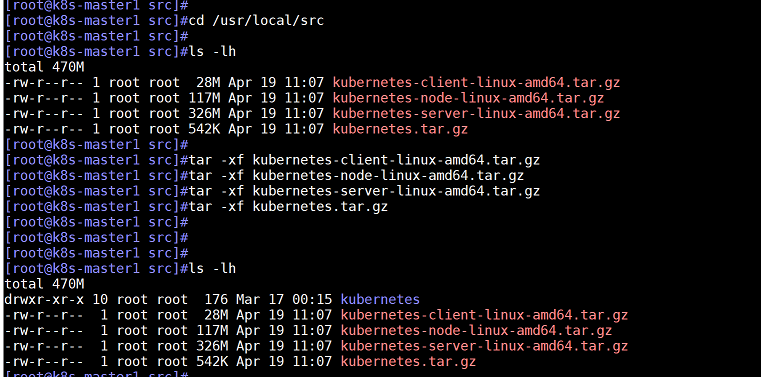
找到coredns yaml文件模板

创建专门存放yaml文件的目录/root/yaml/,把coredns的yaml存放到该目录下并修改yaml文件

更改以下内容:(注意:修改内容为配置文件中添加注释的内容)
vim /root/yaml/coredns.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes magedu.local in-addr.arpa ip6.arpa { #把”__DNS__DOMAIN__”更改为指定的k8s域名后缀,该域名后缀即部署k8s时在/etc/kubeasz/clusters/k8s-cluster1/hosts文件中CLUSTER_DNS_DOMAIN参数指定的域名后缀:magedu.local
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . 223.6.6.6 { #指定coredns转发的DNS服务器,即coredns解析不了的地址,向该地址转发。默认指向/etc/resolv.conf,可以指向公司内部自建dns,这里指向223.6.6.6。
max_concurrent 1000 #可以指定最大连接数
}
cache 30 #指定DNS缓存时间,默认30s。将第一次查询到的dns解析关系缓存下来,30s内有查询同一个域名的请求,直接将缓存返回
loop
reload
loadbalance
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
priorityClassName: system-cluster-critical
serviceAccountName: coredns
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values: ["kube-dns"]
topologyKey: kubernetes.io/hostname
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
nodeSelector:
kubernetes.io/os: linux
containers:
- name: coredns
image: coredns/coredns:1.8.7 #注意,通过yaml文件部署时,需要下载镜像,文件默认的镜像仓库是谷歌k8s官方镜像仓库,无法访问,需要更改为可以访问的镜像仓库地址,去docker官网查找coredns镜像,官网链接https://hub.docker.com/r/coredns/coredns/tags,然后更改镜像地址,这里更改为docker官方镜像仓库:coredns/coredns:1.8.7
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 200Mi #限制容器可以使用的内存资源,这里设置为200m(毫核)。注意:1核=1000m(毫核)。如果数字后不带Mi,默认为核,如果带有m,则为毫核
requests:
cpu: 100m
memory: 70Mi
---
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.100.0.2 #设置DNS容器地址注意:查看DNS容器地址的方法:
在集群内创建一个容器,进入容器查看/etc/resolve.conf文件,DNS容器地址就是nameserver的地址

小知识:
k8s集群内的ip地址是自动分配的,根据部署K8S集群配置文件/etc/kubeasz/clusters/k8s-cluster1/hosts中SERVICE_CIDR字段指定的网段,这里指定的网段是10.100.0.0,因此service网络地址第一个分给了apiserver即10.100.0.1,第二个分给了coredns即10.100.0.2
更改完成后,保存文件进行coredns的部署3.2.6.2 部署coredns
kubectl apply -f coredns.yaml

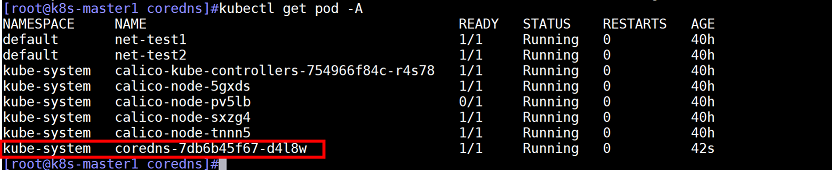
查看coredns容器状态
在容器内ping公网域名进行解析测试
DNS的高可用
由于DNS在k8s内部用于域名解析,一旦dns出现问题,那么k8s集群内容器之间的访问将会失败,因此为了保证dns的可用性,要对dns做高可用
1、DNS多副本
创建多个dns容器用于域名解析。这里通过更改coredns控制器yaml文件的方式增加dns的副本数
kubectl edit deployment coredns -n kube-system
spec:
progressDeadlineSeconds: 600
replicas: 2 #更改coredns的副本数
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kube-dns
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 1
type: RollingUpdate更改完成后保存会立即生效
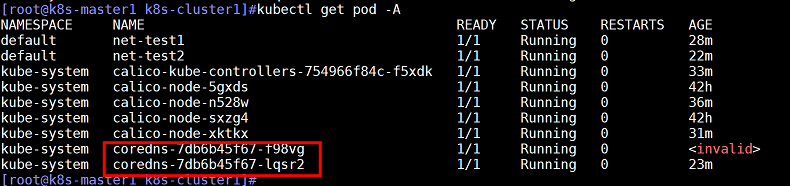
查看控制器,存在两个coredns

查看coredns的数量,存在两个coredns容器
2、增加资源
给dns容器配置足够多的资源,能够承载更多的访问量。如把DNS容器从1C2G升配到2C4G。
更改coredns yaml文件中的资源限制即可
containers:
- name: coredns
image: coredns/coredns:1.8.7
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 2
memory: 2Gi
requests:
cpu: 100m
memory: 70Mi3、开启DNS缓存
开启DNS缓存,命中缓存直接返回,不在需要DNS进行解析,降低DNS资源的使用率
(1)pod级别缓存:dnsmasq,部署时容器开启dns缓存,会将查询到的解析关系缓存到容器的dns缓存中,只对当前容器生效,对其他容器不生效,如果有多个容器,每个容器都需要开启dns缓存
(2)node级别缓存:localdns,部署时node节点开启dns缓存,会将查询到的解析关系缓存到node的dns缓存中,只对当前node生效,对其他node不生效,如果有多个node,每个node都需要开启dns缓存
vim /etc/kubeasz/clusters/k8s-cluster1/ config.yml
# coredns 自动安装
dns_install: "no" #部署时,此项更改为yes即可
corednsVer: "1.8.6"
ENABLE_LOCAL_DNS_CACHE: false #部署时,此项更改为yes即可
dnsNodeCacheVer: "1.21.1"
# 设置 local dns cache 地址
LOCAL_DNS_CACHE: "169.254.20.10"(3)coredns级别缓存:coredns开启缓存,全局生效
推荐在coredns上开启缓存,效果较好
小知识
(1)客户端域名解析时间过长:可以通过增加副本数,升级dns容器规格,开启coredns缓存解决
(2)dns缓存时间设置过长,如果集群内部容器变动较快,dns缓存时间过长会让域名解析关系无法及时更新,导致访问失败。
假如dns缓存时间为10分钟,某容器第一次被访问后,解析关系缓存到dns缓存中,在10分钟内该容器地址发生了变化,但dns缓存中保存的还是以前的地址,这就会造成访问失败。
K8S默认DNS:kubernetes和kube-dns

小知识
为什么安装coredns后,NAME显示的却是kube-dns

原因:其他依赖coredns组件的应用程序内写死了调用的是kube-dns,为了便于其他组件的调用,coredns的NAME没有改成coredns,仍为kube-dns
注意:如果源容器和目的容器不在同一个namespace,那么在源容器ping目的容器时需要加上目的容器所在的namespace才可以ping通
如下所示:net-test1的namespace是default,kube-dns的namespace是kube-system
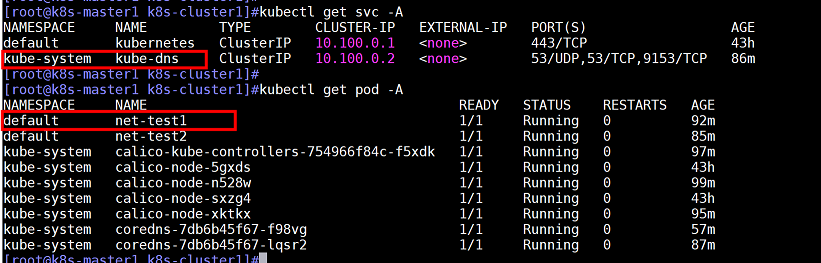
进入net-test1容器进行测试
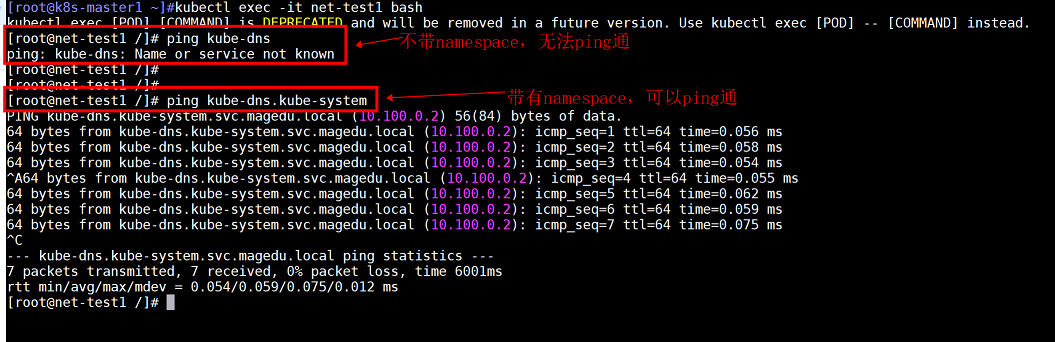
注意:kube-dns的域名完成格式为:name.namespace.svc.magedu.local
即:kube-dns.kube-system.svc.magedu.local

使用nslookup进行非交互式解析测试
yum -y install bind-utils #注意容器和宿主机都需要安装才可以使用nslookup命令
在宿主机进行域名解析测试

3.2.7 dashboard安装部署
3.2.7.1 在线安装dashboard
从github官网获取到dashboard的yaml文件,直接可以部署安装
dashboard yaml文件下载链接:https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yaml
下载yaml文件
cd /root/yaml
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yaml
下载完成后,为了便于区分,为该文件重命名
mv recommended.yaml dashboard-v2.5.1.yaml
通过yaml文件部署dashboard
kubectl apply -f dashboard-v2.5.1.yaml
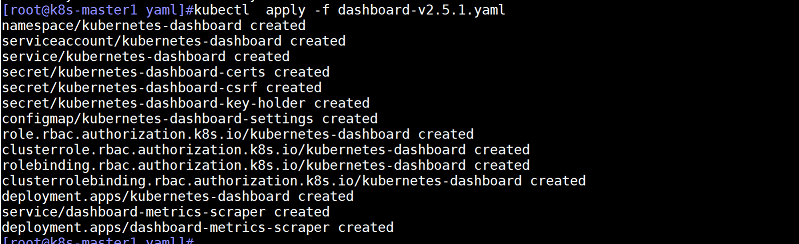
查看容器状态

3.2.7.2 基于本地镜像仓库拉取dashboard镜像部署dashboard
有些镜像仓库处于国外或者镜像较大,在线下载比较耗费时间,为了便于部署,可提前将镜像下载好并上传本地镜像仓库,部署时可直接从本地镜像仓库拉取镜像,比较省时
1、在三台node节点上本地/etc/hosts文件中配置harbor域名解析(红色字体部分),当在node节点拉起容器时,可以解析harbor镜像仓库域名,进而从harbor镜像仓库拉取镜像
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.31.7.104 harbor.magedu.local2、由于私有镜像仓库harbor是基于https部署的,因此要把harbor节点上创建的公钥分发给三个node节点,否则无法访问https协议的harbor镜像仓库
在三个node节点上创建存放证书的目录
mkdir -p /etc/docker/certs.d/harbor.magedu.local/ #注意/etc/docker/certs.d/目录下的harbor.magedu.local目录要以harbor域名命名,域名是什么,该目录就要命名为什么
3、在harbor(172.31.7.104)节点上把harbor-ca.cert证书传到三个node节点存放证书的目录下
scp /usr/local/src/harbor/certs/harbor-ca.crt 172.31.7.111:/etc/docker/certs.d/harbor.magedu.local/
scp /usr/local/src/harbor/certs/harbor-ca.crt 172.31.7.112:/etc/docker/certs.d/harbor.magedu.local/
scp /usr/local/src/harbor/certs/harbor-ca.crt 172.31.7.113:/etc/docker/certs.d/harbor.magedu.local/4、在master1节点上下载dashboard镜像并上传到harbor镜像仓库
下载镜像
docker pull kubernetesui/dashboard:v2.5.1
docker pull kubernetesui/metrics-scraper:v1.0.7更改镜像标签
docker tag kubernetesui/dashboard:v2.5.1 harbor.magedu.local/baseimages/dashboard:v2.5.1
docker tag kubernetesui/metrics-scraper:v1.0.7 harbor.magedu.local/baseimages/ metrics-scraper:v1.0.7把本地镜像上传到harbor镜像仓库
登录镜像仓库
docker login harbor.magedu.local
登录成功后(提示Login Succeeded表示登录成功),上传镜像到harbor镜像仓库
docker push harbor.magedu.local/baseimages/dashboard:v2.5.1
docker push harbor.magedu.local/baseimages/metrics-scraper:v1.0.7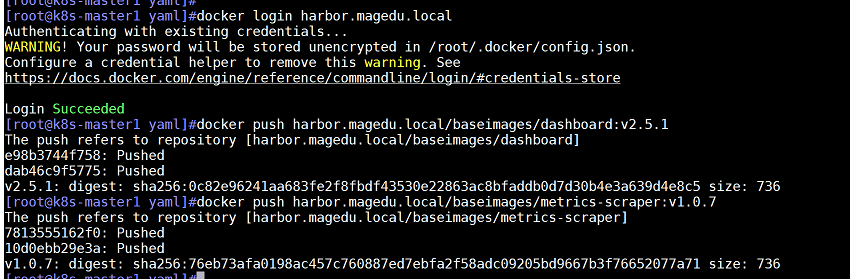
进入harbor镜像仓库网页查看镜像是否上传成功
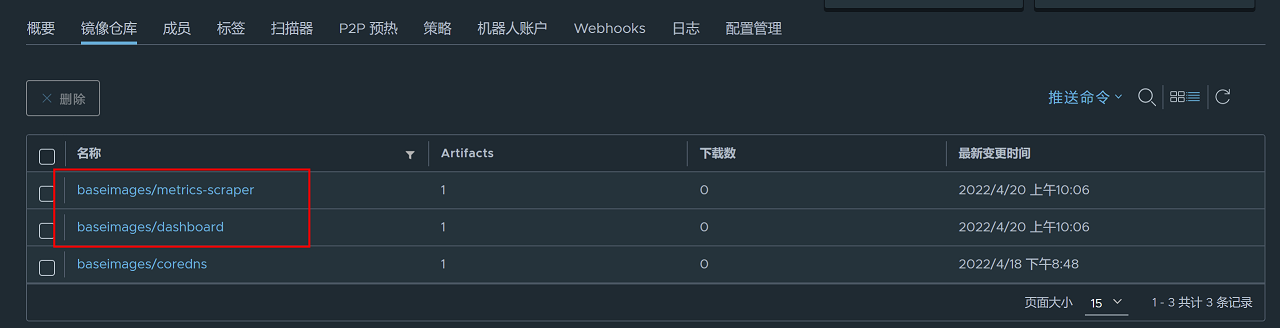
5、更改dashboard yaml文件中镜像的镜像仓库地址
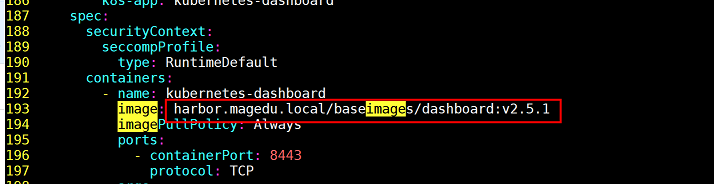
过滤/root/yaml/dashboard-v2.5.1.yaml文件关键字:kubernetesui/dashboard:v2.5.1,在yaml文件193行,把kubernetes-dashboard镜像地址更改为 harbor.magedu.local/baseimages/dashboard:v2.5.1
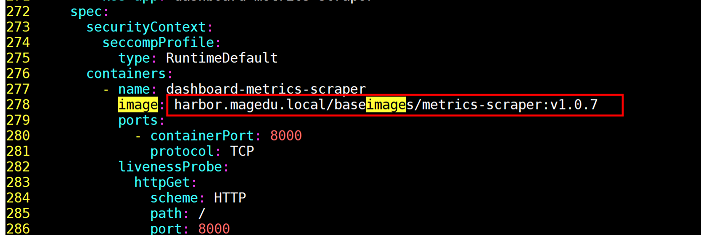
过滤/root/yaml/dashboard-v2.5.1.yaml文件关键字:kubernetesui/metrics-scraper:v1.0.7,在yaml文件278行,把dashboard-metrics-scraper镜像地址更改为harbor.magedu.local/baseimages/metrics-scraper:v1.0.7
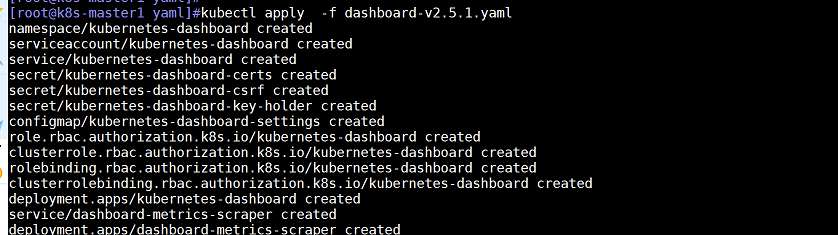
更改完成后,根据yaml文件部署dashboard,能够明显感觉dashboard容器在很短的时间内创建完成

3.2.7.3 通过token方式访问dashboard/
1、由于yaml文件中默认没有暴露外部端口,因此只能在内部访问,无法通过宿主机访问,要想通过宿主机访问,需要更改dashboard yaml文件,对外暴露端口(添加注释的内容为新增部分)
vim /root/yaml/dashboard-v2.5.1.yaml
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort #增加类型为暴露node端口
ports:
- port: 443
targetPort: 8443
nodePort: 30004 #设置暴露node端口号,注意:端口范围为30000-65000,该范围是在部署k8s集群是配置/etc/kubeasz/clusters/k8s-cluster1/hosts文件NODE_PORT_RANGE字段指定的,不能超出该范围
selector:
k8s-app: kubernetes-dashboard配置完成后,重新部署dashboard
kubectl apply -f /root/yaml/dashboard-v2.5.1.yaml

查看pod

查看svc,发现把容器443端口转换为宿主机的30004端口

注意:集群内每个node节点都会监听30004端口,这是由于集群内每个节点的kube-proxy都是从apiserver获取的iptables或ipvs规则,会把请求这个端口的请求转发给目标pod。
2、访问集群内任一节点的30004端口,这里以node1节点为例:即https://172.31.7.111:30004(注意要用https)
由于dashboard没有配置登录认证,因此需要自己进行手动配置
创建账号并授予账号管理员权限(根据yaml文件创建账号)
vim /root/yaml/admin-user.yaml
apiVersion: v1
kind: ServiceAccount #指定账号类型
metadata:
name: admin-user #指定账号名
namespace: kubernetes-dashboard #指定账号所在的namespace
#注意:账号创建后没有任何权限,需要绑定账号权限
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding #绑定权限,超级管理员
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole #把admin-user绑定ClusterRole,拥有超级管理员权限
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard根据yaml文件创建账号
kubectl apply -f /root/yaml/admin-user.yaml

3、账号创建之后没有用户名和密码,需要使用token登录。在账号创建之后,k8s会自动创建一个token,通过以下命令获取token:
(1)查询创建的账号后,K8S自动创建的token,这里只能看到token名称,看不到token具体内容
kubectl get secrets -n kubernetes-dashboard
或kubectl get secrets -A |grep admin


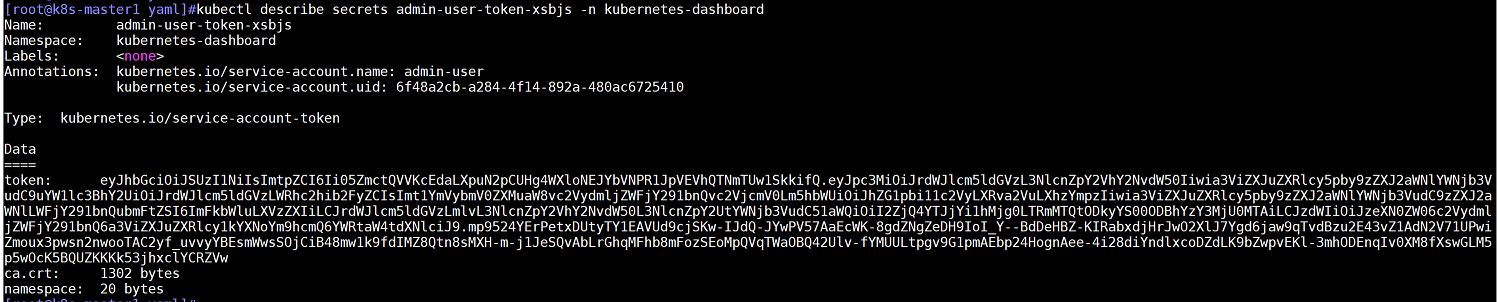
(2)获取token具体内容
注意:查询时要制定查询的资源类型为secrets和namespace为kubernetes-dashboard
kubectl describe secrets admin-user-token-xsbjs -n kubernetes-dashboard
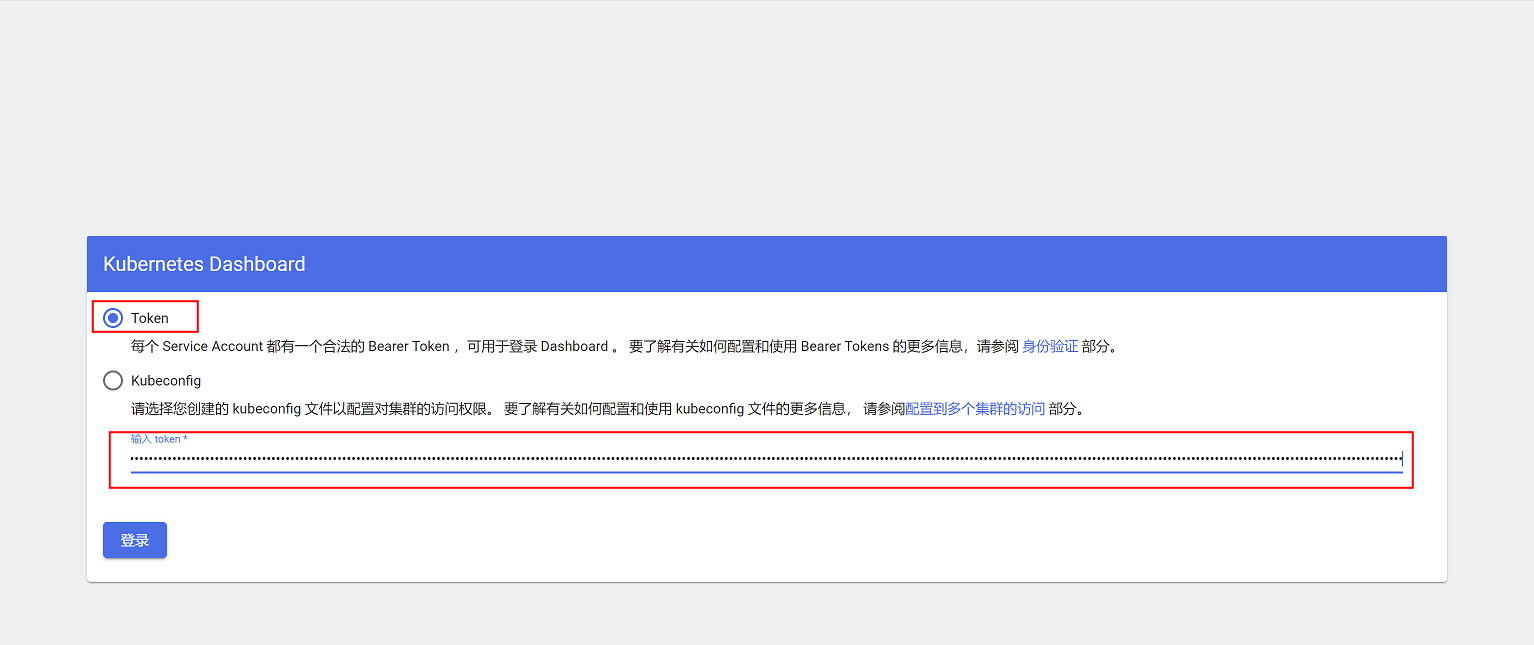
4、复制查询到的token,然后再dashboard登录页面输入token,即可登录
登录成功
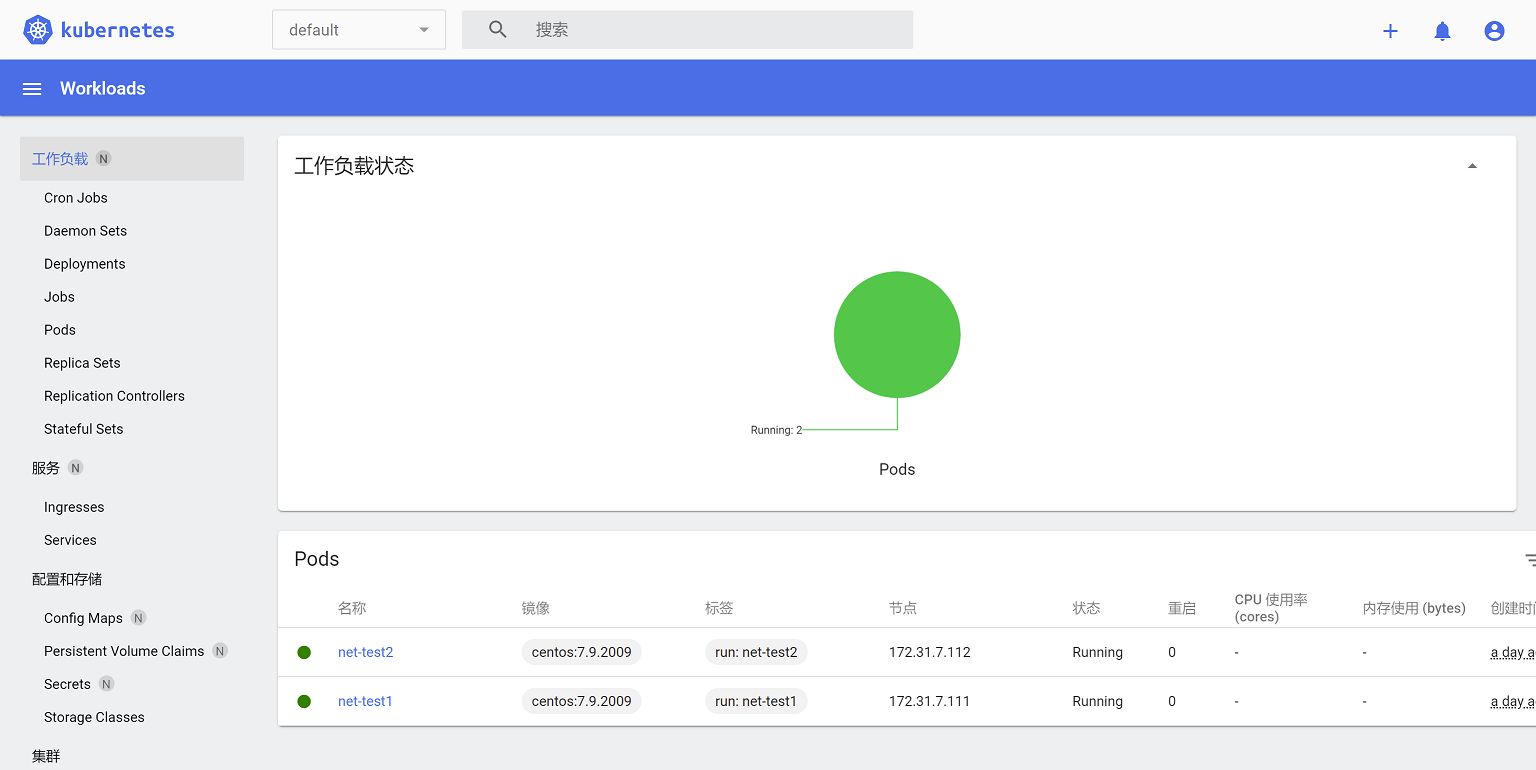
选择namespace,查看不同namespace下的资源状态
查看控制器:
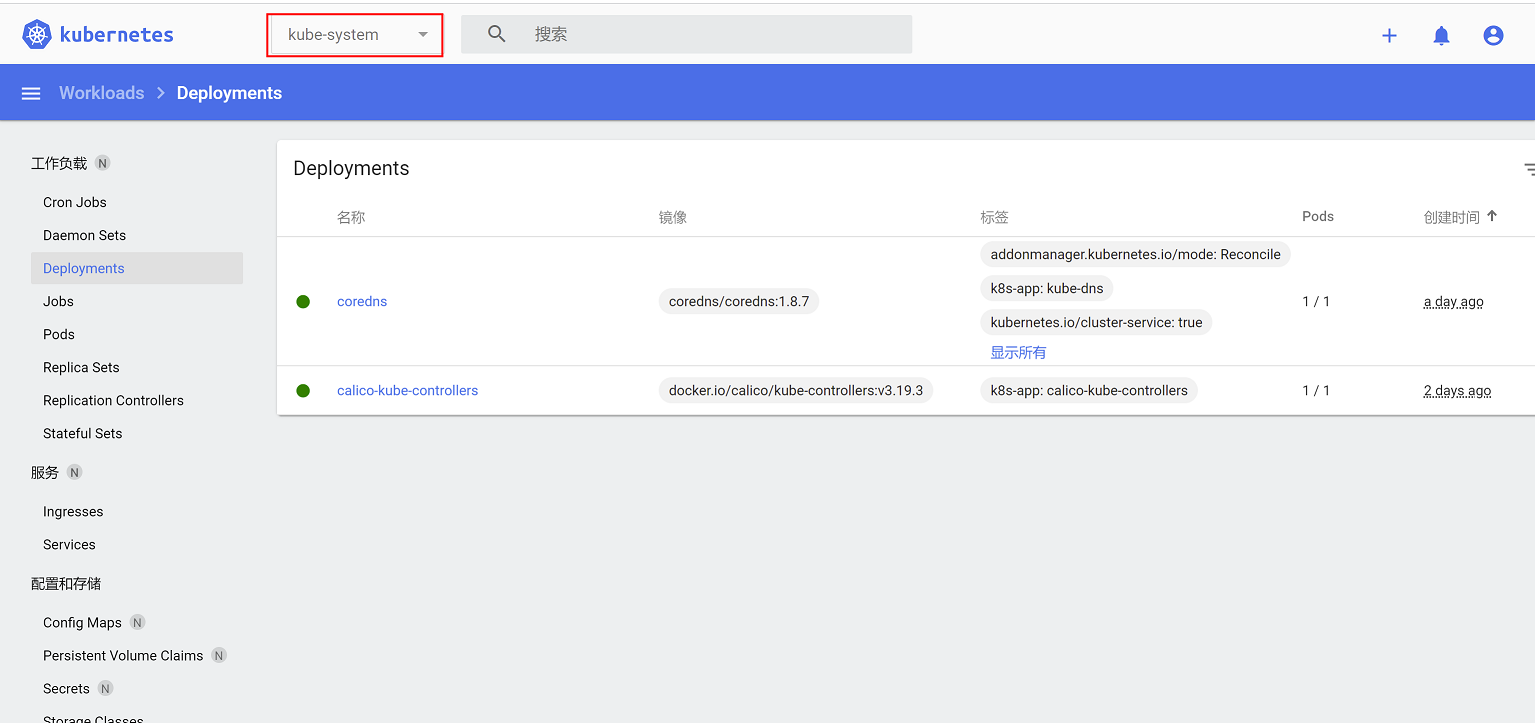
查看pod:
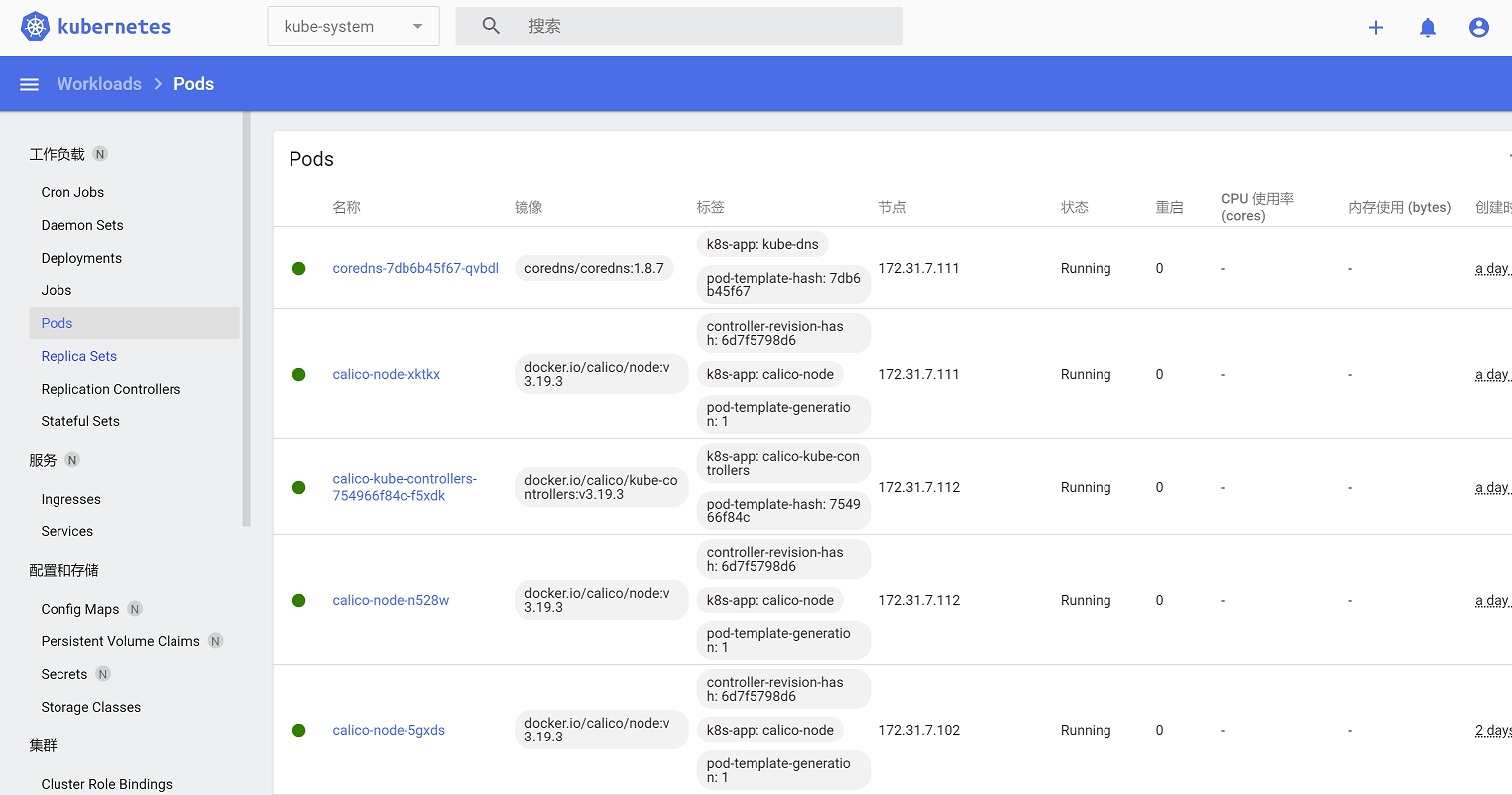
切换到default namespace,查看pod,有net-test1和net-test2,点击容器的三个点,选择执行
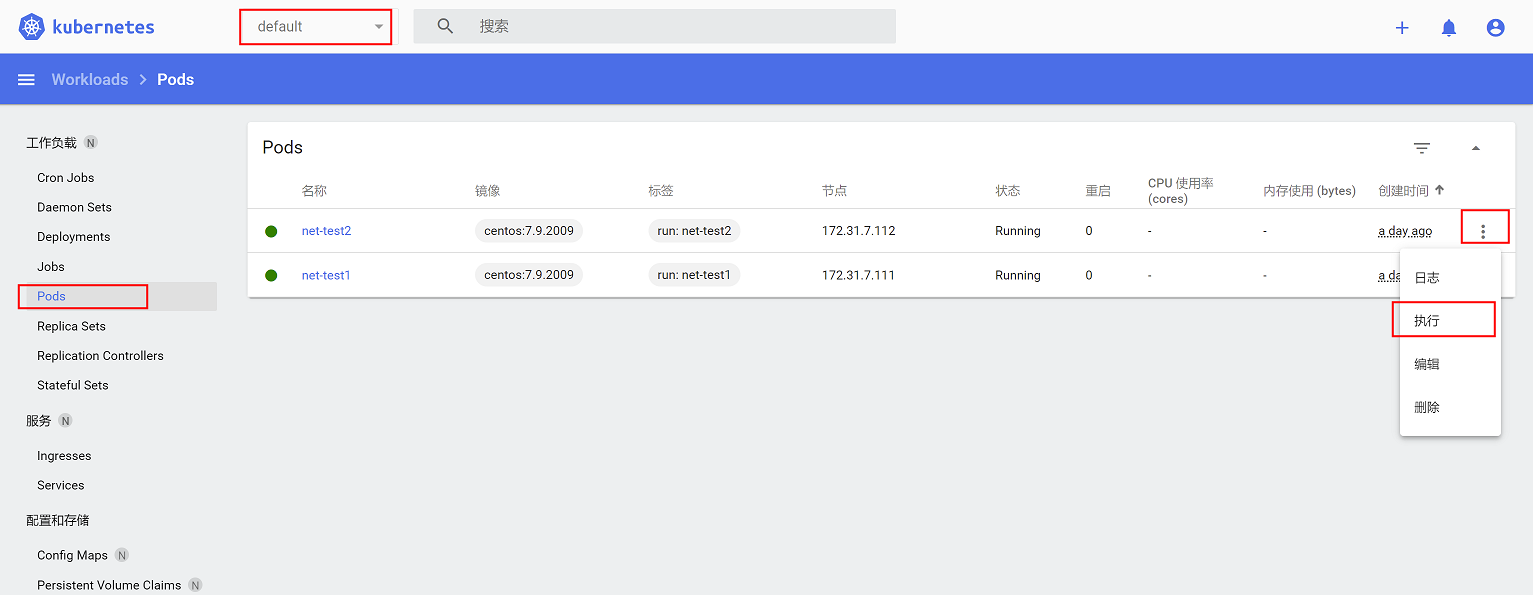
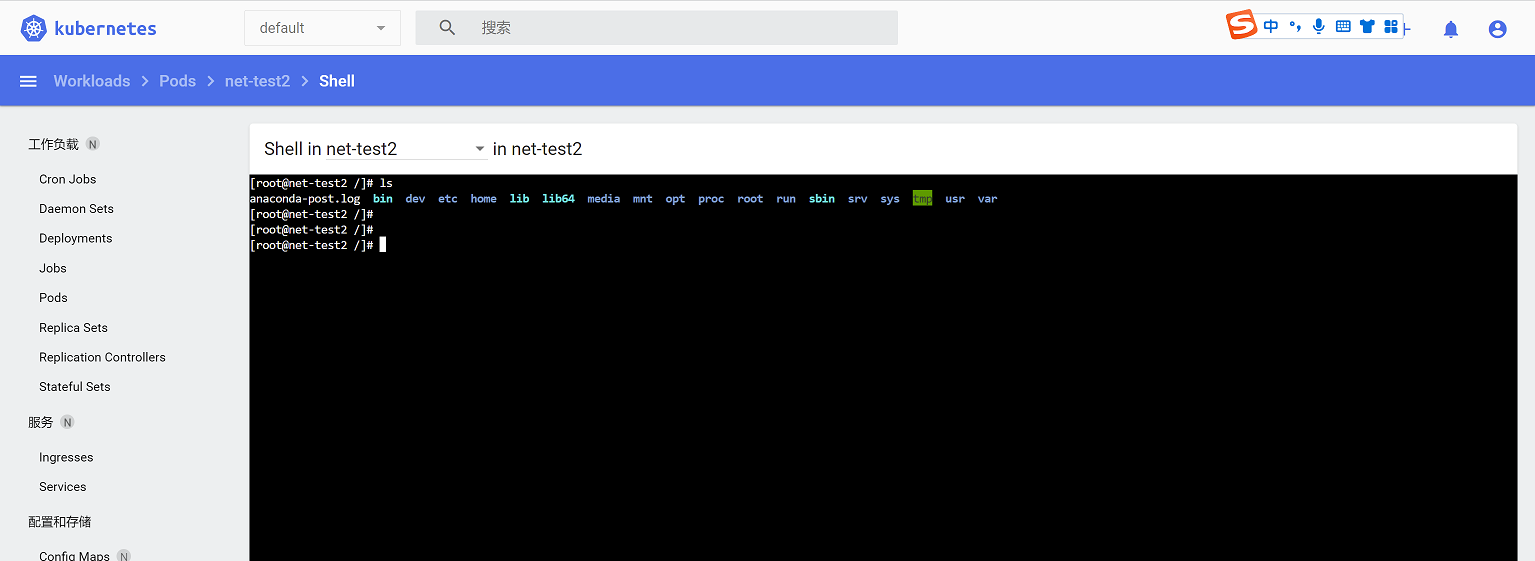
可以进入容器进行命令操作
3.3 K8S常用命令
查询集群资源
kubectl get #查询K8S集群内某资源的信息
k8s集群内常用资源包括:node(物理节点),pod(承载容器的最小单元),service(网络),deployment(控制器)等
kubectl get service --all-namespaces #查看所有名称空间下的service,这里的--all-namespace可以使用-A代替,即:kubectl get service -A
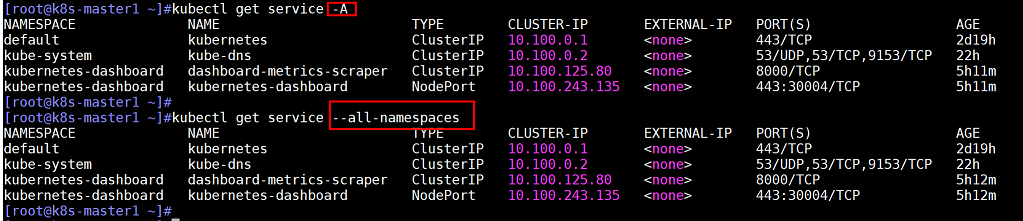
查看service命令输出结果各列内容说明
第一列NAMESPACE:是指名称空间,是指容器所在的namespace名称
第二列NAME:是指service简称,全称是:service名称.svc.namespace.k8s域名后缀,如:kubernetes.svc.default.magedu.local,每个namespace中service名称不会重复
第三列TYPE:是指service类型
第四列CLUSTER-IP:是指service集群内部地址
第五列EXTERNAL-IP:是指service集群外部地址
第六列PORTS:是指service监听的端口。
第七列AGE:是指service从创建到目前为止的时长kubectl get pods --all-namespaces
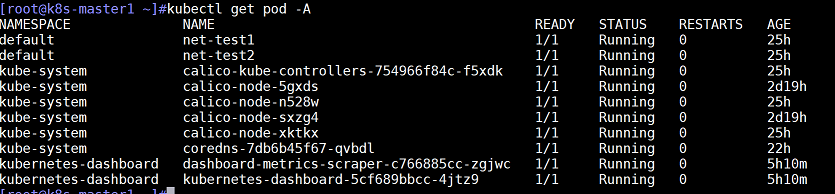
查看pods命令输出结果各列内容说明
第一列NAMESPACE:是指名称空间,是指容器所在的namespace名称
第二列NAME:是指容器名称,每个namespace中容器名称不会重复
第三列READY:是指容器是否就绪,1/1斜线右边的1是指pod中容器副本数,斜线左边的1是指已经就绪的容器数
第四列STATUS:是指容器的状态,目前为Running为运行状态
第五列RESTARTS:是指容器重启次数
第六列AGE:是指容器从创建到目前为止的时长。kubectl get nodes --all-namespaces

kubectl get deployment --all-namespaces #这里deployment可以写为deployment.apps或deploy
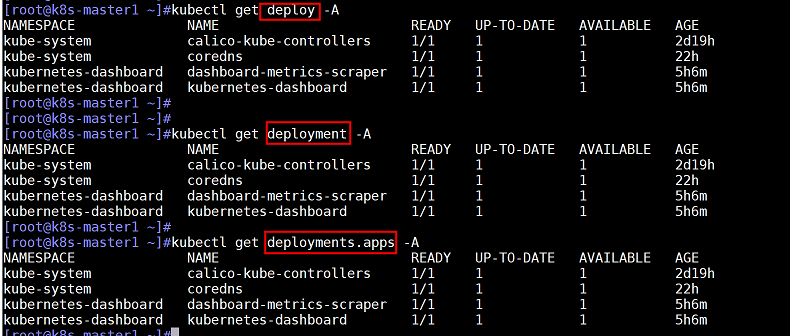
kubectl get deployment -A -o wide #更改显示格式,这里的-o wide是指以延展格式显示,能够显示更多的信息

查看资源详细信息
kubectl describe #查看某个资源详细信息
kubectl describe pods net-test1 -n default #如果在默认namespace(即default),可以不写
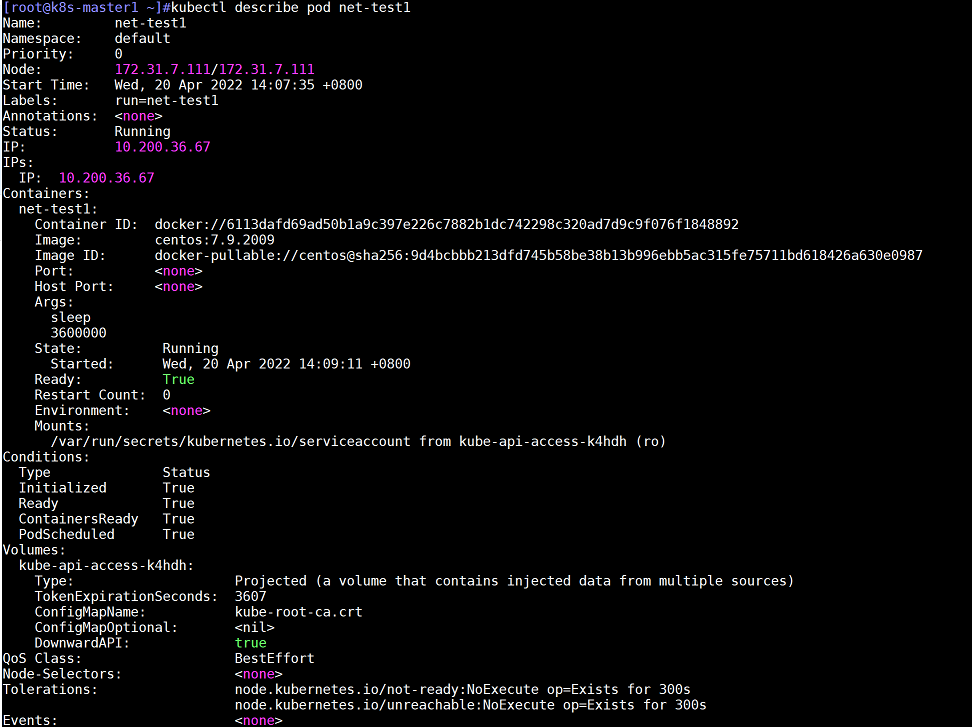
创建资源
kubectl create #根据yaml文件创建容器,不常用,推荐使用apply
kubectl create -f tomcat-app1.yaml
kubectl apply #根据yaml文件创建容器
kubectl apply -f tomcat-app1.yaml
删除资源
kubectl delete #删除pod
kubectl delete -f tomcat-app1.yaml #根据yaml文件删除pod,推荐使用这种删除方式
kubectl delete pods net-test1 -n default #直接删除pod,不推荐这种删除方式,因为如果pod根据yaml文件创建,可能会有其他依赖组件,删除不干净。
kubectl create和kubectl apply的区别:
使用kubectl create创建容器,如果容器yaml文件有变动,需要先删除创建的容器,再次使用kubectl create命令创建容器,变动的内容才可以加载到容器内
使用kubectl apply创建容器,如果容器yaml文件有变动,可直接使用kubectl apply命令指定对应yaml文件即可把变动的内容记载到容器内
apply命令机制:使用apply加载新的yaml文件时,k8s会先创建一个新的容器,容器创建完成后再删除旧的容器,因此服务不会受到影响执行命令
kubectl exec #在容器内执行命令
kubectl exec -it net-test1 bash -n default
注意:如果容器不在默认的namespace,进入容器时要加上容器所在namespace才可以进入
如果一个pod中存在多个容器,进入容器时需要使用-c参数指定某容器才可以进入
kubectl exec -it net-test1 -c container2 bash -n default #这里container2是指pod net-test1中第2个容器
查看日志
kubectl logs #查看容器日志
kubectl logs net-test1 -n default
kubectl logs -f #持续追踪容器日志,类似于tail -f
kubectl logs -f net-test1 -n default
kubectl logs -f --tail 10 net-test1 -n default #查看容器最后10行日志
kubectl explain #查看K8S资源yaml文件中的字段内容,由于yaml文件字段较多,不便于记忆,编写yaml时可用来参考查看yaml具体字段

文章评论