
MySQL高可用
- MMM: Multi-Master Replication Manager for MySQL,Mysql主主复制管理器是一套灵活的脚本程序,基于perl实现,用来对mysql replication进行监控和故障迁移,并能管理mysql Master-Master复制的配置(同一时间只有一个节点是可写的)
官网: http://www.mysql-mmm.org
https://code.google.com/archive/p/mysql-master-master/downloads - MHA: Master High Availability,对主节点进行监控,可实现自动故障转移至其它从节点;通过提升某一从节点为新的主节点,基于主从复制实现,还需要客户端配合实现,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,出于机器成本的考虑,淘宝进行了改造,目前淘宝TMHA已经支持一主一从
官网:https://code.google.com/archive/p/mysql-master-ha/ - Galera Cluster:wsrep(MySQL extended with the Write Set Replication)
通过wsrep协议在全局实现复制;任何一节点都可读写,不需要主从复制,实现多主读写
MHA集群架构
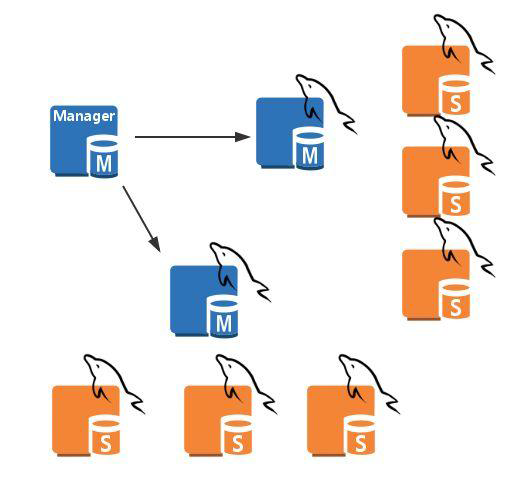
- MHA
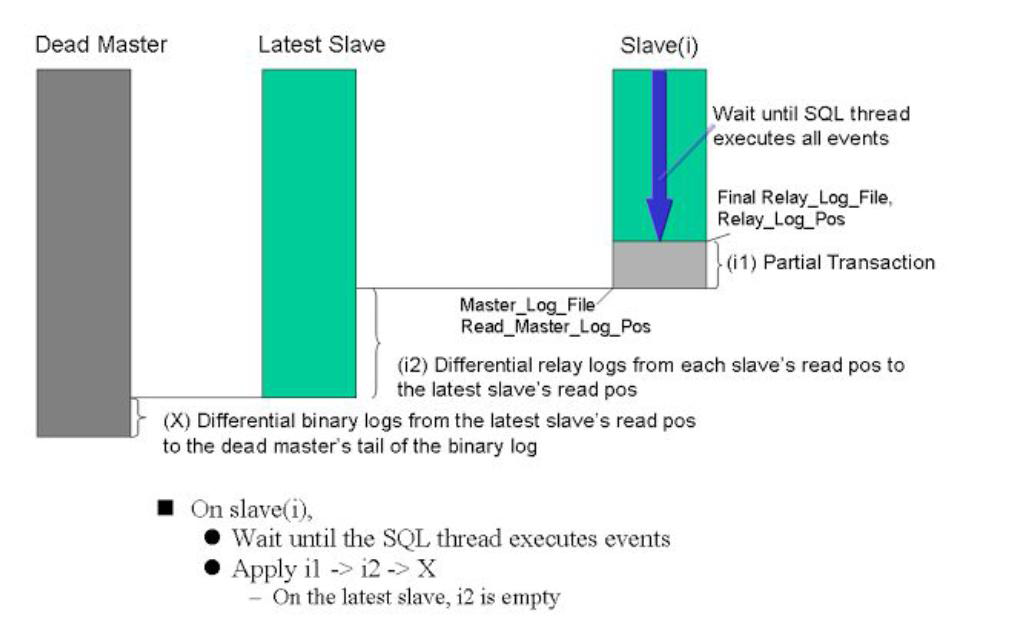
MHA工作原理
- MHA工作原理
1 从宕机崩溃的master保存二进制日志事件(binlog events)
2 识别含有最新更新的slave
3 应用差异的中继日志(relay log)到其他的slave
4 应用从master保存的二进制日志事件(binlog events)
5 提升一个slave为新的master
6 使其他的slave连接新的master进行复制
MHA
- MHA软件由两部分组成,Manager工具包和Node工具包
- Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 故障转移(自动或手动)
masterha_conf_host 添加或删除配置的server信息 - Node工具包:这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用此工具)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
注意:为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL 5.5的半同步复制 - 自定义扩展:
secondary_check_script: 通过多条网络路由检测master的可用性
master_ip_ailover_script: 更新Application使用的masterip
shutdown_script: 强制关闭master节点
report_script: 发送报告
init_conf_load_script: 加载初始配置参数
master_ip_online_change_script:更新master节点ip地址 - 配置文件:
global配置,为各application提供默认配置
application配置:为每个主从复制集群
实现MHA
- 在管理节点上安装两个包:
mha4mysql-manager
mha4mysql-node - 在被管理节点安装:
mha4mysql-node
注意:软件包需要在互联网下载
示例:
实验环境
需要四台机器:管理节点,一主两从
管理节点:192.168.32.203
master主机:192.168.32.200
slave01主机:192.168.32.201
slave02:192.168.32.202
初始化环境:
主从服务器停止mariadb服务,删除数据库,启动mariadb服务
关闭selinux,关闭iptables防火墙
时间必须同步
实现免密钥认证
在管理节点192.168.32.203上
生成密钥文件
ssh-keygen
接下来的选项直接确认即可,即连续按三下enter键
把密钥文件复制到本机
ssh-copy-id 192.168.32.203
查看生成的文件
cd .ssh
[root@ma .ssh]# ll
total 16
-rw------- 1 root root 389 Dec 25 20:48 authorized_keys
-rw------- 1 root root 1675 Dec 25 20:47 id_rsa
-rw-r--r-- 1 root root 389 Dec 25 20:47 id_rsa.pub
-rw-r--r--. 1 root root 352 Dec 25 20:48 known_hosts
把/root/.ssh文件复制给其他三个节点即可实现免密钥认证
scp -rp /root/.ssh 192.168.32.200:/root/
scp -rp /root/.ssh 192.168.32.201:/root/
scp -rp /root/.ssh 192.168.32.202:/root/
准备主从复制的配置文件
主服务器配置文件:
vim /etc/my.cnf
[mysqld]
server_id=1
innodb_file_per_table
log_bin
skip_name_resolve #注意:该选项必须添加,否则MHA可能会失败
重启mariadb服务
systemctl restart mariadb
创建复制账号
[root@master ~]# mysql
MariaDB [(none)]> grant replication slave on *.* to repluser@'192.168.32.%' identified by 'magedu';
创建管理账号
MariaDB [(none)]> grant all on *.* to mhauser@'192.168.32.%' identified by 'magedu';
从服务器192.168.32.201配置文件:
vim /etc/my.cnf
[mysqld]
server_id=2
innodb_file_per_table
log_bin #从节点有可能被提升为主节点,因此必须启用二进制日志
read_only #一旦从节点被提升为主节点,将会自动更改只读为可读写状态,因此该选项可以添加到从服务器配置文件中
relay_log_purge=0 #中继日志
skip_name_resolve
重启mariadb服务
systemctl restart mariadb
从服务器192.168.32.202配置文件:
vim /etc/my.cnf
[mysqld]
server_id=3
innodb_file_per_table
log_bin #从节点有可能被提升为主节点,因此必须启用二进制日志
read_only #一旦从节点被提升为主节点,将会自动更改只读为可读写状态,因此该选项可以添加到从服务器配置文件中
relay_log_purge=0 #中继日志
skip_name_resolve
重启mariadb服务
systemctl restart mariadb
实验主从复制
在从服务器192.168.32.201和192.168.32.202上进行以下配置:
[root@slave02 ssl]# mysql
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='repluser',
MASTER_PASSWORD='magedu',
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
#注意:主从复制要从初始点开始复制,要把创建的复制账号信息一并复制给从节点
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G
测试:能否实现主从同步
在主服务器上导入测试数据库
mysql < hellodb_innodb.sql
在从服务器查看导入主服务器的测试数据库是否同步到从服务器
配置MHA
在管理节点上需要安装manager软件包和node软件包
把下载的软件包复制到管理节点上
软件包名:
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56-0.el6.noarch.rpm
在管理节点192.168.32.203主机上
yum -y install mha4mysql-manager-0.56-0.el6.noarch.rpm mha4mysql-node-0.56-0.el6.noarch.rpm
注意:软件包的安装必须启用epel源,解决依赖关系
在被管理节点上需要安装node软件包
分别在192.168.32.200、192.168.32.201、192.168.32.202三台主机上安装node软件包
软件包名为:mha4mysql-node-0.56-0.el6.noarch.rpm
yum -y install mha4mysql-node-0.56-0.el6.noarch.rpm
创建MHA配置文件
在管理节点192.168.32.203上
mkdir /etc/mha
vim /etc/mastermha/app1.cnf
[server default] #管理节点默认配置
user=mhauser #管理主从集群的账号
password=magedu #管理账号的密码
manager_workdir=/data/mastermha/app1/ #管理节点工作目录
manager_log=/data/mastermha/app1/manager.log #管理节点日志,有助于排错
remote_workdir=/data/mastermha/app1/ #被管理节点工作目录
ssh_user=root #远程ssh连接用户身份
repl_user=repluser #远程复制账号
repl_password=magedu #远程复制账号的密码
ping_interval=1 #监控被管理节点状态,一秒钟探测一次,如果发现故障就提升从服务器为新的主服务器
#以下为被管理的三个节点
[server1] #被管理节点
hostname=192.168.32.200
candidate_master=1 #有资格充当master的从服务器
[server2] #被管理节点
hostname=192.168.32.201
candidate_master=1 #有资格充当master的从服务器
[server3] #被管理节点
hostname=192.168.32.202
使用脚本进行MHA验证和启动
masterha_check_ssh --conf=/etc/mha/app1.conf #验证ssh连接
masterha_check_repl --conf=/etc/mha/app1.conf #验证复制账号连接
masterha_manager --conf=/etc/mastermha/app1.cnf #启用MHA
注意:该启动脚本以前台方式启动,如果中断关闭则MHA将会关闭,可以使用screen或nohup确保连接不能中断
测试:验证MHA是否成功启用
模拟主节点出现故障:
1.主节点服务器数据库服务出现故障
2.主节点物理服务器出现故障宕机
在主节点192.168.32.200主机上
强制关闭mysql服务,查看是否启用从服务器为新的主节点
killall mysqld
在管理节点192.168.32.203上
MHA前台进程自动关闭,该进程是一次性任务,完成任务就会结束,如果想要使用MHA,需要再次启动
查看日志
tail -50 /data/mastermha/app1/manager.log
----- Failover Report -----
app1: MySQL Master failover 192.168.32.200(192.168.32.200:3306) to 192.168.32.201(192.168.32.201:3306) succeeded
Master 192.168.32.200(192.168.32.200:3306) is down!
Check MHA Manager logs at ma:/data/mastermha/app1/manager.log for details.
Started automated(non-interactive) failover.
The latest slave 192.168.32.201(192.168.32.201:3306) has all relay logs for recovery.
Selected 192.168.32.201(192.168.32.201:3306) as a new master.
192.168.32.201(192.168.32.201:3306): OK: Applying all logs succeeded.
192.168.32.202(192.168.32.202:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.32.202(192.168.32.202:3306): OK: Applying all logs succeeded. Slave started, replicating from 192.168.32.201(192.168.32.201:3306)
192.168.32.201(192.168.32.201:3306): Resetting slave info succeeded.
Master failover to 192.168.32.201(192.168.32.201:3306) completed successfully.
从日志可以看出192.168.32.201称为新的主服务器,而从服务器192.168.32.202也指向新的主服务器192.168.32.201
在从服务器192.168.32.202验证
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.32.201
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000001
Read_Master_Log_Pos: 245
Relay_Log_File: mariadb-relay-bin.000002
Relay_Log_Pos: 531
Relay_Master_Log_File: mariadb-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 245
Relay_Log_Space: 827
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
在配置文件中,从服务器设置为read_only只读状态,现在查看新的主服务器是否为只读状态
MariaDB [none]> show variables like 'read_only';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+
可以发现,read_only只读状态自动被关闭
注意:此时要把配置文件中的read_only选项删除,更改后无需重启服务
在新的主服务器192.168.32.201上插入数据查看能否同步
MariaDB [(none)]> use hellodb
MariaDB [hellodb]> insert teachers values(6,'b',30,'M');
在从服务器192.168.32.202上查看信息是否同步
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 30 | F |
| 6 | b | 30 | M |
+-----+---------------+-----+--------+Galera Cluster
- Galera Cluster:集成了Galera插件的MySQL集群,是一种新型的,数据不共享的,高度冗余的高可用方案,目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster,Galera本身是具有多主特性的,即采用multi-master的集群架构,是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案
- 下图图示:三个节点组成了一个集群,与普通的主从架构不同,它们都可以作为主节点,三个节点是对等的,称为multi-master架构,当有客户端要写入或者读取数据时,连接哪个实例都是一样的,读到的数据是相同的,写入某一个节点之后,集群自己会将新数据同步到其它节点上面,这种架构不共享任何数据,是一种高冗余架构
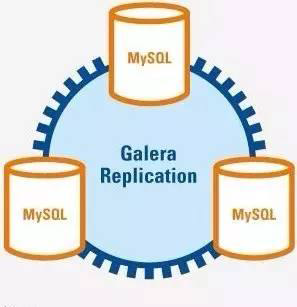
-
Galera Cluster特点
多主架构:真正的多点读写的集群,在任何时候读写数据,都是最新的
同步复制:集群不同节点之间数据同步,没有延迟,在数据库挂掉之后,数据不会丢失
并发复制:从节点APPLY数据时,支持并行执行,更好的性能
故障切换:在出现数据库故障时,因支持多点写入,切换容易
热插拔:在服务期间,如果数据库挂了,只要监控程序发现的够快,不可服务时间就会非常少。在节点故障期间,节点本身对集群的影响非常小
自动节点克隆:在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,Galera Cluster会自动拉取在线节点数据,最终集群会变为一致
对应用透明:集群的维护,对应用程序是透明的 -
Galera Cluster工作过程
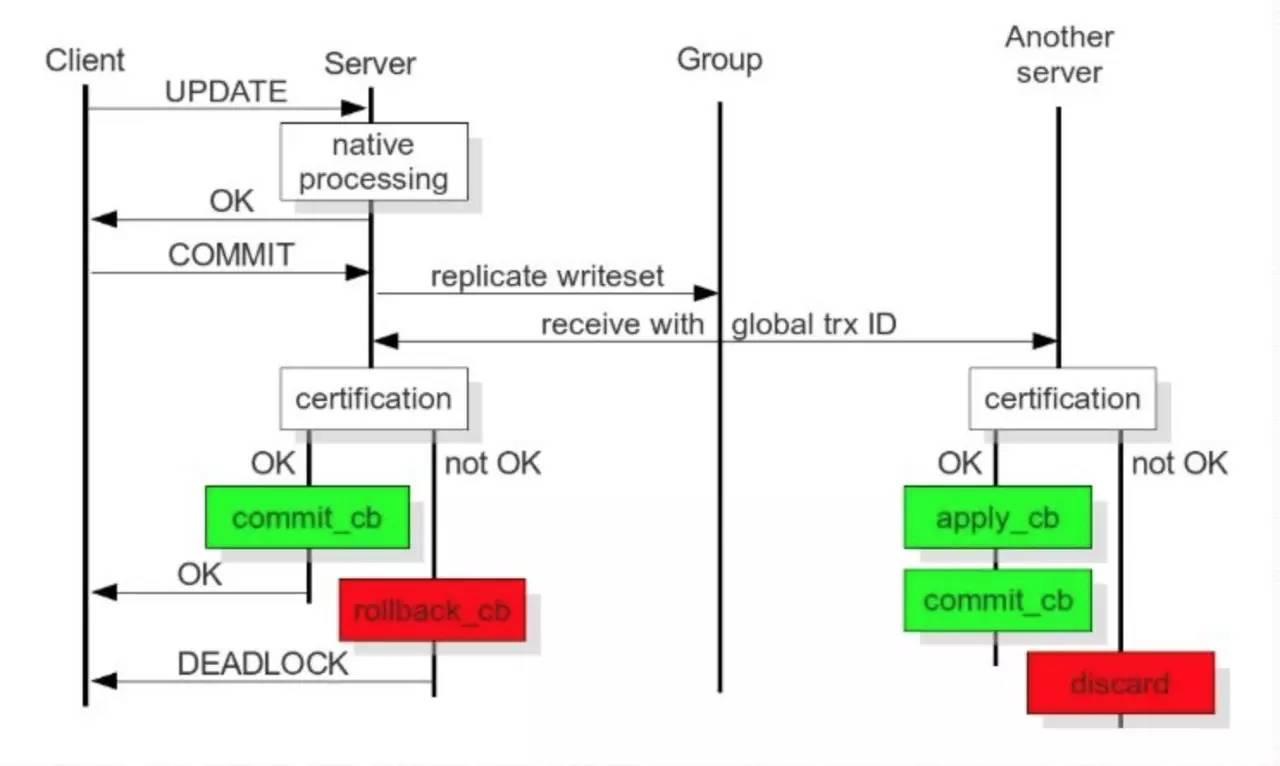
- Galera Cluster官方文档:
http://galeracluster.com/documentation-webpages/galera-documentation.pdf
http://galeracluster.com/documentation-webpages/index.html
https://mariadb.com/kb/en/mariadb/getting-started-with-mariadb-galera-cluster/ - Galera Cluster包括两个组件
Galera replication library (galera-3)
WSREP:MySQL extended with the Write Set Replication - WSREP复制实现:
percona-cluster
MariaDB-Cluster
注意:都至少需要三个节点,不能安装mariadb-server
Galera Cluster实现
示例:
实验环境
master01主机:192.168.32.200
master02主机:192.168.32.201
master03主机:192.168.32.202
配置Galera Cluster:
分别在三台主机上安装软件包MariaDB-Galera-server
配置yum仓库如下:
vim /etc/yum.repos.d/mysql.repo
[mysql]
name=Galera-Cluster.repo
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-5.5.62/yum/centos7-amd64/
gpgcheck=0
安装软件包:
yum -y install MariaDB-Galera-server #注意大小写
在master01主机192.168.32.200上
vim /etc/my.cnf.d/server.cnf
[galera]
# Mandatory settings
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address="gcomm://192.168.32.200,192.168.32.201,192.168.32.202"
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
配置完成后,把配置文件复制到另外两台主机上
scp /etc/my.cnf.d/server.cnf 192.168.32.201:/etc/my.cnf.d/
scp /etc/my.cnf.d/server.cnf 192.168.32.202:/etc/my.cnf.d/
首次启动时,需要初始化集群,在其中一个节点上执行命令
/etc/init.d/mysql start --wsrep-new-cluster
而后正常启动其它节点
service mysql start
查看集群中相关系统变量和状态变量
SHOW VARIABLES LIKE 'wsrep_%';
SHOW STATUS LIKE 'wsrep_%';
SHOW STATUS LIKE 'wsrep_cluster_size';
测试:查看集群能否同步
在master01上导入测试数据库
mysql < hellodb_innodb.sql #导入hellodb数据库
在其他节点上查看能否自动同步
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hellodb |
| mysql |
| performance_schema |
| test |
+--------------------+
测试:主主模型,在加入数据时,会出现id号冲突现象,现在在两个节点同时加入数据查看是否能够解决冲突问题
在SecureCRT上同时向三个终端窗口发送插入数据的命令
MariaDB [(none)]> use hellodb
MariaDB [hellodb]> insert teachers(name,age,gender)values('a',30,'M');
查看结果,发现自动解决冲突问题
MariaDB [hellodb]> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 6 | a | 30 | M |
| 7 | a | 30 | M |
| 8 | a | 30 | M |
+-----+---------------+-----+--------+复制的问题和解决方案
- 复制的问题和解决方案:
(1) 数据损坏或丢失
Master: MHA + semi repl,即MHA加半同步复制
Slave: 重新复制
(2) 混合使用存储引擎,MyISAM即将淘汰,不推荐使用
MyISAM:不支持事务
InnoDB: 支持事务
(3) 不惟一的server id
重新复制
(4) 复制延迟
需要额外的监控工具的辅助
一从多主:mariadb10版后支持
多线程复制:对多个数据库复制
性能衡量指标
- 数据库服务衡量指标:
qps: query per second
tps: transaction per second - 压力测试工具:
mysqlslap
Sysbench:功能强大
https://github.com/akopytov/sysbench
tpcc-mysql
MySQL Benchmark Suite
MySQL super-smack
MyBench
MySQL压力测试
- Mysqlslap:来自于mariadb包,测试的过程默认生成一个mysqlslap的schema,生成测试表t1,查询和插入测试数据,mysqlslap库自动生成,如果已经存在则先删除。用--only-print来打印实际的测试过程,整个测试完成后不会在数据库中留下痕迹
- 使用格式:mysqlslap [options]
- 常用参数 [options] 说明:
--auto-generate-sql, -a 自动生成测试表和数据,表示用mysqlslap工具自己生成的SQL脚本来测试并发压力
--auto-generate-sql-load-type=type 测试语句的类型。代表要测试的环境是读操作还是写操作还是两者混合的。取值包括:read,key,write,update和mixed(默认)
--auto-generate-sql-add-auto-increment 代表对生成的表自动添加auto_increment列,从5.1.18版本开始支持
--number-char-cols=N, -x N 自动生成的测试表中包含多少个字符类型的列,默认1
--number-int-cols=N, -y N 自动生成的测试表中包含多少个数字类型的列,默认1
--number-of-queries=N 总的测试查询次数(并发客户数×每客户查询次数)
--query=name,-q 使用自定义脚本执行测试,例如可以调用自定义的存储过程或者sql语句来执行测试
--create-schema 代表自定义的测试库名称,测试的schema
--commint=N 多少条DML后提交一次
--compress, -C 如服务器和客户端都支持压缩,则压缩信息
--concurrency=N, -c N 表示并发量,即模拟多少个客户端同时执行select。可指定多个值,以逗号或者--delimiter参数指定值做为分隔符如:--concurrency=100,200,500
--engine=engine_name, -e engine_name 代表要测试的引擎,可以有多个,用分隔符隔开。例如:--engines=myisam,innodb
--iterations=N, -i N 测试执行的迭代次数,代表要在不同并发环境下,各自运行测试多少次
--only-print 只打印测试语句而不实际执行。
--detach=N 执行N条语句后断开重连
--debug-info, -T 打印内存和CPU的相关信息
mysqlslap示例:
单线程测试
mysqlslap -a -uroot -pmagedu
多线程测试。使用–concurrency来模拟并发连接
mysqlslap -a -c 100 -uroot -pmagedu
迭代测试。用于需要多次执行测试得到平均值
mysqlslap -a -i 10 -uroot -pmagedu
mysqlslap ---auto-generate-sql-add-autoincrement -a
mysqlslap -a --auto-generate-sql-load-type=read
mysqlslap -a --auto-generate-secondary-indexes=3
mysqlslap -a --auto-generate-sql-write-number=1000
mysqlslap --create-schema world -q "select count(*) from City”
mysqlslap -a -e innodb -uroot -pmagedu
mysqlslap -a --number-of-queries=10 -uroot -pmagedu
测试同时不同的存储引擎的性能进行对比
mysqlslap -a --concurrency=50,100 --number-of-queries 1000 --iterations=5 --engine=myisam,innodb --debug-info -uroot -pmagedu
执行一次测试,分别50和100个并发,执行1000次总查询
mysqlslap -a --concurrency=50,100 --number-of-queries 1000 --debug-info -uroot -pmagedu
50和100个并发分别得到一次测试结果(Benchmark),并发数越多,执行完所有查询的时间越长。为了准确起见,可以多迭代测试几次
mysqlslap -a --concurrency=50,100 --number-of-queries 1000 --iterations=5 --debug-info -uroot -pmagedu生产环境my.cnf配置示例:
硬件:内存32G
innodb_file_per_table = 1
打开独立表空间
max_connections = 8000
#MySQL 服务所允许的同时会话数的上限,经常出现Too Many Connections的错误提示,则需要增大此值
back_log = 300
#back_log 是操作系统在监听队列中所能保持的连接数
max_connect_errors = 1000
#每个客户端连接最大的错误允许数量,当超过该次数,MYSQL服务器将禁止此主机的连接请求,直到MYSQL服务器重启或通过flush hosts命令清空此主机的相关信息
open_files_limit = 10240
#所有线程所打开表的数量
max_allowed_packet = 32M
#每个连接传输数据大小.最大1G,须是1024的倍数,一般设为最大的BLOB的值
wait_timeout = 10
#指定一个请求的最大连接时间
sort_buffer_size = 16M
# 排序缓冲被用来处理类似ORDER BY以及GROUP BY队列所引起的排序
join_buffer_size = 16M
#不带索引的全表扫描.使用的buffer的最小值
query_cache_size = 128M
#查询缓冲大小
query_cache_limit = 4M
#指定单个查询能够使用的缓冲区大小,缺省为1M
transaction_isolation = REPEATABLE-READ
# 设定默认的事务隔离级别
thread_stack = 512K
# 线程使用的堆大小. 此值限制内存中能处理的存储过程的递归深度和SQL语句复杂性,此容量的内存在每次连接时被预留.
log-bin
# 二进制日志功能
binlog_format=row
#二进制日志格式
innodb_buffer_pool_size = 24G
#InnoDB使用一个缓冲池来保存索引和原始数据, 可设置这个变量到服务器物理内存大小的80%
innodb_file_io_threads = 4
#用来同步IO操作的IO线程的数量
innodb_thread_concurrency = 16
#在InnoDb核心内的允许线程数量,建议的设置是CPU数量加上磁盘数量的两倍
innodb_log_buffer_size = 16M
# 用来缓冲日志数据的缓冲区的大小
innodb_log_file_size = 512M
在日志组中每个日志文件的大小
innodb_log_files_in_group = 3
# 在日志组中的文件总数
innodb_lock_wait_timeout = 120
# SQL语句在被回滚前,InnoDB事务等待InnoDB行锁的时间
long_query_time = 2
#慢查询时长
log-queries-not-using-indexes
#将没有使用索引的查询也记录下来MySQL配置最佳实践
- 高并发大数据的互联网业务,架构设计思路是“解放数据库CPU,将计算转移到服务层”,并发量大的情况下,这些功能很可能将数据库拖死,业务逻辑放到服务层具备更好的扩展性,能够轻易实现“增机器就加性能”
- 参考:
阿里巴巴Java开发手册
58到家数据库30条军规解读
http://zhuanlan.51cto.com/art/201702/531364.html

文章评论