
本章概述
- 日志收集准备工作-部署ELK
- 日志收集方式
前言
日志收集的目的:
分布式日志数据统一收集,实现集中式查询和管理
故障排查
安全信息和事件管理
报表功能
日志收集的价值:
日志查询,问题排查,故障恢复,故障自愈
应用日志分析,错误报警
性能分析,用户行为分析
日志收集流程图:
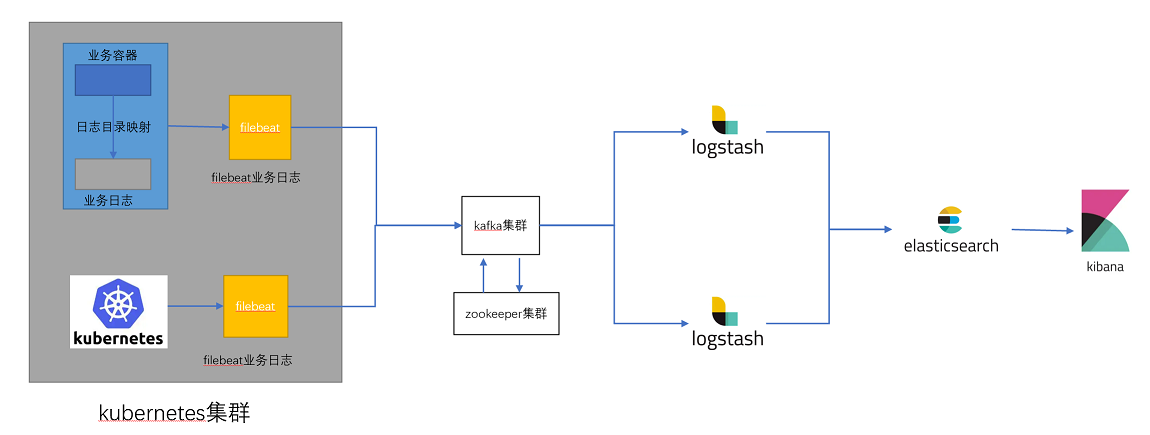
日志收集流程
1、在k8s集群内部(node、pod、容器)内置filebeat客户端收集日志(日志主要为业务access日志和kubernetes集群的系统日志)
2、日志发送给kafka集群,kafka集群进行缓存(削峰填谷)
注意:在业务高峰期,k8s集群会产生大量日志,如果日志直接发送给logstash,会占用logstash大量磁盘IO,负载很高,如果logstash无法及时处理,就会产生阻塞造成数据丢失。为了防止此类问题,在中间加上kafka缓存,消息先缓存在kafka中,由kafka投递给logstash进行处理。
3、logstash从kafka消费日志,并对日志进行过滤
4、然后将日志发送给elasticsearch,elasticsearch对日志进行分析
5、kibana用来展示elasticsearch的分析结果
15.1 日志收集准备工作-部署ELK
由于日志收集是基于ELK架构进行的,要先部署ELK,部署完成后,便于演示通过不同的日志收集方式实现kubernetes日志收集
机器准备:
kafka1 172.31.7.161
kafka2 172.31.7.162
kafka3 172.31.7.163
zookeeper1 172.31.7.171
zookeeper2 172.31.7.172
zookeeper3 172.31.7.173
elasticsearch01 172.31.7.181
elasticsearch02 172.31.7.182
elasticsearch03 172.31.7.183
kibana 172.31.7.181 (和elasticsearch01共用一台机器)
logstash 172.31.7.18515.1.1 部署zookeeper
1、zookeeper三个节点执行:yum安装jdk
yum -y install java-1.8.0-openjdk
验证java是否可用
java -version

2、三个zookeeper节点执行:创建目录/apps,并将zookeeper安装存放在该目录下
mkdir -p /apps
将zookeeper安装放在该目录下
cd /apps
wget https://downloads.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
3、三个zookeeper节点执行:解压安装包并做软链接
tar xvf apache-zookeeper-3.6.3-bin.tar.gz
ln -sv /apps/apache-zookeeper-3.6.3-bin /apps/zookeeper
4、修改zookeeper配置
在三zookeeper个节点分别执行:
cd /apps/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=172.31.7.171:2888:3888
server.2=172.31.7.172:2888:3888
server.3=172.31.7.173:2888:3888创建数据目录
mkdir -p /data/zookeeper
5、配置zookeeper节点id(注意,zookeeper集群每个节点的id都不一样)
在zookeeper1节点172.31.7.171上执行:
echo 1 > /data/zookeeper/myid
在zookeeper2节点172.31.7.172上执行:
echo 2 > /data/zookeeper/myid
在zookeeper3节点172.31.7.173上执行:
echo 3 > /data/zookeeper/myid6、运行zookeeper集群
三个节点分别执行:
/apps/zookeeper/bin/zkServer.sh start
注意:zookeeper配置的初始化时间为10*2000ms,即20s,因此三个节点服务拉起时间不能超过20s,超过20s将会集群初始化失败
查看集群各节点角色
/apps/zookeeper/bin/zkServer.sh status #当前集群zookeeper3为leader角色。7、使用插件在windows主机上进行验证
(1)首先在windows主机安装java环境
java下载链接:https://download.oracle.com/java/18/latest/jdk-18_windows-x64_bin.exe
(2)安装完成后使用ZooInspector工具连接zookeeper
ZooInspector百度网盘下载链接:
链接:https://pan.baidu.com/s/1m8v0Ni9Fql1n_Y19vVKXsg
提取码:lh7t 下载完成后进行解压,然后进入build文件夹,双击打开zookeeper-dev-ZooInspector.jar(注意使用java打开该工具)
点击工具栏第一个按钮(如果第一次打开不显示工具栏,需要关闭,然后重新打开)

连接zookeeper
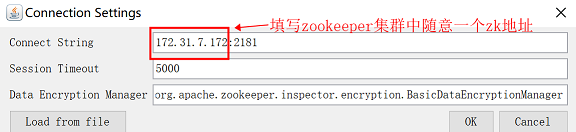
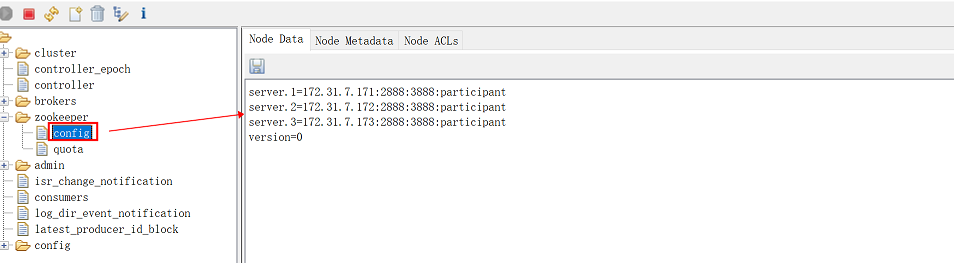
如果左侧能显示zookeeper,并且在其子列表中点击config,右侧可以显示zookeeper集群各节点地址,说明zookeeper正常
15.1.2 部署kafka
1、kafka三个节点分别执行:安装java并下载kafka安装包
yum -y install java-1.8.0-openjdk
创建目录
mkdir -p /apps
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.13-2.4.1.tgz
2、kafka三个节点分别执行:解压安装包并做软连接
tar xvf kafka_2.13-2.4.1.tgz
ln -sv /apps/kafka_2.13-2.4.1 /apps/kafka3、修改kafka配置文件(注意三个kafka节点配置不同,要分别进行配置)
(1)kafka1节点172.31.7.161配置:
cd /apps/kafka/config
vim server.properties
broker.id=161 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://172.31.7.161:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=172.31.7.171:2181,172.31.7.172:2181,172.31.7.173:2181 #指定zk地址和端口
创建日志目录
mkdir -p /data/kafka-logs
(2)kafka2节点172.31.7.162配置:
cd /apps/kafka/config
vim server.properties
broker.id=162 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://172.31.7.162:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=172.31.7.171:2181,172.31.7.172:2181,172.31.7.173:2181 #指定zk地址和端口
创建日志目录
mkdir -p /data/kafka-logs
(3)kafka3节点172.31.7.163配置:
cd /apps/kafka/config
vim server.properties
broker.id=163 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://172.31.7.163:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定kafka存储数据的目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=172.31.7.171:2181,172.31.7.172:2181,172.31.7.173:2181 #指定zk地址和端口创建日志目录
mkdir -p /data/kafka-logs
4、启动kafka
(1)三个节点分别执行:
/apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties
注意:如果多台机器是通过克隆同一个快照创建的,注意要更改主机名称,否则会报以下错误(日志为/app/zookeerper/logs/kafkaServer.out)
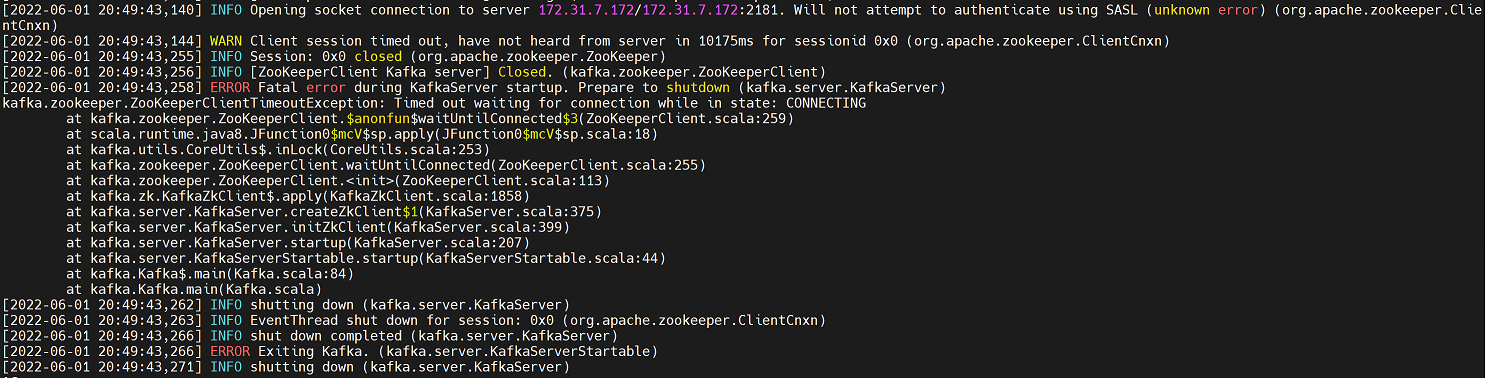
解决方法:修改主机名
hostnamectl set-hostname XXX #通过命令更改,临时生效
vim /etc/hosts #修改hosts文件,永久生效
(2)查看各主机9092端口是否起来
ss -ntl

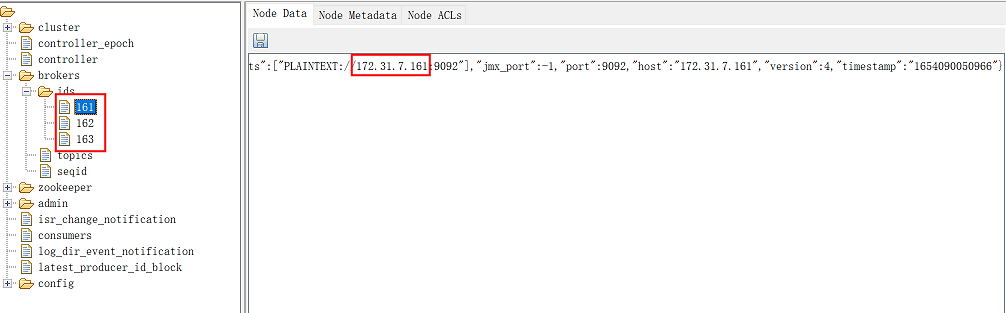
(3)通过ZooInspector工具连接zookeeper,查看kafka是否已经注册到zookeeper集群中
查看左侧brokers--ids,然后看到三个以kafka节点ip最后一位命名的三个文件,分别点击可以看到kafka的地址,说明kafka已经注册到zookeeper集群
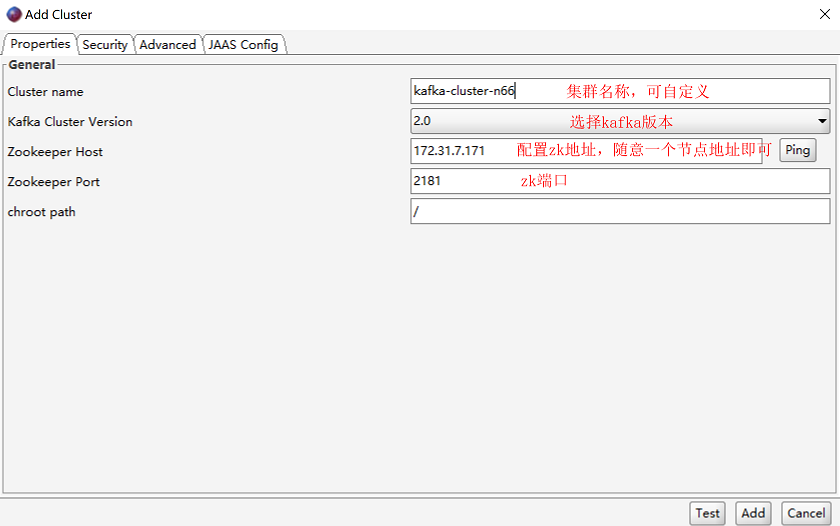
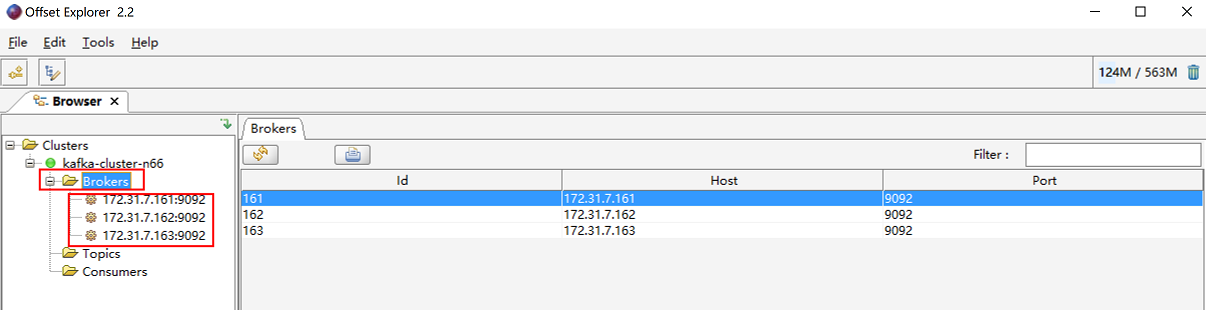
(4)在windows主机使用kafka tool工具连接kafka查看kafka内是否有数据
kafka tool下载页面:https://www.kafkatool.com/download.html
windows版本下载链接:https://www.kafkatool.com/download2/offsetexplorer_64bit.exe
安装完成后打开kafka tool,进行配置
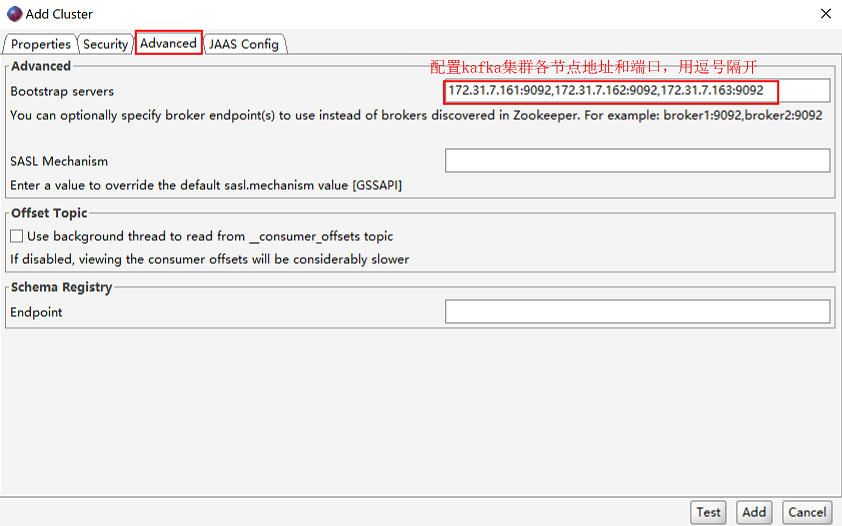
高级配置:
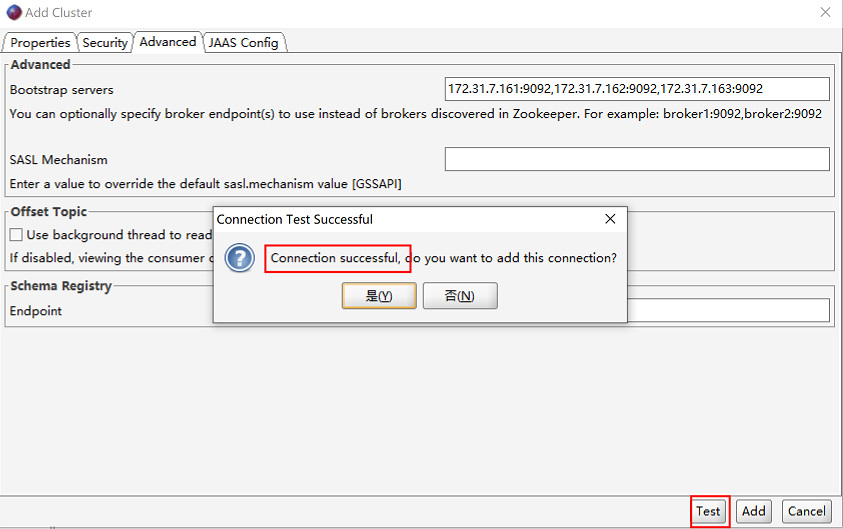
链接测试,如果返回connection successful,表示连接成功。点击“是”按钮查看集群情况
查看集群各节点
15.1.3 部署elasticsearch
elasticsearch依赖java环境,需要提前安装jdk,但elasticsearch有自带java环境的安装包,可以不用安装jdk,此时使用自带java环境的安装包。
elasticsearch对主机内存配置有要求,最少需要2G内存。
另外,elasticsearch,logstash,kibana三个组件都有相同的版本,下载时可以下载同一个版本。
官网下载页面:https://www.elastic.co/cn/downloads/past-releases#enterprise-search
1、下载elasticsearch并安装
三个节点分别执行:
下载elasticsearch rpm包,放到/usr/local/src/目录下
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-x86_64.rpm
安装elasticsearch
rpm -ivh /usr/local/src/elasticsearch-7.12.1-x86_64.rpm
2、修改配置文件并启动服务
(1)elasticsearch01节点172.31.7.181上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-n66 #指定集群名称,三个节点集群名称配置一样
node.name: es01 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 172.31.7.181 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
http.cors.enabled: true #支持跨域访问
http.cors.allow-origin: "*" #云允许所有域名访问
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service
(2)elasticsearch01节点172.31.7.182上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-n66 #指定集群名称,三个节点集群名称配置一样
node.name: es02 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 172.31.7.182 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
http.cors.enabled: true #支持跨域访问
http.cors.allow-origin: "*" #云允许所有域名访问
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service
(3)elasticsearch01节点172.31.7.183上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-n66 #指定集群名称,三个节点集群名称配置一样
node.name: es03 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 172.31.7.183 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
http.cors.enabled: true #支持跨域访问
http.cors.allow-origin: "*" #云允许所有域名访问
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service3、验证,查看9200端口是否被监听

4、通过谷歌浏览器插件elasticsearch-head连接elasticsearch进行验证。由于该插件需要访问谷歌商店才可以下载,因此无法加载,可以通过以下链接进行下载
(1)下载插件
插件下载地址:https://files.cnblogs.com/files/sanduzxcvbnm/elasticsearch-head.7z
(2)下载完成后进行解压elasticsearch-head.7z
(3)在浏览器加载elasticsearch-head插件步骤:
打开谷歌浏览器,点击右上角选项—更多工具—扩展程序
如果没有开启开发者模式,要开启开发者模式

选择加载已解压的扩展程序
加载完成
选择浏览器右上角插件图标,在下拉列表中选择elasticsearch head插件点击打开
在框内输入elasticsearch集群内随意一个节点ip地址,点击连接,即可显示集群内节点信息。节点前带有*号(星号)的为master节点,不带星号的是从节点

15.1.4 部署kibana
这里将kibana和elasticsearch01部署在同一台机器,因此kibana地址为172.31.7.181
1、下载kibana安装包并安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.12.1-x86_64.rpm
cd /usr/local/src
rpm -ivh kibana-7.12.1-x86_64.rpm2、修改kibana配置文件并启动服务
vim /etc/kibana/kibana.yml
server.port: 5601 #kibana监听端口
server.host: "172.31.7.181" #kibana地址
elasticsearch.hosts: ["http://172.31.7.181:9200"] #elasticsearch的地址和端口
i18n.locale: "zh-CN" #修改kibana页面显示语言为中文启动kibana服务
systemctl start kibana
3、验证
查看5601端口是否被监听

浏览器访问:172.31.7.181:5601
这里需要添加数据,由于k8s集群中尚未部署完成,没有收集到数据,因此需要等到收集到数据后再进行配置
15.2 日志收集方式
官网链接:https://kubernetes.io/zh/docs/concepts/cluster-administration/logging/
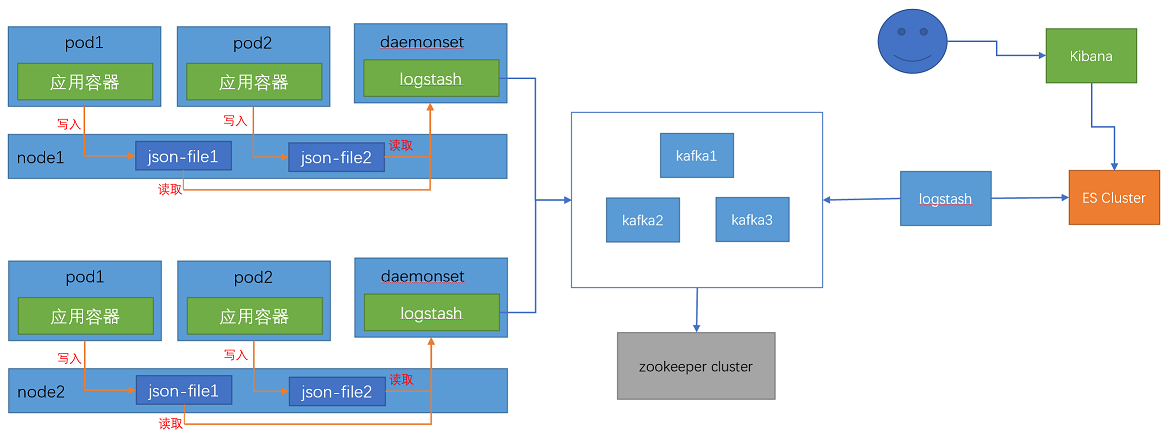
1、node节点收集,基于daemonset部署日志收集进程,实现json-file类型(标准输出/dev/stdout、错误输出/dev/stderr)日志收集。
这种方式的缺点是日志混乱,不容易区分。一般情况下,容器会将信息存储到宿主机的某个目录下(如/var/lib/container),但由于一个宿主机上承载多个容器,因此收集到的日志是混在一起的,不容易区分。这种方式的优点是部署简单,一个宿主机只需部署一个daemonset容器即可,占用资源较少。

2、使用sidcar容器(一个pod多容器)收集当前pod内一个或者多个业务容器的日志(通常基于emptyDir实现业务容器与sidcar之间的日志共享)。在同一个pod内拉起一个容器专门用来收集业务容器的日志,每个pod中都需要部署一个用来收集日志的容器,比较耗费资源。

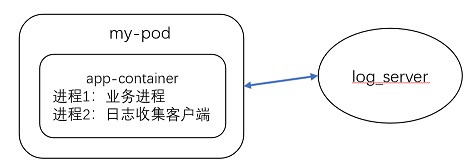
3、在容器内置日志收集服务进程。在一个容器内设置一个进程专门用来收集业务容器的日志信息。
15.2.1 node节点收集-基于daemonset容器进行收集
基于daemonset运行日志收集服务,主要收集以下类型日志:
1.node节点收集,基于daemonset部署日志收集进程,实现json-file类型(标准输出/dev/stdout、错误输出/dev/stderr)日志收集,即应用程序产生的标准输出和错误输出的日志。
2.宿主机系统日志等以日志文件形式保存的日志。
日志收集架构图:
日志收集流程:
(1)容器向node写入json格式的日志,同一个node上的logstash容器收集该node上存储的容器日志,写入kafka,logstash从kafka消费日志
(2)然后传递给elasticsearch集群,elasticsearch集群进行日志分析。
(3)用户从kibana上获取日志,kibana从elasticsearch上查询获取日志信息,然后展示出来。
注意:这里需要将node上存储容器日志的目录挂载到logstash容器上,使用hostpath类型的存储卷,便于logstash收集容器日志。
15.2.1.1 构建镜像
1、准备Dockerfile需要的文件
(1)准备logstash配置文件
vim logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ] #关闭xpack功能,该功能收费,如果不关闭将无法正常使用logstash(2)准备logstash日志收集的配置,通过配置input日志输入和output输出来匹配收集的容器日志
vim app1.conf
input {
file {
path => "/var/lib/docker/containers/*/*-json.log"
start_position => "beginning"
type => "jsonfile-daemonset-applog"
}
file {
path => "/var/log/*.log "
start_position => "beginning"
type => "jsonfile-daemonset-syslog"
}
}
output {
if [type] == "jsonfile-daemonset-applog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}"
} }
if [type] == "jsonfile-daemonset-syslog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
#codec => "${CODEC}" #系统日志不是json格式
}}
}配置参数说明:
path字段:
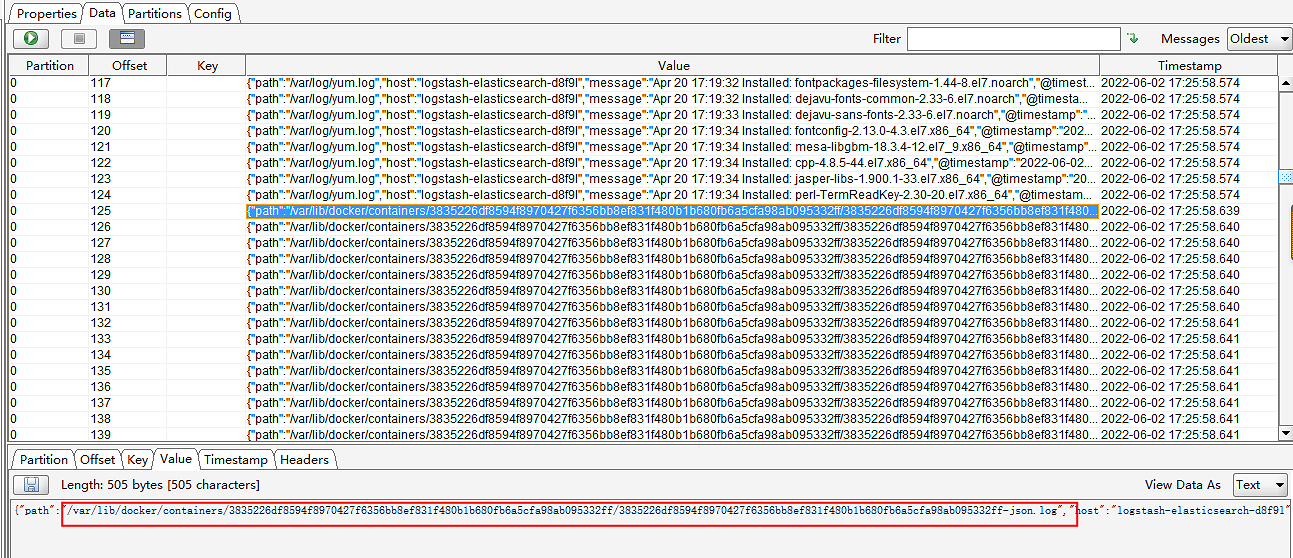
指定收集宿主机上/var/lib/docker/containers//-json.log(容器在宿主机存储的日志文件)和/var/log/*.log(宿主机的系统日志)。为了logstash容器能够收集容器日志和宿主机系统日志,需要将/var/lib/docker/containers/和/var/log/两个目录挂载到logstash容器内收集日志的目录上。
查看/var/lib/docker/containers//-json.log和/var/log/*.log
图1:

图2:
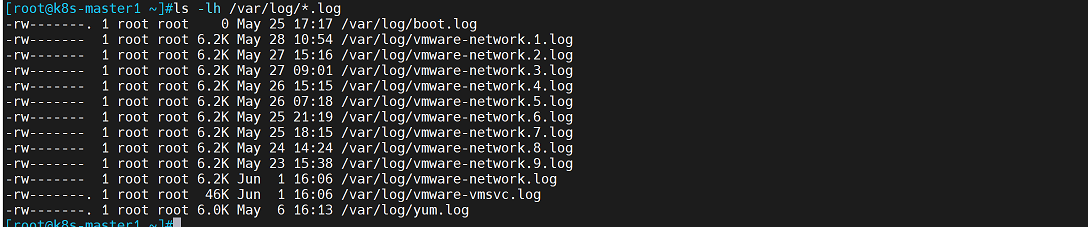
start_position:
指定收集日志的起始点,beginning是指从头开始收集
type:
指定日志文件类型,指定类型type是为了后续output配置中可以通过指定type来过滤日志
output配置:
通过判断类型(type)收集jsonfile-daemonset-applog类型和jsonfile-daemonset-syslog类型的日志。如果能够匹配,就将日志发送给kafka。
bootstrap_servers:指定kafka节点地址,引用yaml文件变量,即KAFKA_SERVER(该变量通过部署daemonset容器的yaml文件来指定,是kafka集群节点的地址)
注意:如果在配置中kafka地址直接使用kafka集群中各节点地址,一旦kafka集群某节点地址发生变化,就需要修改logstash的配置文件,比较麻烦,为了方便,通过引用变量的方式引用kafka集群各节点ip地址,一旦kafka地址发生变化,只需要修改yaml文件重打镜像即可
topic_id:指定消息id
codec:编码格式,引用yaml文件变量,指定为json格式,系统日志不是json格式,因此系统日志编码可以不用json格式
3、编写dockerfile文件
使用logstash官方镜像,根据需求进行自定义配置(使用root用户拉起进程,设置工作目录,添加自定义配置文件)
vim Dockerfile
FROM logstash:7.12.1
USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD app1.conf /usr/share/logstash/pipeline/logstash.conf4、编写构建镜像的脚本
vim build-commond.sh
#!/bin/bash
docker build -t harbor.magedu.local/baseimages/logstash:v7.12.1-json-file-log-v4 .
docker push harbor.magedu.local/baseimages/logstash:v7.12.1-json-file-log-v45、运行脚本,构建镜像
bash build-command.sh
15.2.1.2 k8s部署容器
1、编写 yaml文件
vim 2.DaemonSet-logstash.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: logstash-elasticsearch
namespace: log-collection
labels:
k8s-app: logstash-logging
spec:
selector:
matchLabels:
name: logstash-elasticsearch
template:
metadata:
labels:
name: logstash-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: logstash-elasticsearch
image: harbor.magedu.local/baseimages/logstash:v7.12.1-json-file-log-v4 #使用自构建的镜像
env: #设置环境变量,便于在Dockerfile中引用这些变量
- name: "KAFKA_SERVER"
value: "172.31.7.161:9092,172.31.7.162:9092,172.31.7.163:9092"
- name: "TOPIC_ID"
value: "jsonfile-log-topic"
- name: "CODEC"
value: "json"
# resources:
# limits:
# cpu: 1000m
# memory: 1024Mi
# requests:
# cpu: 500m
# memory: 1024Mi
volumeMounts:
- name: varlog
mountPath: /var/log #指定宿主机系统日志在容器内的挂载路径
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers #指定容器存储在宿主机上日志目录在容器内的挂载路径
readOnly: false
terminationGracePeriodSeconds: 30
volumes: #设置挂载,将宿主机系统日志路径和容器存储宿主机的日志路径挂载到logstash容器中,便于logstash收集日志
- name: varlog
hostPath: #使用hostPath类型的存储卷
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers2、为日志收集容器创建单独的namespace
kubectl create ns log-collection
3、创建容器
kubectl apply -f 2.DaemonSet-logstash.yaml
4、查看daemonset容器(由于是daemonset容器,因此master和node节点上都会部署)

如果master2和master3上没有部署,则可能是master2和master3上没有配置harbor证书,导致无法从harbor拉取镜像。在master2和master3上分发完harbor证书后,需要在hosts文件添加harbor域名的解析关系
进入容器查看/var/log/和/var/lib/docker/containers/目录下的日志,均为宿主机日志
kubectl exec -it logstash-elasticsearch-2sdtv bash -n log-collection
[root@logstash-elasticsearch-2sdtv logstash]# ls /var/log/
[root@logstash-elasticsearch-2sdtv logstash]# ls /var/lib/docker/containers/

5、查看配置文件
[root@logstash-elasticsearch-2sdtv logstash]# cat /usr/share/logstash/pipeline/logstash.conf
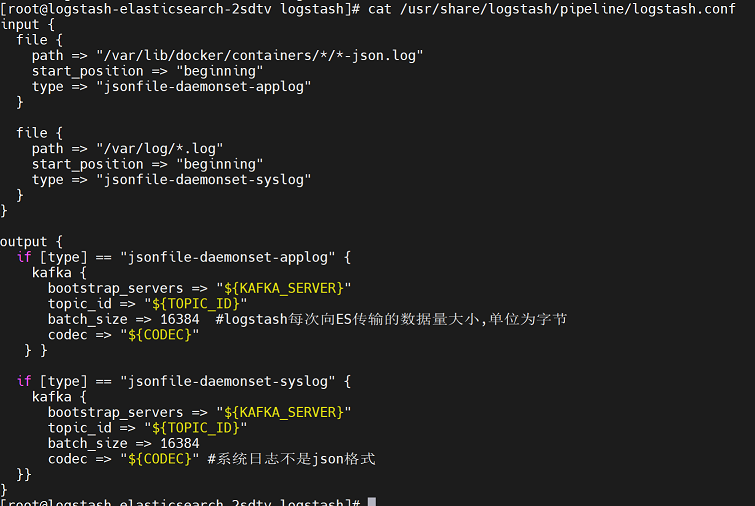
[root@logstash-elasticsearch-2sdtv ~]# cat /usr/share/logstash/config/logstash.yml

15.2.1.3 验证:查看日志内容
此时,整个日志收集流程已经完成。
1、通过kafka tool查看kafka集群接收到的日志内容
daemonset容器中logstash将宿主机上容器以及系统日志收集,发送给kafka,我们通过kafka tool工具可以连接到kafka集群,查看数据是否已经生成
选择显示格式,默认为二进制格式,修改为显示为字符串
查看kafka集群日志内容,可以看到容器日志和系统日志

查看系统日志详细内容:/var/log目录下的日志

查看容器日志详细内容:/var/lib/docker/container目录下的日志
调整日志显示最大行数(默认只显示50行)

15.2.1.4 部署logstash并进行配置
注意:这里的logstash并不是在k8s集群中收集容器日志的logstash,而是用来消费kafka集群日志的logstash,在配置logstash input和output配置时要注意前后关系
1、下载logstash并安装
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.12.1-x86_64.rpm
安装logstash
rpm -ivh /usr/local/src/logstash-7.12.1-x86_64.rpm2、编辑配置文件(配置文件需要自己进行编写)
vim /etc/logstash/conf.d/daemonset-log-to-es.conf
input {
kafka {
bootstrap_servers => "172.31.7.161:9092,172.31.7.162:9092,172.31.7.163:9092" #指定kafka集群中各节点地址
topics => ["jsonfile-log-topic"]
codec => "json"
}
}
output {
#if [fields][type] == "app1-access-log" {
if [type] == "jsonfile-daemonset-applog" { #配置日志类型type,要和logstash中input配置段中type一致,否则logstash将无法从kafka获取日志
elasticsearch {
hosts => ["172.31.7.181:9200","172.31.7.182:9200"] #指定es集群各节点地址,可以只写两个
index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"
}}
if [type] == "jsonfile-daemonset-syslog" { #配置日志类型type,要和logstash中input配置段中type一致,否则logstash将无法从kafka获取日志
elasticsearch {
hosts => ["172.31.7.181:9200","172.31.7.182:9200"] #指定es集群各节点地址,可以只写两个
index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"
}}
}
配置参数说明:
input配置:
指定kafka集群个节点地址,指定topics,该topics就是在k8s集群中daemonset yml文件中引用的topics变量,指定编码为json
output配置:
通过type过来日志,将过滤的日志发送给elasticsearch,hosts指定elasticsearch集群各节点地址,index指定索引,用日期进行区分。这里分别过滤容器日志jsonfile-daemonset-applog和系统日志jsonfile-daemonset-syslog
hosts:
指定elasticsearch集群各节点地址
index:
指定索引格式3、启动服务
systemctl start logstash
查看启动日志,是否有报错
cat /var/log/logstash/logstash-plain.log
4、部署完成后,此时logstash可以消费kafka集群内的日志,通过elasticsearch head插件查看elasticsearch集群中的索引
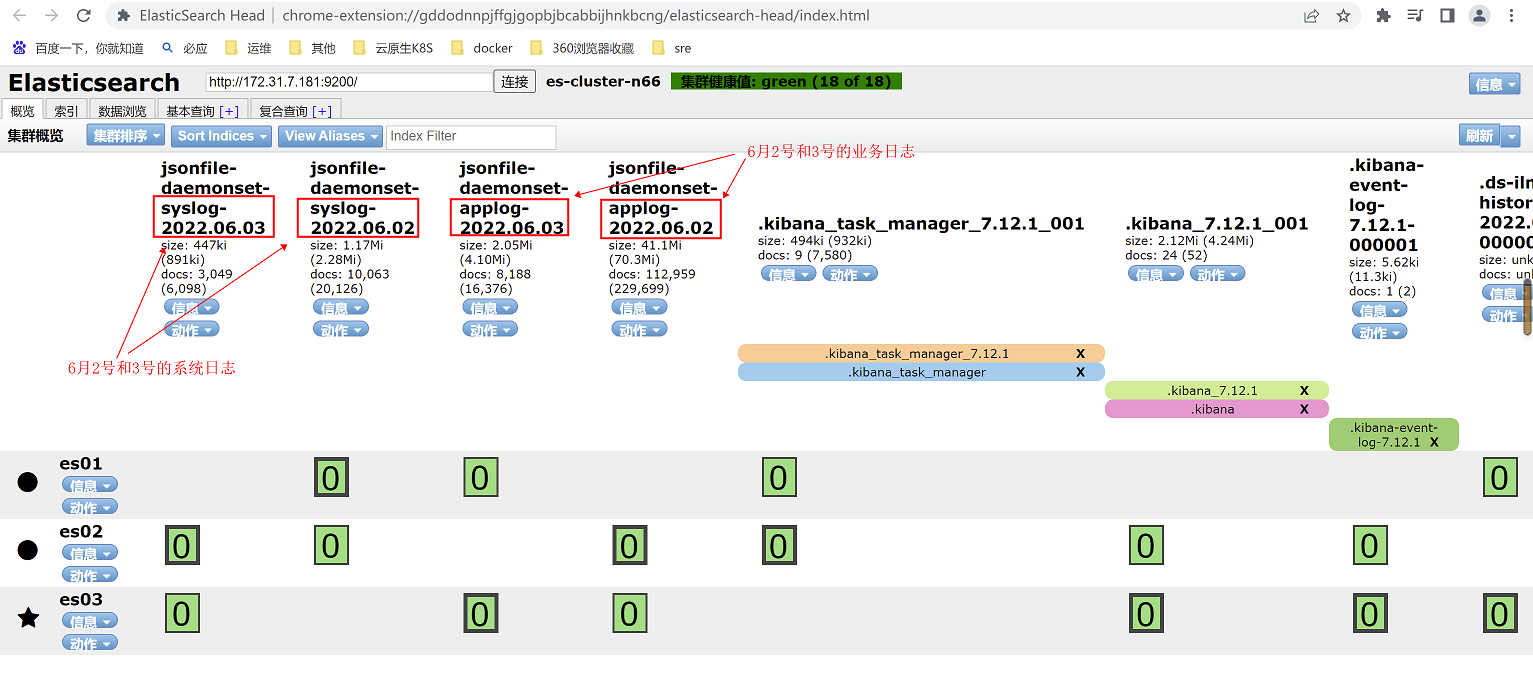
15.2.1.5 配置kibana
通过浏览器访问http://172.31.7.181:5601,在控制台进行配置操作。
15.2.1.5.1 添加业务容器日志索引
1、选择management—management stack
2、kibana-索引模式-创建索引模式
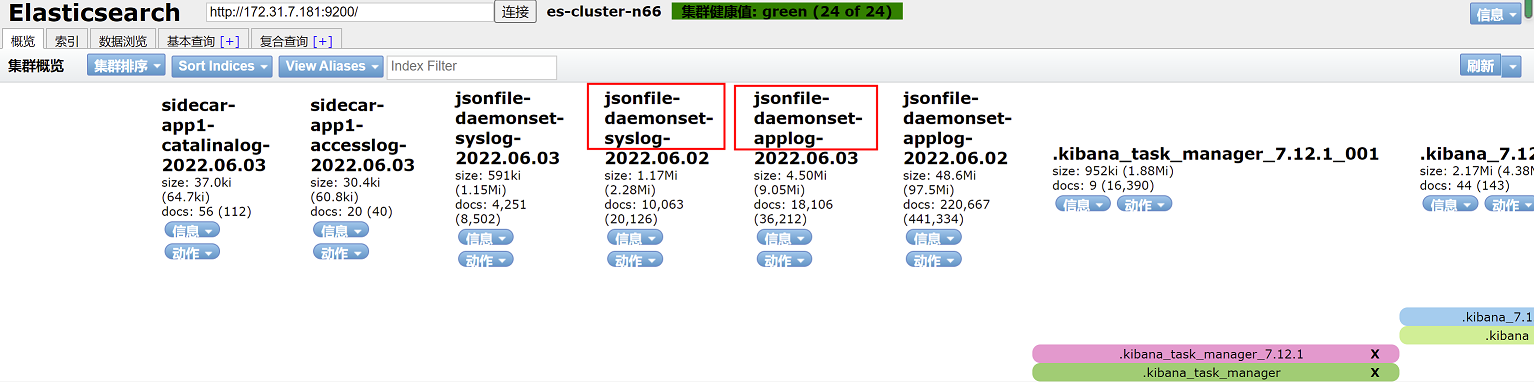
3、添加容器日志的索引,然后点击下一步
在elasticsearch head页面查看索引名称,红框中索引名称,日志以*代替,即jsonfile-daemonset-applog-*和jsonfile-daemonset-syslog-*
创建索引模式
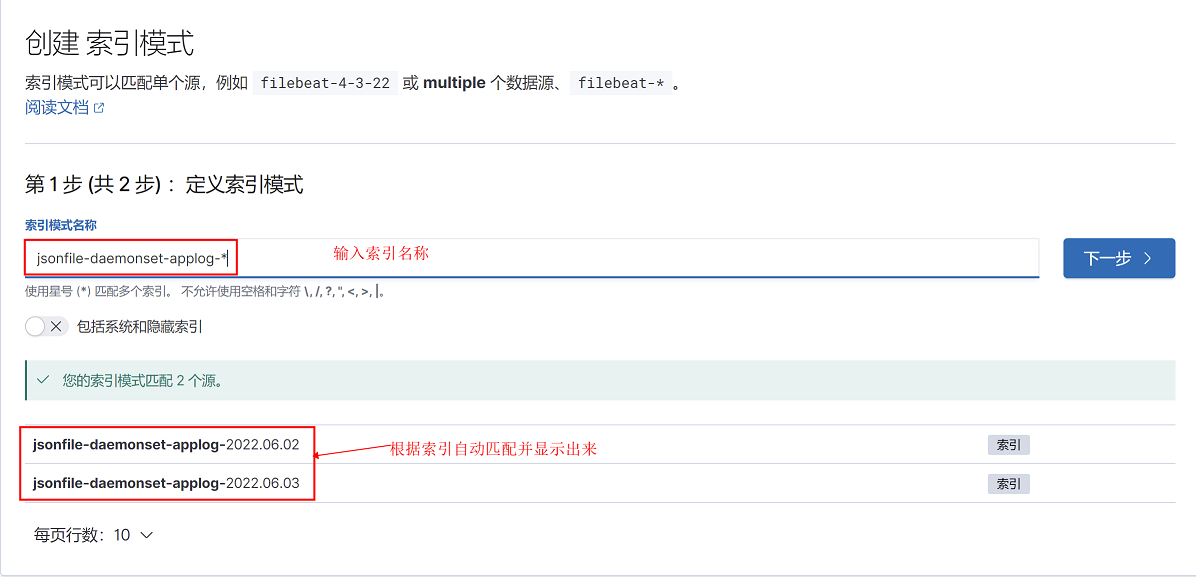
4、选择筛选字段为@timestamp,点击右下角创建索引模式
15.2.1.5.2 添加宿主机系统日志索引
1、选择management—management stack
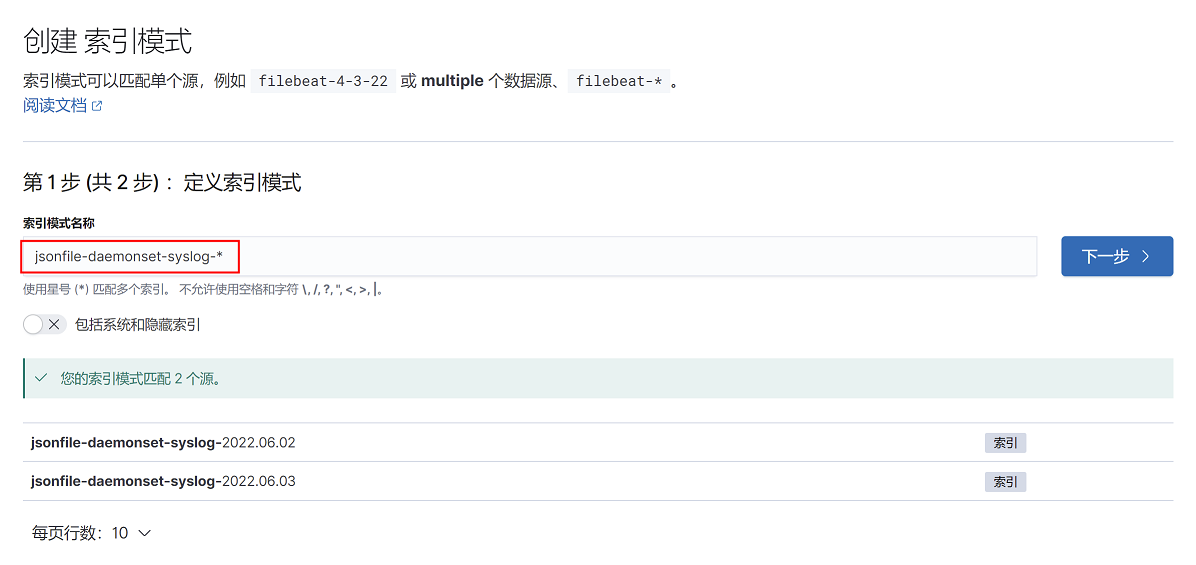
2、kibana-索引模式-创建索引模式
3、填写索引,点击下一步
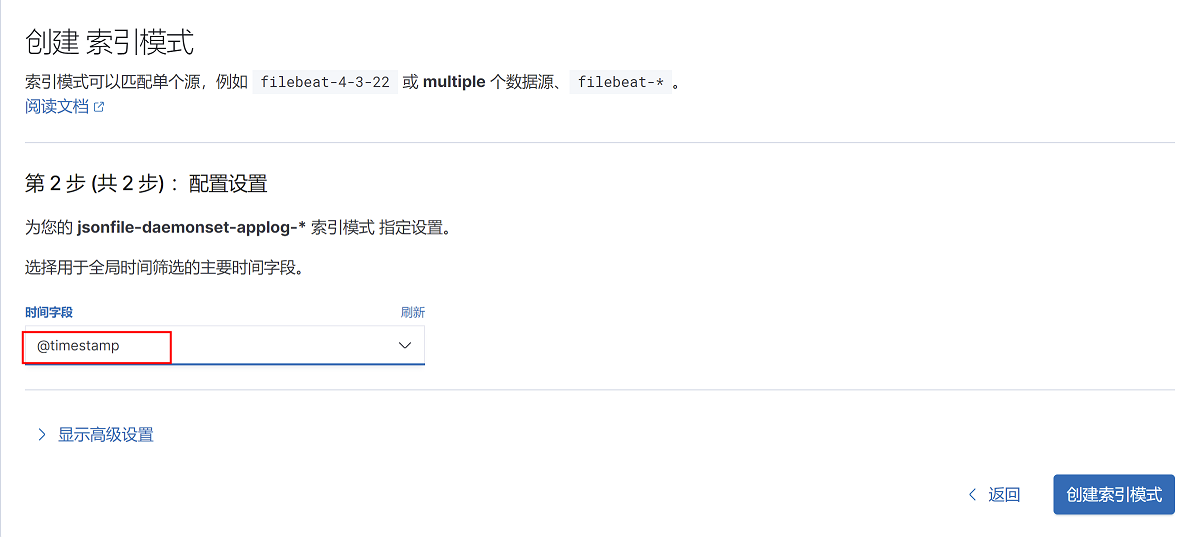
4、选择索引筛选字段@timestamp,点击创建索引模式
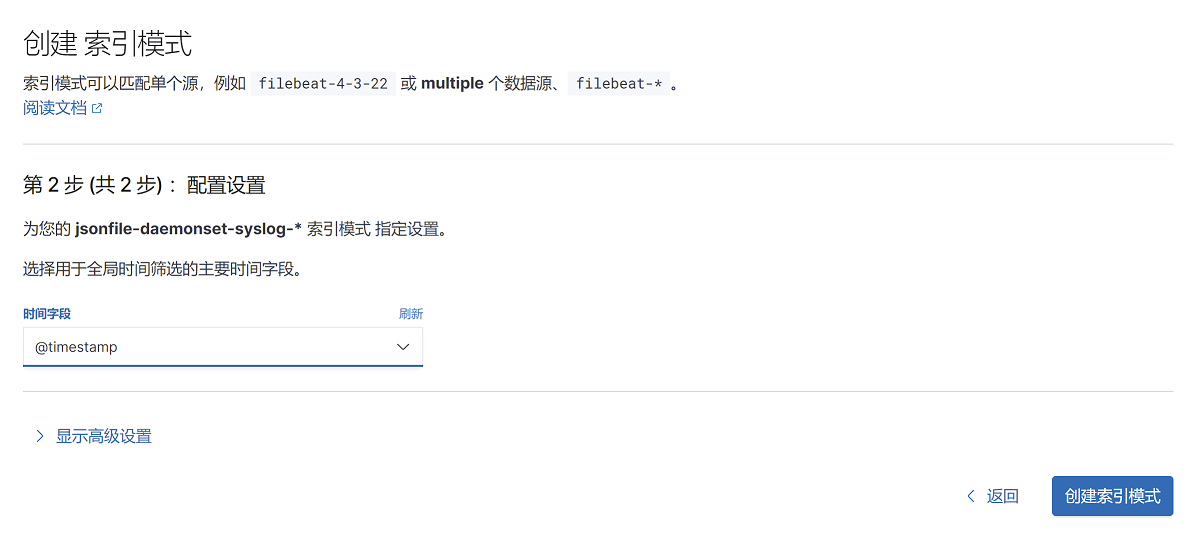
15.2.1.5.3 查看日志数据
1、选择analytics---discover
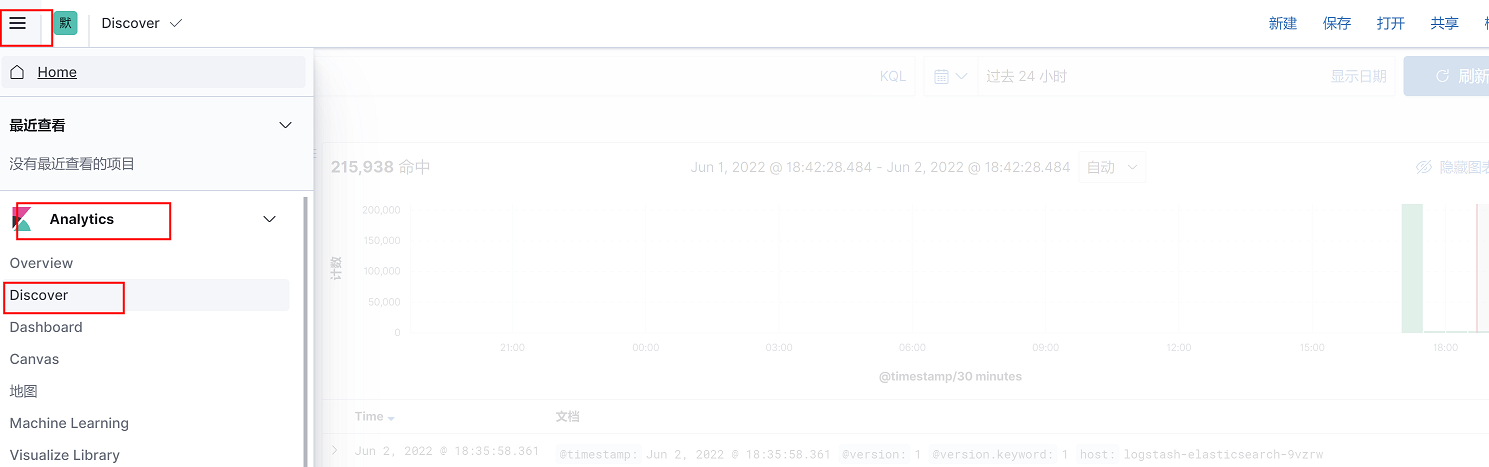
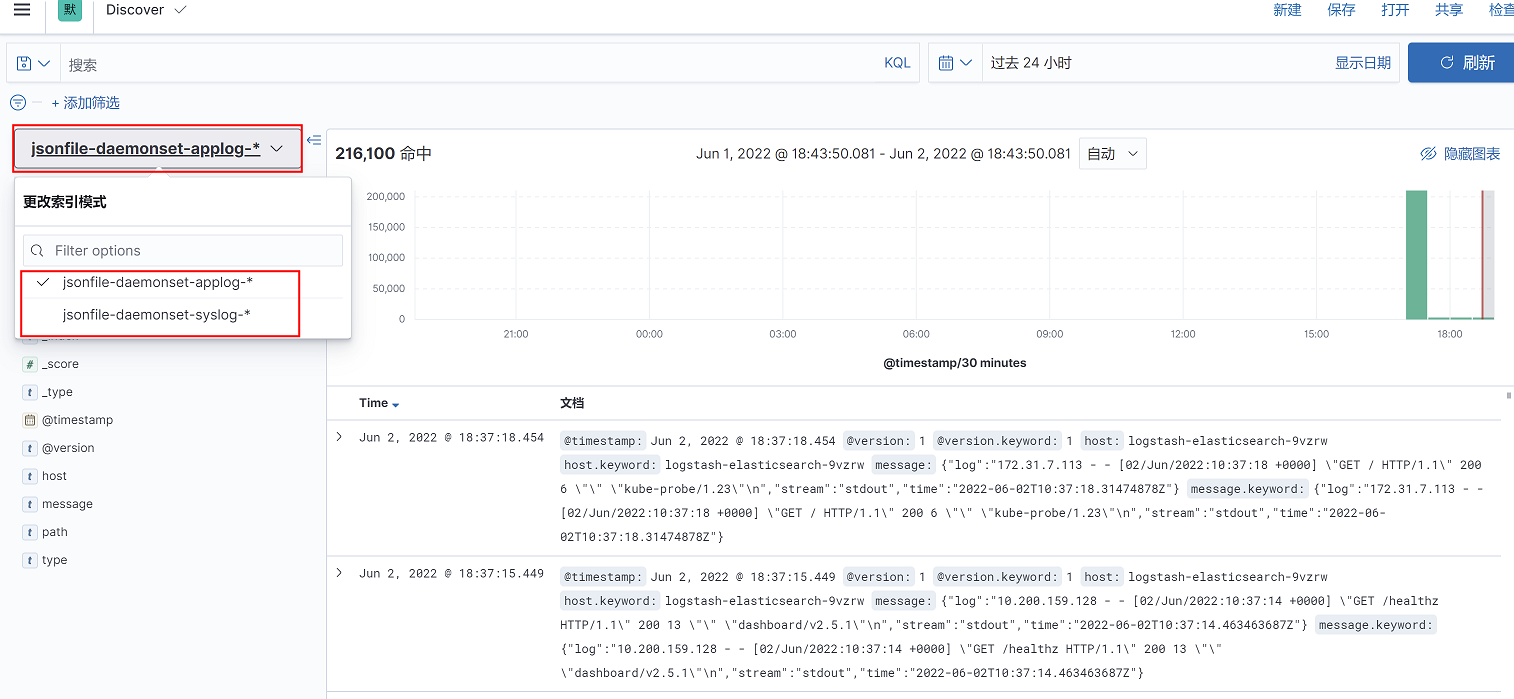
2、可以通过左侧索引选择查看业务容器日志还是宿主机系统日志
3、日志内容如下:
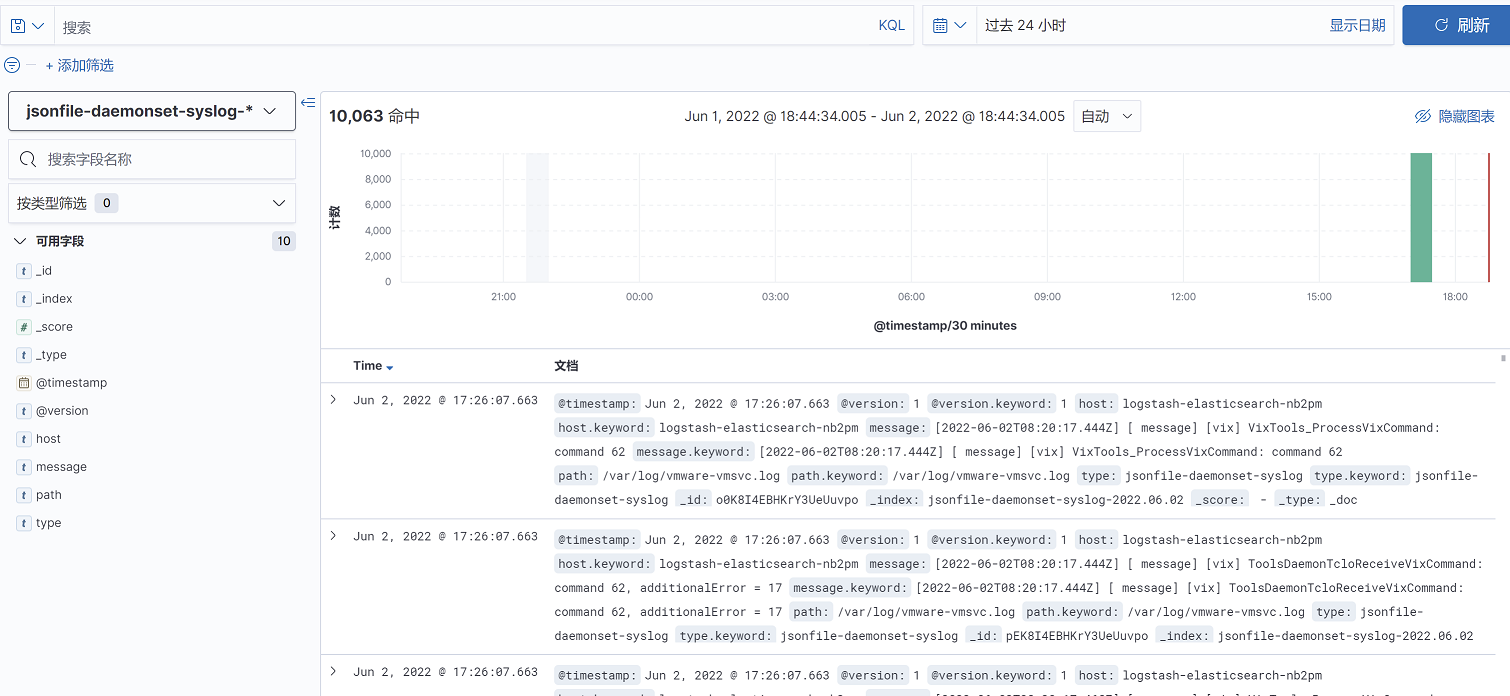
需要注意的是:这种模式部署的logstash只能收集标准输出或错误输出,即/dev/stdout和/dev/stderr日志,如果是业务容器的访问日志,如tomcat的访问日志,因为这些日志不是标准输出,因此收集不到,kibana上也看不到这些日志。
但是,如果使用nginx官方镜像拉起nginx容器,是可以收集到nginx访问日志的,这是因为nginx官方镜像把的access.log和error.log软链接到/dev/stdout和/dev/stderr,一旦访问nginx,日志会写入到标准输出,logstash可以收集到
示例:
1、编辑yaml文件
vim nginx.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: magedu-nginx-deployment-label
name: magedu-nginx-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-nginx-selector
template:
metadata:
labels:
app: magedu-nginx-selector
spec:
containers:
- name: magedu-nginx-container
image: nginx:1.20.0 #使用nginx官方镜像
#command: ["/apps/tomcat/bin/run_tomcat.sh"]
#imagePullPolicy: IfNotPresent
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
- containerPort: 443
protocol: TCP
name: https
env:
- name: "password"
value: "123456"
- name: "age"
value: "20"
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 500m
memory: 500Mi
volumeMounts:
- name: magedu-images
mountPath: /usr/local/nginx/html/webapp/images
readOnly: false
- name: magedu-static
mountPath: /usr/local/nginx/html/webapp/static
readOnly: false
volumes:
- name: magedu-images
nfs:
server: 172.31.7.109
path: /data/k8sdata/magedu/images
- name: magedu-static
nfs:
server: 172.31.7.109
path: /data/k8sdata/magedu/static
#nodeSelector:
# group: magedu
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-nginx-service-label
name: magedu-nginx-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
nodePort: 30090
- name: https
port: 443
protocol: TCP
targetPort: 443
nodePort: 30091
selector:
app: magedu-nginx-selector2、创建容器并访问该容器
kubectl apply -f nginx-test.yaml
3、进入容器查看nginx的访问日志和错误日志

4、当我们使用死循环一直访问nginx日志时,就可以在kibana上看到nginx的访问日志
while true ;do curl http://172.31.7.112:30090; sleep 0.5 ;done
查看kibana,可以看到curl的访问情况
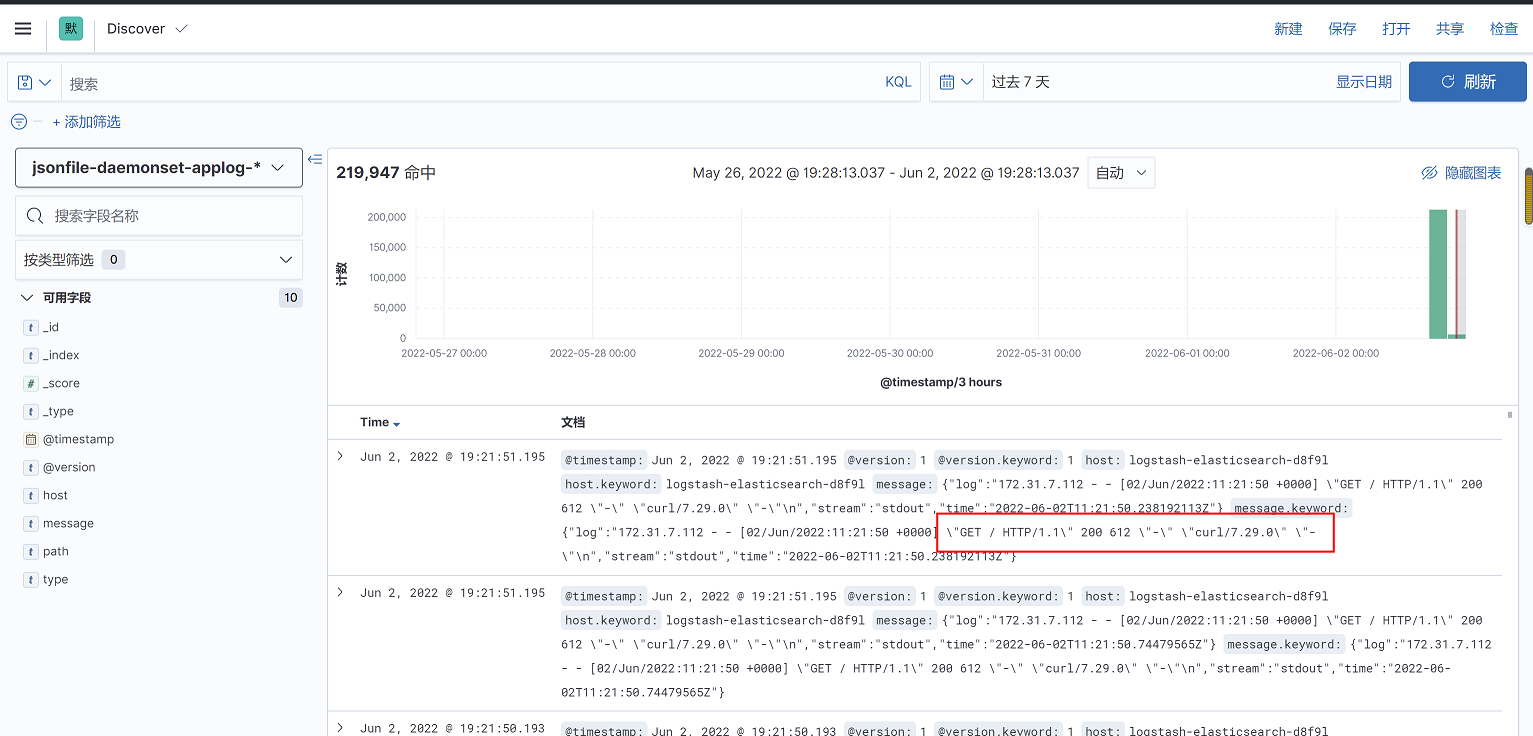
15.2.2 pod级别日志收集-基于sidcar容器方式收集
使用sidcar容器(一个pod多容器)收集当前pod内一个或者多个业务容器的日志(通常基于emptyDir实现业务容器与sidcar之间的日志共享)。使用emptydir类型的存储卷,在同一个pod中共享挂载目录下的日志。
优点:可以区分是哪个容器的日志
缺点:每个pod中都要拉起一个sidecar容器,比较占用资源
架构图:
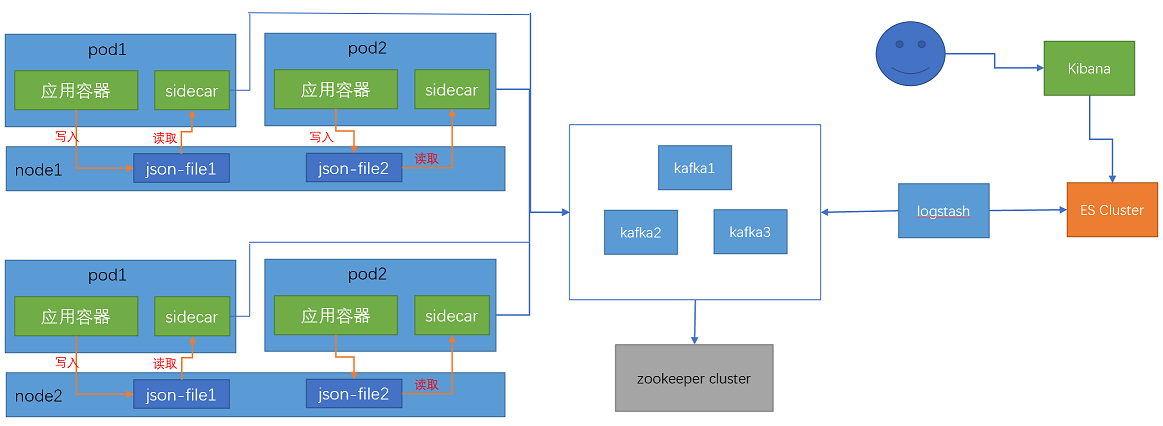
日志收集流程:
(1)容器将访问日志写入emptydir存储卷中,同一个pod中的sidecar容器通过挂载emptydir存储卷到容器内获取容器日志。
(2)然后将日志写入kafka,logstash从kafka消费日志。
(3)然后传递给elasticsearch集群,elasticsearch集群进行日志分析。
(4)用户从kibana上获取日志,kibana从elasticsearch上查询获取日志信息,然后展示出来。
注意:
(1)这里需要将node上存储容器日志的目录挂载到logstash容器上,使用hostpath类型的存储卷,便于logstash收集容器日志。
(2)logstash或filebeat会维护一个日志位置信息,会记录上一次的日志同步位置信息,在下一次进行同步时,根据该位置信息继续进行同步(默认每隔1s检查一次进行同步)。15.2.2.1 构建镜像
1、准备Dockerfile需要的文件
(1)准备logstash配置文件
vim logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ] #关闭xpack功能,该功能收费,如果不关闭将无法正常使用logstash(2)准备logstash日志收集的配置,通过配置input日志输入和output输出来匹配收集的容器日志
vim app1.conf
input {
file {
path => "/var/log/applog/catalina.out"
start_position => "beginning"
type => "app1-sidecar-catalina-log"
}
file {
path => "/var/log/applog/localhost_access_log.*.txt"
start_position => "beginning"
type => "app1-sidecar-access-log"
}
}
output {
if [type] == "app1-sidecar-catalina-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}"
} }
if [type] == "app1-sidecar-access-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}"
}}
}
配置参数说明:
input配置:
path字段:
指定收集tomcat容器/var/log/applog/catalina.out启动日志和/var/log/applog/localhost_access_log.\*.txt访问日志。为了sidecar容器(即logstash容器)能够收集tomcat容器日志,需要配置emptydir存储卷,并将该存储卷挂载到业务容器和sidecar容器内共享日志。
start_position:
指定收集日志的起始点,beginning是指从头开始收集
type:
指定日志文件类型,指定类型type是为了后续output配置中可以通过指定type来过滤日志
output配置:
通过判断类型(type)收集app1-sidecar-catalina-log类型和app1-sidecar-access-log类型的日志。如果能够匹配,就将日志发送给kafka。
bootstrap_servers:
指定kafka节点地址,引用yaml文件变量,即KAFKA_SERVER(该变量通过部署daemonset容器的yaml文件来指定,是kafka集群节点的地址)
注意:如果在配置中kafka地址直接使用kafka集群中各节点地址,一旦kafka集群某节点地址发生变化,就需要修改logstash的配置文件,比较麻烦,为了方便,通过引用变量的方式引用kafka集群各节点ip地址,一旦kafka地址发生变化,只需要修改yaml文件重打镜像即可
topic_id:
指定消息id
codec:
编码格式,引用yaml文件变量,指定为json格式,系统日志不是json格式,因此系统日志编码可以不用json格式3、编写dockerfile文件
使用logstash官方镜像,根据需求进行自定义配置(使用root用户拉起进程,设置工作目录,添加logstash的配置文件app1.conf和logstash.yml)
vim Dockerfile
FROM logstash:7.12.1
USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD app1.conf /usr/share/logstash/pipeline/logstash.conf4、编写构建镜像的脚本
vim build-commond.sh
#!/bin/bash
docker build -t harbor.magedu.local/baseimages/logstash:v7.12.1-sidecar .
docker push harbor.magedu.local/baseimages/logstash:v7.12.1-sidecar 5、运行脚本,构建镜像
bash build-command.sh
15.2.2.2 k8s部署容器
1、编写 yaml文件
vim 2.tomcat-app1.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app1-deployment-label
name: magedu-tomcat-app1-deployment #当前版本的deployment 名称
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app1-selector
template:
metadata:
labels:
app: magedu-tomcat-app1-selector
spec:
containers:
- name: sidecar-container #定义pod内第一个容器为sidecar容器
image: harbor.magedu.local/baseimages/logstash:v7.12.1-sidecar #使用自构建镜像
imagePullPolicy: Always
env: #设置环境变量,便于在Dockerfile中引用这些变量
- name: "KAFKA_SERVER"
value: "172.31.7.161:9092,172.31.7.162:9092,172.31.7.163:9092"
- name: "TOPIC_ID"
value: "tomcat-app1-topic"
- name: "CODEC"
value: "json"
volumeMounts:
- name: applogs #指定emptydir存储卷挂载到容器内的路径,用于获取业务容器日志
mountPath: /var/log/applog
- name: magedu-tomcat-app1-container #定义第二个容器为tomcat业务容器
image: registry.cn-hangzhou.aliyuncs.com/zhangshijie/tomcat-app1:v1 #使用自定义镜像,该镜像在演示镜像更新和回滚时使用过
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
volumeMounts:
- name: applogs #指定emptydir存储卷挂载到容器内的路径,用于共享业务容器日志
mountPath: /apps/tomcat/logs
startupProbe: #定义启动探针
httpGet:
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5 #首次检测延迟5s
failureThreshold: 3 #从成功转为失败的次数
periodSeconds: 3 #探测间隔周期
readinessProbe: #定义就绪探针
httpGet:
#path: /monitor/monitor.html
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
livenessProbe: #定义存活探针
httpGet:
#path: /monitor/monitor.html
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
volumes:
- name: applogs #定义emptydir存储卷,用于共享业务容器日志
emptyDir: {}2、创建容器
kubectl apply -f 2.tomcat-app1.yaml
3、为容器配置service
vim 3.tomcat-service.yaml
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-tomcat-app1-service-label
name: magedu-tomcat-app1-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 40080
selector:
app: magedu-tomcat-app1-selector(1)创建service
kubectl apply -f 3.tomcat-service.yaml
查看sidecar容器/var/log/applogs目录下日志和tomcat容器/app/tomcat/logs/目录下的日志,发现日志内容一样,这样logstash就可以收集到tomcat容器日志
4、查看sidecar容器日志

5、查看tomcat容器日志

6、为了便于演示效果,配置死循环访问tomcat容器产生访问日志(tomcat容器在宿主机172.31.7.111上)
while true ;do curl http://172.31.7.111:40080/myapp/index.html;sleep 0.5 ;done
15.2.2.3 验证:查看日志内容
此时,整个日志收集流程已经完成。
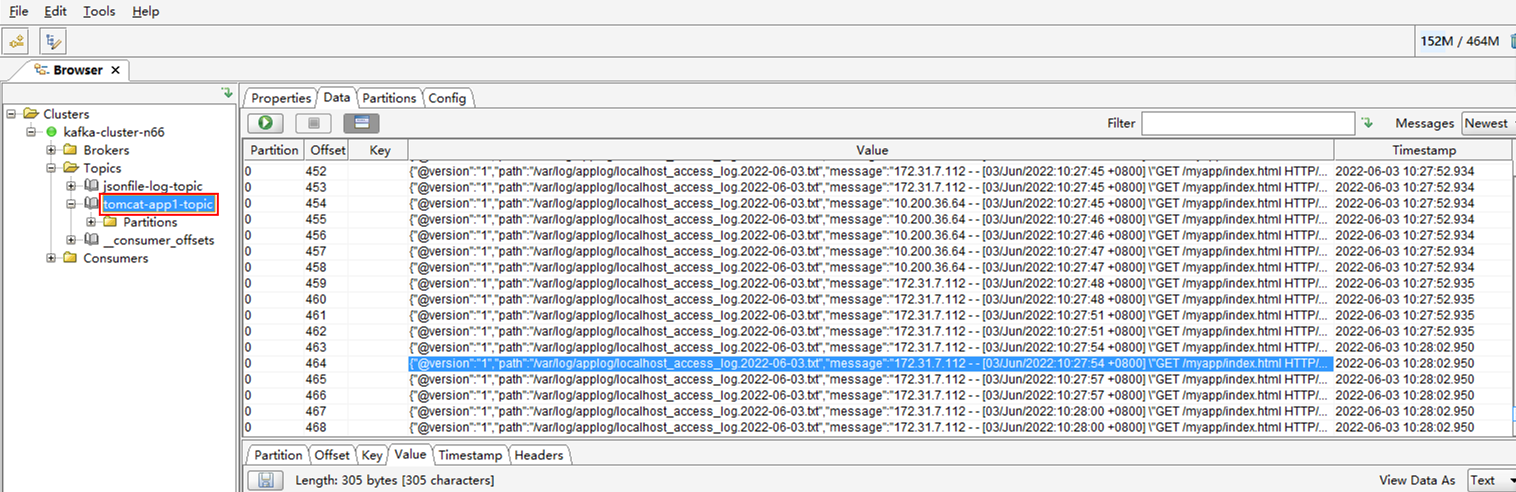
1、通过kafka tool查看kafka集群接收到的日志内容
daemonset容器中logstash将宿主机上容器以及系统日志收集,发送给kafka,我们通过kafka tool工具可以连接到kafka集群,查看数据是否已经生成
可以看到tomcat的tipics
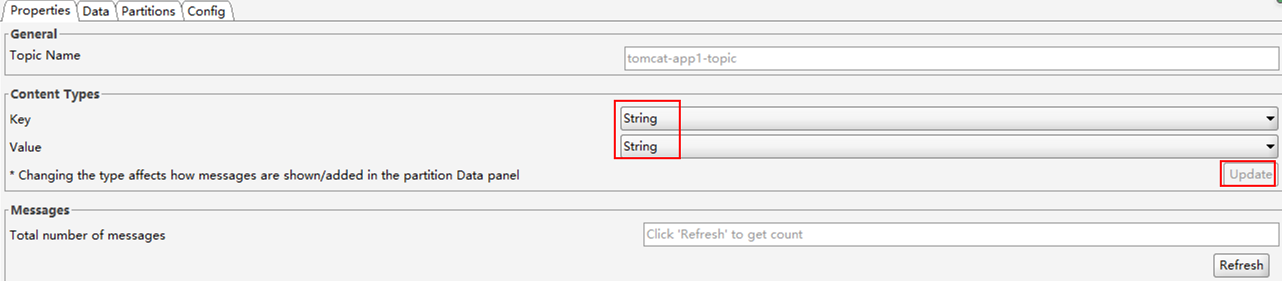
选择显示格式,默认为二进制格式,修改为显示为字符串
查看kafka集群日志内容,可以看到tomcat的访问日志
查看tomcat容器/var/log/applog/catalina.out日志
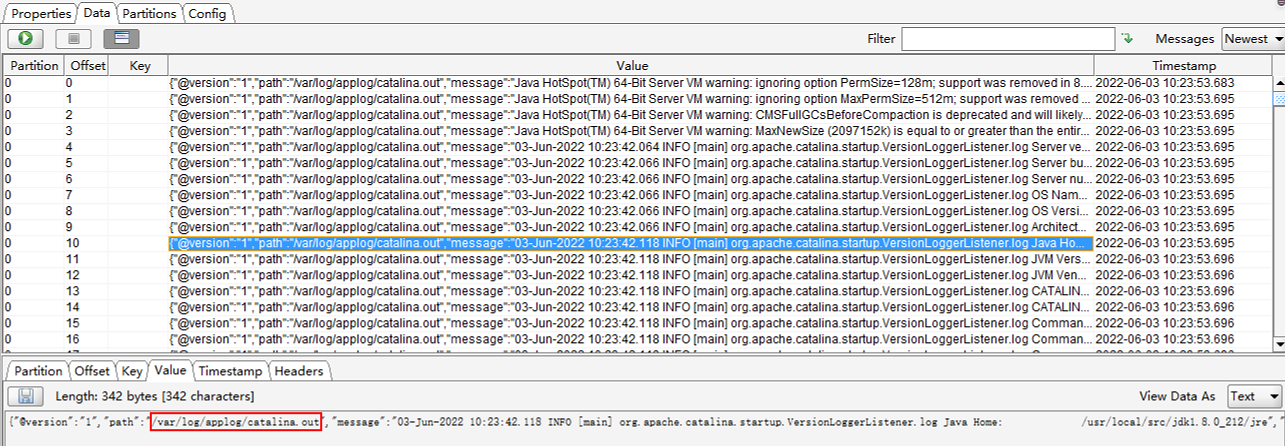
查看tomcat容器/var/log/applog/localhost_access_log.2022-06-03.txt日志
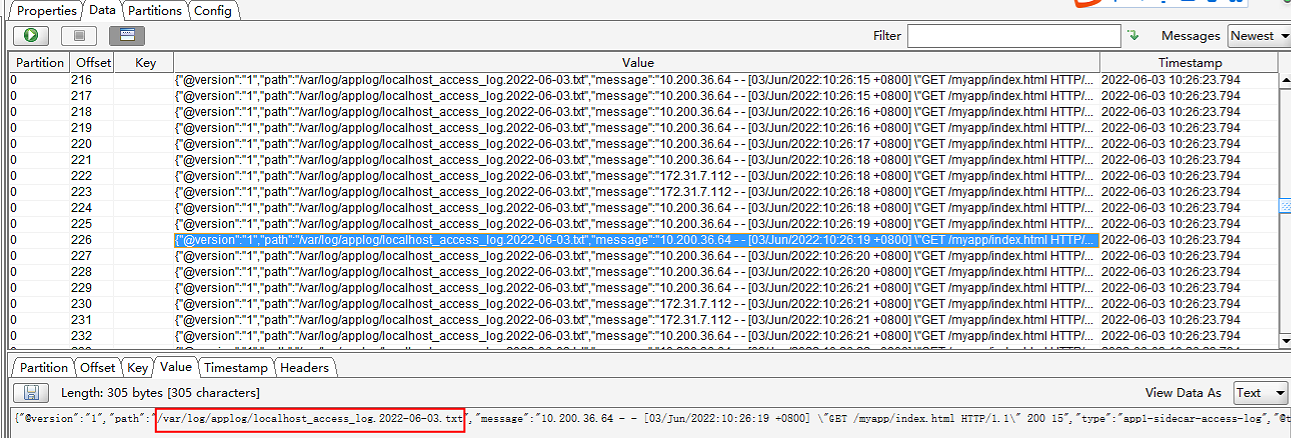
调整日志显示最大行数为500(默认只显示50行)
15.2.2.4 修改logstash配置
由于使用的sidecar方式收集日志,而且sidecar容器的logstash配置文件中type类型发生变化,用于消费kafka日志的logstash容器中的配置文件也要做出相应的修改,否则将无法消费kafka集群中的日志
由于logstash已经部署完成,这里只需要修改logstash配置即可
1、编辑配置文件(配置文件需要自己进行编写)
vim /etc/logstash/conf.d/sidecar-log-to-es.conf
input {
kafka {
bootstrap_servers => "172.31.7.161:9092,172.31.7.162:9092,172.31.7.163:9092" #指定kafka集群各节点地址
topics => ["tomcat-app1-topic"]
codec => "json"
}
}
output {
#if [fields][type] == "app1-access-log" {
if [type] == "app1-access-log" { #配置日志类型type,要和logstash中input配置段中type一致,否则logstash将无法从kafka获取日志
elasticsearch {
hosts => ["172.31.7.181:9200","172.31.7.182:9200"] #指定es集群各节点地址,可以只写两个
index => "sidecar-app1-accesslog-%{+YYYY.MM.dd}"
}
}
#if [fields][type] == "app1-catalina-log" {
if [type] == "app1-catalina-log" { #配置日志类型type,要和logstash中input配置段中type一致,否则logstash将无法从kafka获取日志
elasticsearch {
hosts => ["172.31.7.181:9200","172.31.7.182:9200"] #指定es集群各节点地址,可以只写两个
index => "sidecar-app1-catalinalog-%{+YYYY.MM.dd}"
}
}
}
配置参数说明:
input配置:
指定kafka集群个节点地址,指定topics,该类型就是在k8s集群中sidecar容器yml文件中引用的topics变量,指定编码为json
output配置:
通过type过来日志,将过滤的日志发送给elasticsearch,hosts指定elasticsearch集群各节点地址,index指定索引,用日期进行区分。这里分别过滤容器日志jsonfile-daemonset-applog和系统日志jsonfile-daemonset-syslog
hosts:
指定elasticsearch集群各节点地址
index:
指定索引格式3、重启服务
systemctl restart logstash
查看启动日志,是否有报错
cat /var/log/logstash/logstash-plain.log
4、部署完成后,此时logstash可以消费kafka集群内的日志,通过elasticsearch head插件查看elasticsearch集群中的索引
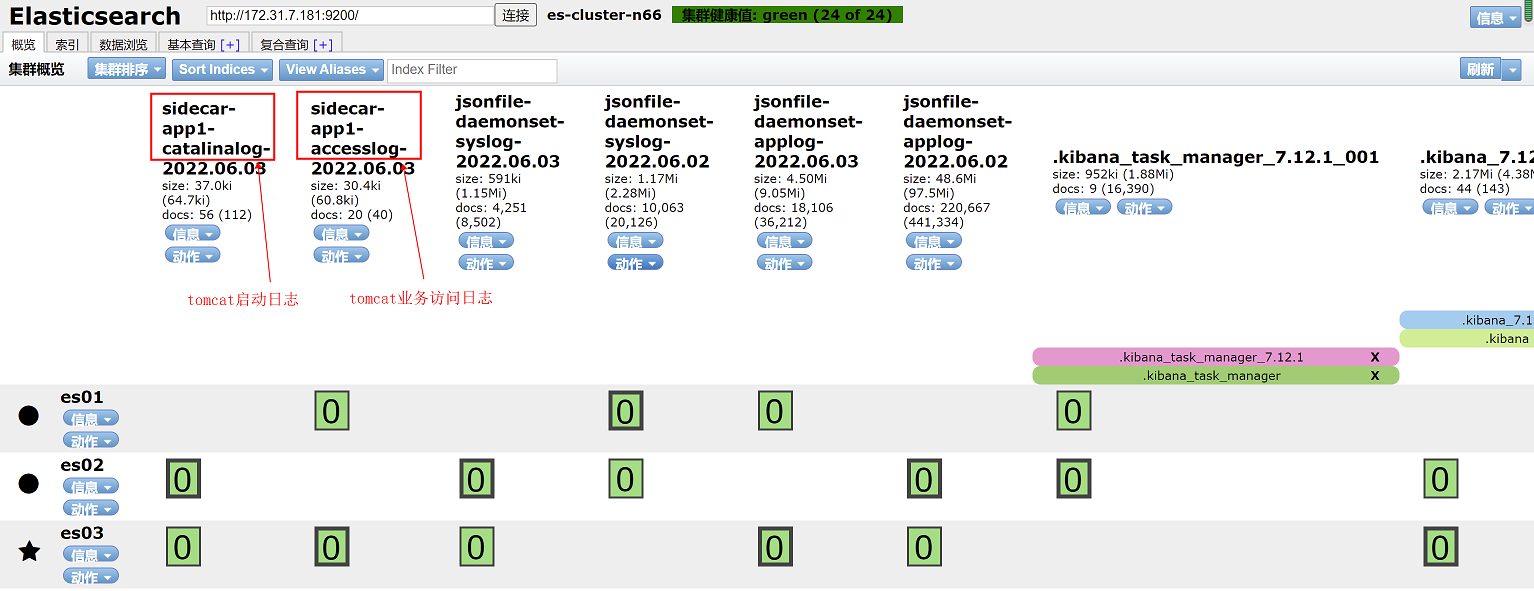
注意:如果确认各个环节没有问题,但是看不到访问日志和启动日志,有可能是没有新日志产生导致,可以手动访问tomcat或者增加tomcat容器副本来生成访问日志和启动日志,或者手动在启动日志和访问日志中写入一些信息作为新的日志写入
15.2.2.5 配置kibana
通过浏览器访问http://172.31.7.181:5601/
15.2.2.5.1 添加tomcat容器访问日志索引
1、选择management—management stack
2、kibana-索引模式-创建索引模式
3、添加容器日志的索引,然后点击下一步。
再elasticsearch head页面查看索引名称,红框中索引名称,日志以*代替,即sidecar-app1-accesslog-*和sidecar-app1-catalinalog-*
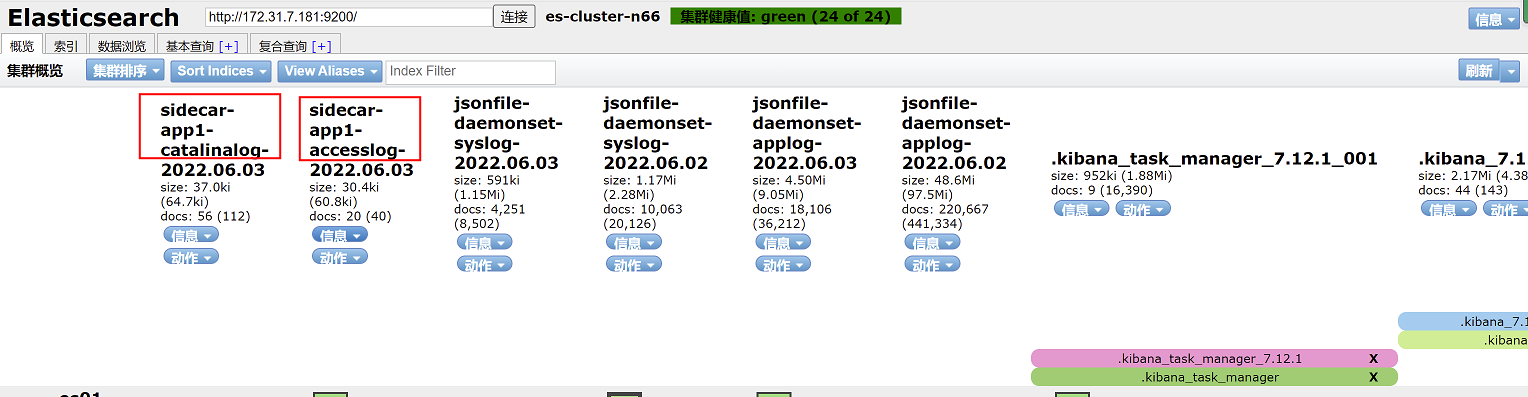
创建索引模式
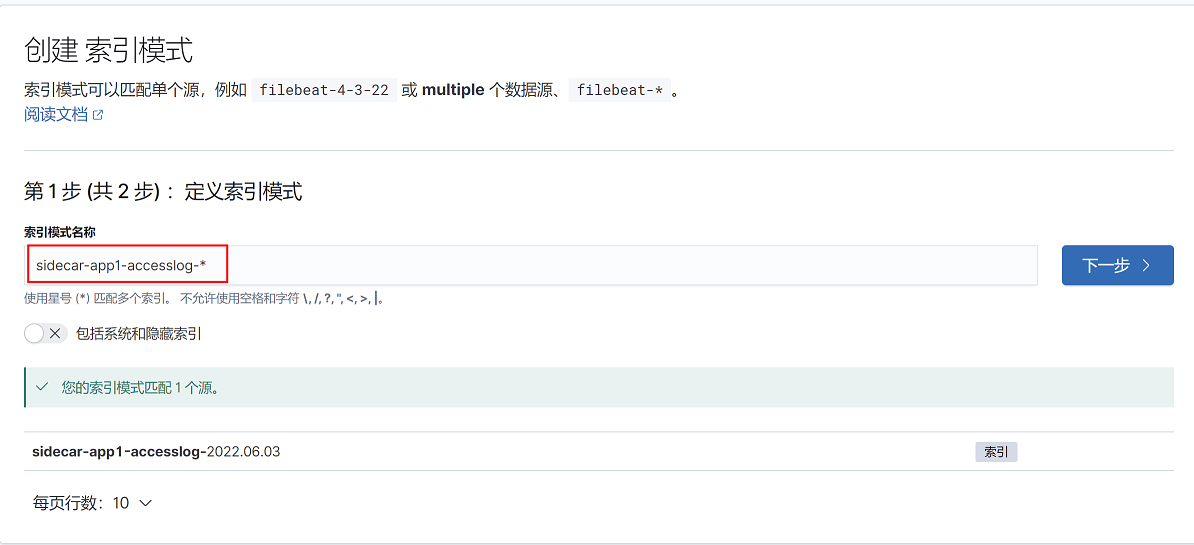
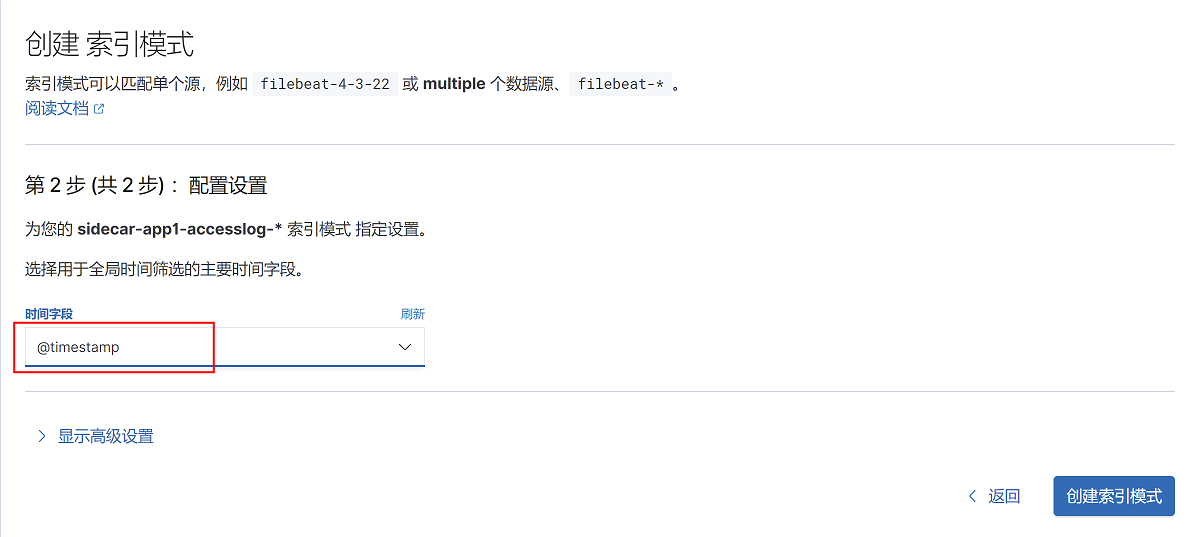
4、选择筛选字段为@timestamp,点击右下角创建索引模式
15.2.2.5.2 添加tomcat容器启动日志索引
1、选择management—management stack
2、kibana-索引模式-创建索引模式
3、填写索引,点击下一步
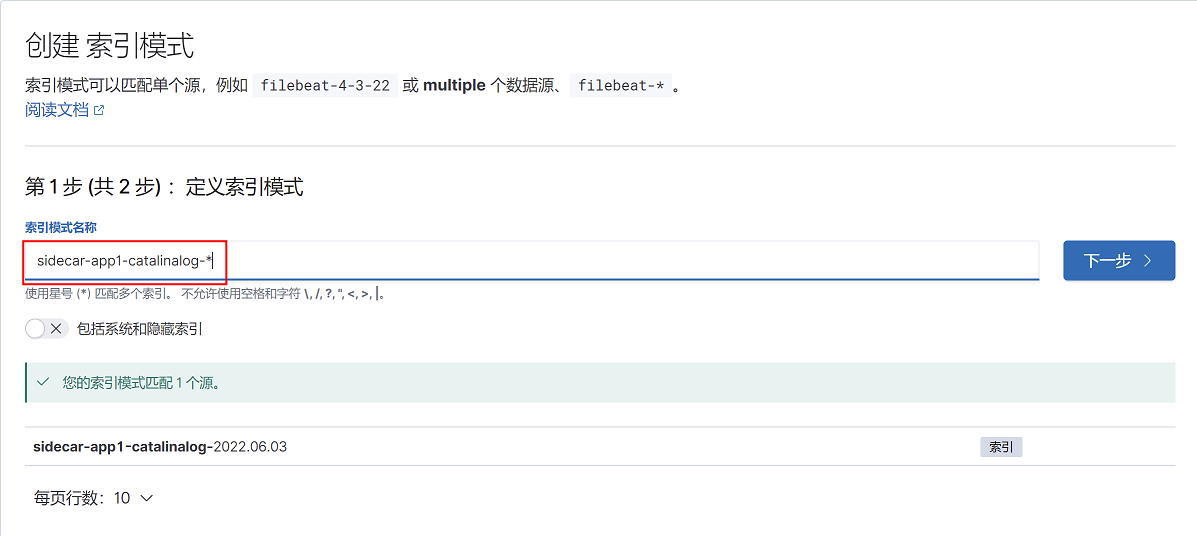
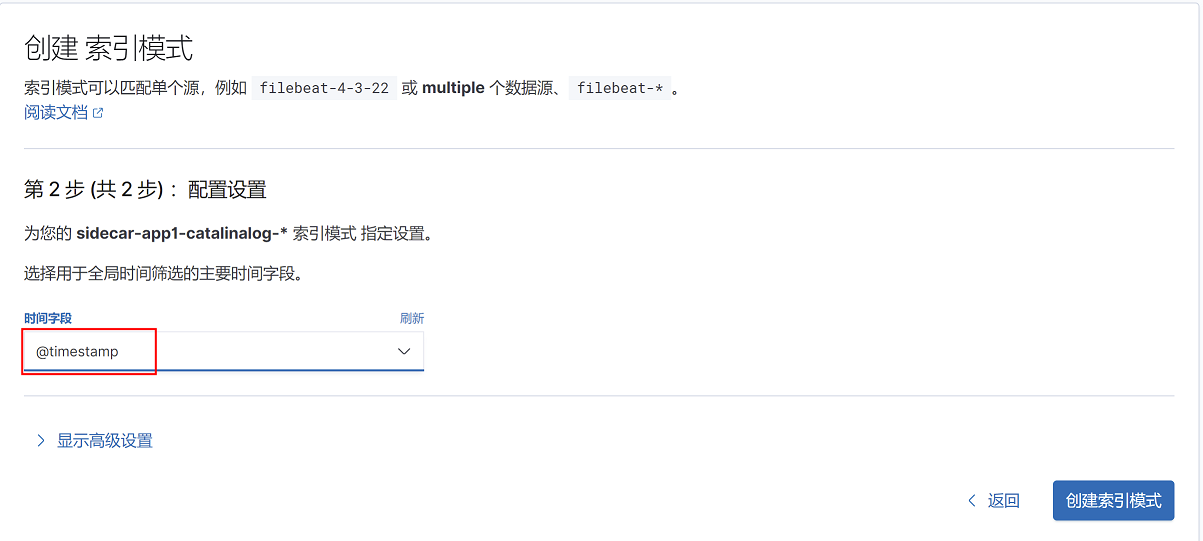
4、选择索引筛选字段@timestamp,点击创建索引模式
15.2.2.5.3 查看日志数据
1、选择analytics---discover
2、可以通过左侧索引选择查看业务容器日志还是宿主机系统日志
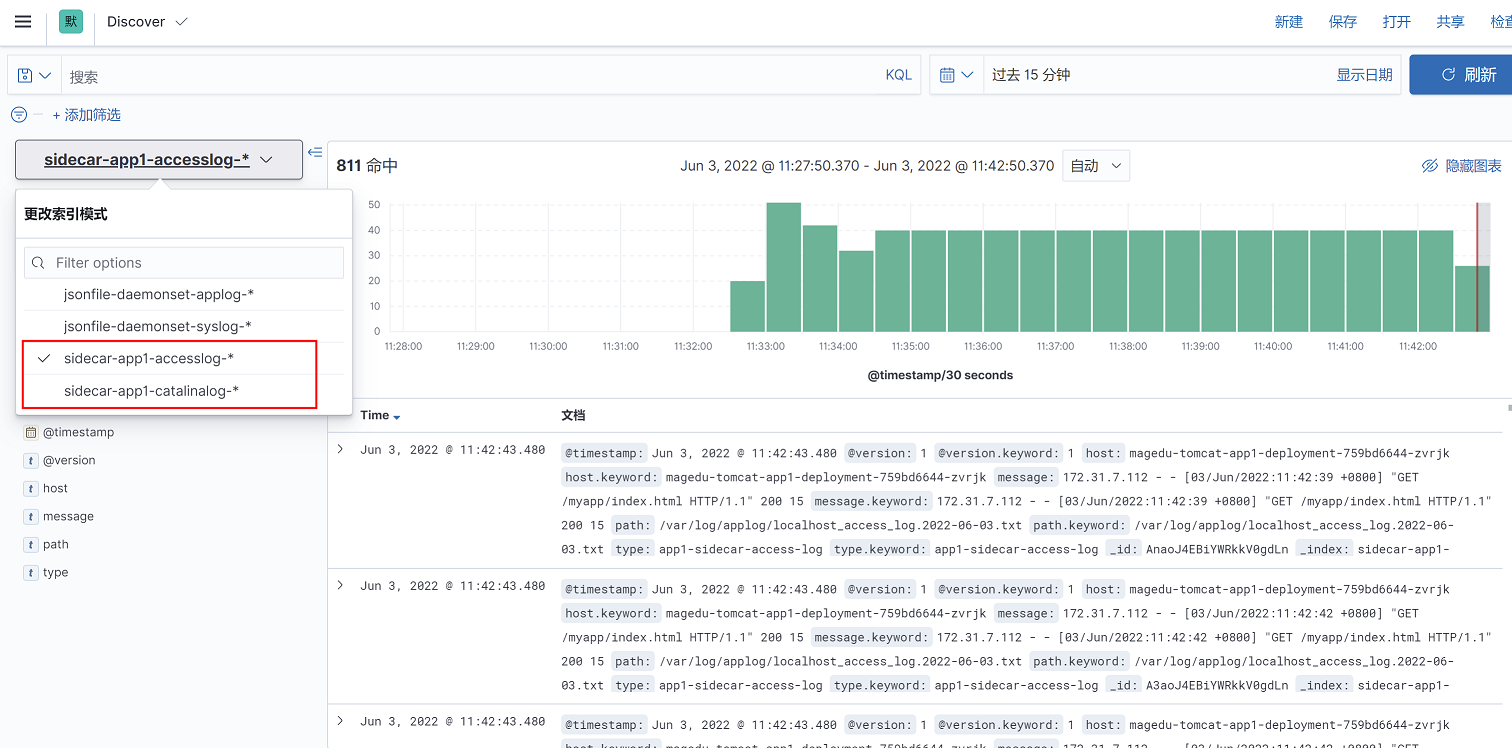
3、日志内容如下:

15.2.3 进程级别日志收集-容器内置进程方式收集
在容器内置日志收集服务进程,收集当前容器的业务容器日志等。
一个容器内除了跑业务进程,还要另外再拉起一个收集日志的filebeat进程。
filebeat相对logstash更加轻量,占用内存较少,因此这种日式收集方式建议使用filebeat
架构图:
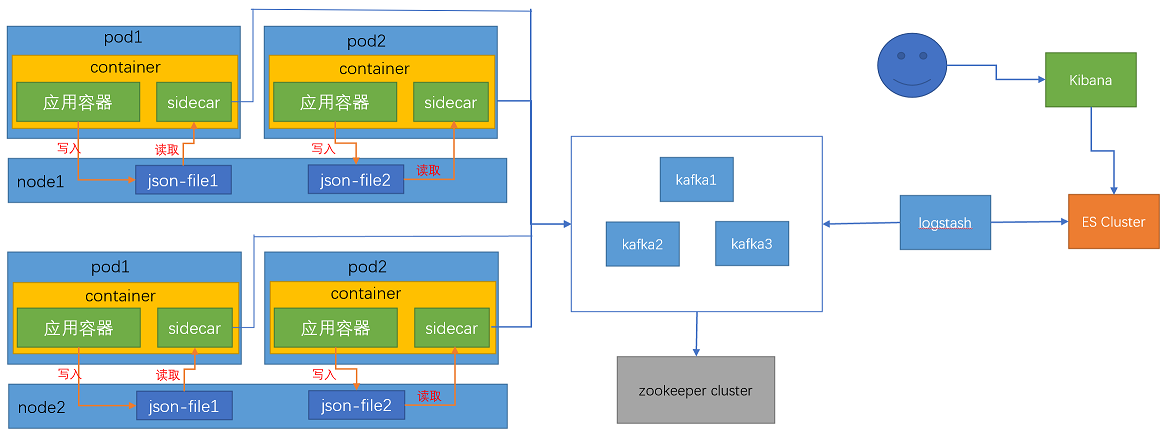
日志收集流程:
(1)容器将访问日志写在容器内,同一个容器内的filebeat进程直接可以获取到业务容器日志
(2)然后将日志写入kafka,logstash从kafka消费日志
(3)然后传递给elasticsearch集群,elasticsearch集群进行日志分析
(4)用户从kibana上获取日志,kibana从elasticsearch上查询获取日志信息,然后展示出来。
15.2.3.1 构建镜像
1、准备Dockerfile需要的文件
(1)准备tomcat catalina.sh,配置tomcat启动参数
vim catalina.sh #该文件可以通过手动拉起一个tomcat容器获取,这里只列出需要添加的配置文件,其他不变。
JAVA_OPTS="-server -Xms1g -Xmx1g -Xss512k -Xmn1g -XX:CMSInitiatingOccupancyFraction=65 -XX:+UseFastAccessorMethods -XX:+AggressiveOpts -XX:+UseBiasedLocking -XX:+DisableExplicitGC -XX:MaxTenuringThreshold=10 -XX:NewSize=2048M -XX:MaxNewSize=2048M -XX:NewRatio=2 -XX:PermSize=128m -XX:MaxPermSize=512m -XX:CMSFullGCsBeforeCompaction=5 -XX:+ExplicitGCInvokesConcurrent -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled"(2)准备tomcat server.xml配置文件
vim server.xml #该文件可以通过手动拉起一个tomcat容器获取,这里只列出修改部分,其他不变,主要是修改tomcat代码存放目录为/data/tomcat/webapp
<Host name="localhost" appBase="/data/tomcat/webapps" unpackWARs="false" autoDeploy="false">(3)准备代码文件
mkdir ./myapp -p
vim ./myapp/ index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>magedu 官网</title>
</head>
<body>
<h1>当前版本v11111111111</h1>
<h1>当前版本v22222222222</h1>
<h1>当前版本v33333333333</h1>
<h1>当前版本v44444444444</h1>
</body>
</html>tar -zcvf app1.tar.gz ./myapp/index.html
(4)准备tomcat运行脚本(启动filebeat和tomcat,并设置守护进程)
vim run_tomcat.sh
#!/bin/bash
/usr/share/filebeat/bin/filebeat -e -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat &
su - tomcat -c "/apps/tomcat/bin/catalina.sh start"
tail -f /etc/hosts为脚本添加可执行权限
chmod a+x run_tomcat.sh
(5)准备filebeat配置文件
vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true #true表示启动该配置段,如果为false表示不启用,配置将不生效
paths:
- /apps/tomcat/logs/catalina.out #定义filebeat收集的日志路径,这里是tomcat的启动日志
fields:
type: filebeat-tomcat-catalina #定义日志类型type,要和logstash中input配置段中type一致,否则logstash将无法从kafka获取日志
- type: log
enabled: true #true表示启动该配置段,如果为false表示不启用,配置将不生效
paths:
- /apps/tomcat/logs/localhost_access_log.*.txt #定义filebeat收集的日志路径,这里是tomcat的访问日志
fields:
type: filebeat-tomcat-accesslog #定义日志类型type,要和logstash中input配置段中type一致,否则logstash将无法从kafka获取日志
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
output.kafka:
hosts: ["172.31.7.161:9092"] #指定kafka集群各节点地址,可以写多个地址
required_acks: 1 #收到消息后是否返回确认值,1表示开启该功能
topic: "filebeat-magedu-app1" #指定topic
compression: gzip #是否启用压缩,这里选择gzip压缩
max_message_bytes: 1000000 #每条消息的最大字节数3、编写dockerfile文件
使用tomcat-base:v8.5.43作为基础镜像(9.1.2.2.3章节构建的镜像),该镜像已经安装filebeat(在9.1.2章节centos基础镜像构建时安装的filebeat),根据需求进行自定义配置(添加tomcat配置文件、添加代码到tomcat、添加启动脚本、添加filebeat配置文件、修改tomcat数据目录和配置文件目录权限为tomcat用户权限)
vim Dockerfile
#tomcat web1
FROM harbor.magedu.local/pub-images/tomcat-base:v8.5.43
ADD catalina.sh /apps/tomcat/bin/catalina.sh
ADD server.xml /apps/tomcat/conf/server.xml
ADD app1.tar.gz /data/tomcat/webapps/myapp/
ADD run_tomcat.sh /apps/tomcat/bin/run_tomcat.sh
ADD filebeat.yml /etc/filebeat/filebeat.yml
RUN chown -R tomcat.tomcat /data/ /apps/
EXPOSE 8080 8443
CMD ["/apps/tomcat/bin/run_tomcat.sh"]4、编写构建镜像的脚本
vim build-commond.sh
#!/bin/bash
TAG=$1
docker build -t harbor.magedu.local/magedu/tomcat-app1:${TAG} .
sleep 3
docker push harbor.magedu.local/magedu/tomcat-app1:${TAG}5、运行脚本,构建镜像
bash build-command.sh 20220603_153500 #需要添加位置变量作为版本号,这里以时间戳作为版本号
15.2.3.2 k8s部署容器
1、编写 yaml文件
vim 3.tomcat-app1.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app1-filebeat-deployment-label
name: magedu-tomcat-app1-filebeat-deployment
namespace: magedu
spec:
replicas: 3
selector:
matchLabels:
app: magedu-tomcat-app1-filebeat-selector
template:
metadata:
labels:
app: magedu-tomcat-app1-filebeat-selector
spec:
containers:
- name: magedu-tomcat-app1-filebeat-container
image: harbor.magedu.local/magedu/tomcat-app1:20220603_153500
#imagePullPolicy: IfNotPresent
imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"创建容器
kubectl apply -f 3.tomcat-app1.yaml
为容器配置service
vim 4.tomcat-service.yaml
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-tomcat-app1-filebeat-service-label
name: magedu-tomcat-app1-filebeat-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30092
selector:
app: magedu-tomcat-app1-filebeat-selector创建service
kubectl apply -f 4.tomcat-service.yaml
为了便于演示效果,配置死循环访问tomcat容器产生访问日志(tomcat容器在宿主机172.31.7.111上)
while true ;do curl http://172.31.7.111:40080/myapp/index.html;sleep 0.5 ;done
15.2.3.3 验证:查看日志内容
此时,整个日志收集流程已经完成。
1、通过kafka tool查看kafka集群接收到的日志内容
daemonset容器中logstash将宿主机上容器以及系统日志收集,发送给kafka,我们通过kafka tool工具可以连接到kafka集群,查看数据是否已经生成
可以看到tomcat的tipics,选择显示格式,默认为二进制格式,修改为显示为字符串
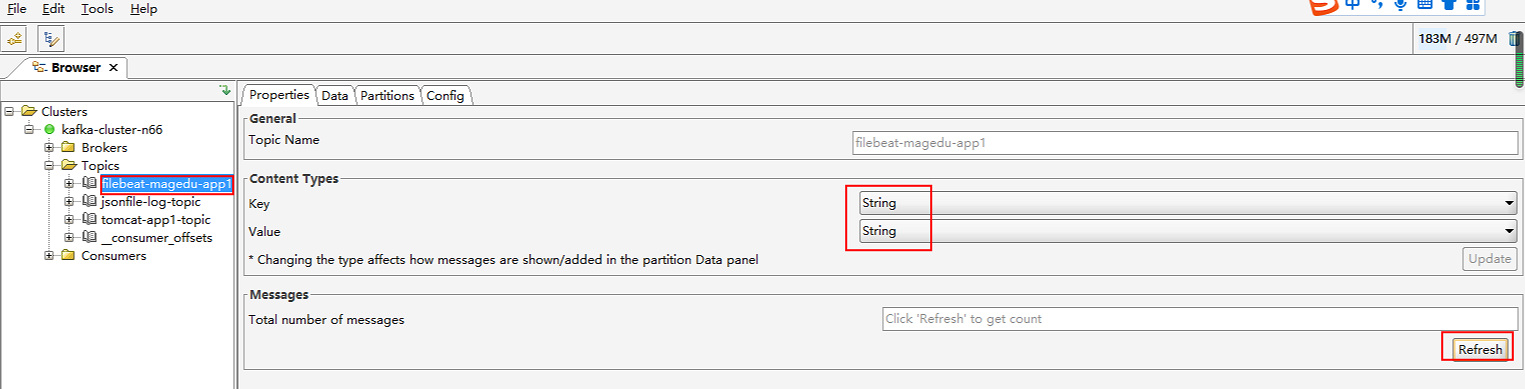
查看kafka集群日志内容,可以看到tomcat的访问日志
查看tomcat容器/var/log/applog/catalina.out日志

查看tomcat容器/var/log/applog/localhost_access_log.2022-06-03.txt日志

调整日志显示最大行数为500(默认只显示50行)
15.2.3.4 修改logstash配置
由于使用的同一个容器内进程方式收集日志,且filebeat配置文件中type类型发生变化,用于消费kafka日志的logstash容器中的配置文件也要做出相应的修改,否则将无法消费kafka集群中的日志
由于logstash已经部署完成,这里只需要修改logstash配置即可
1、编辑配置文件(配置文件需要自己进行编写)
vim filebeat-log-to-es.conf
input {
kafka {
bootstrap_servers => "172.31.7.161:9092,172.31.7.162:9092,172.31.7.163:9092"
topics => ["filebeat-magedu-app1"]
codec => "json"
}
}
output {
if [fields][type] == "filebeat-tomcat-catalina" { #配置日志类型type,要和filebeat中input配置段中type一致,否则logstash将无法从kafka获取日志
elasticsearch {
hosts => ["172.31.7.181:9200","172.31.7.182:9200"]
index => "filebeat-tomcat-catalina-%{+YYYY.MM.dd}"
}}
if [fields][type] == "filebeat-tomcat-accesslog" { #配置日志类型type,要和filebeat中input配置段中type一致,否则logstash将无法从kafka获取日志
elasticsearch {
hosts => ["172.31.7.181:9200","172.31.7.182:9200"]
index => "filebeat-tomcat-accesslog-%{+YYYY.MM.dd}"
}}
}
配置参数说明:
input配置:
指定kafka集群个节点地址,指定topics,该类型就是在k8s集群中sidecar容器yml文件中引用的topics变量,指定编码为json
output配置:
通过type过来日志,将过滤的日志发送给elasticsearch,hosts指定elasticsearch集群各节点地址,index指定索引,用日期进行区分。这里分别过滤容器日志jsonfile-daemonset-applog和系统日志jsonfile-daemonset-syslog
hosts:
指定elasticsearch集群各节点地址
index:
指定索引格式3、重启服务
systemctl restart logstash
查看启动日志,是否有报错
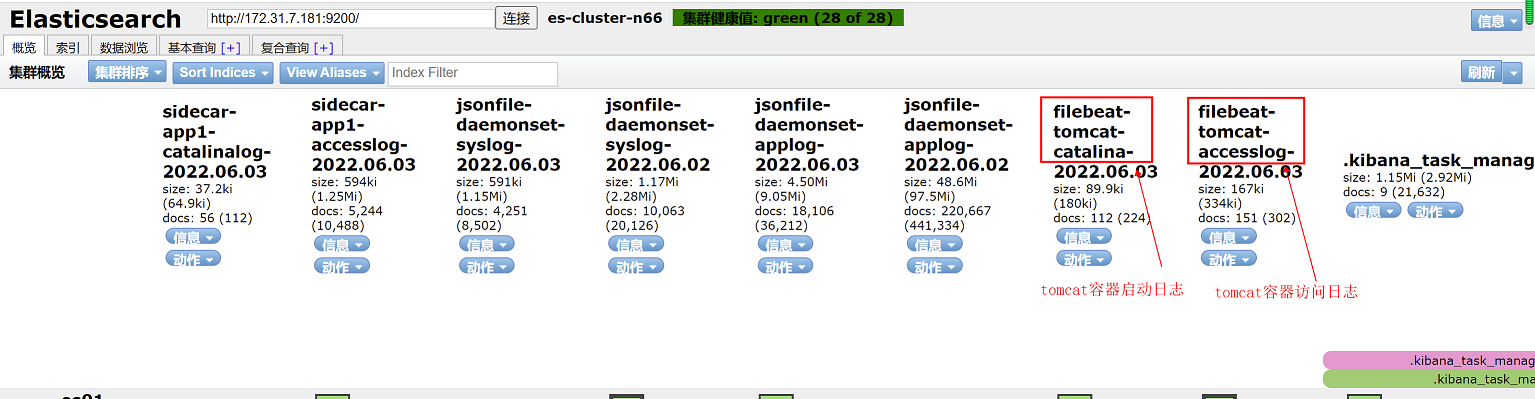
cat /var/log/logstash/logstash-plain.log
4、部署完成后,此时logstash可以消费kafka集群内的日志,通过elasticsearch head插件查看elasticsearch集群中的索引
注意:如果确认各个环节没有问题,但是看不到访问日志和启动日志,有可能是没有新日志产生导致,可以手动访问tomcat或者增加tomcat容器副本来生成访问日志和启动日志,或者手动在启动日志和访问日志中写入一些信息作为新的日志写入
15.2.3.5 配置kibana
通过浏览器访问http://172.31.7.181:5601/
15.2.3.5.1 添加tomcat容器访问日志索引
1、选择management—management stack
2、kibana-索引模式-创建索引模式
3、添加容器日志的索引,然后点击下一步。
再elasticsearch head页面查看索引名称,红框中索引名称,日志以代替,即filebeat-tomcat-accesslog-和filebeat-tomcat-catalina-*
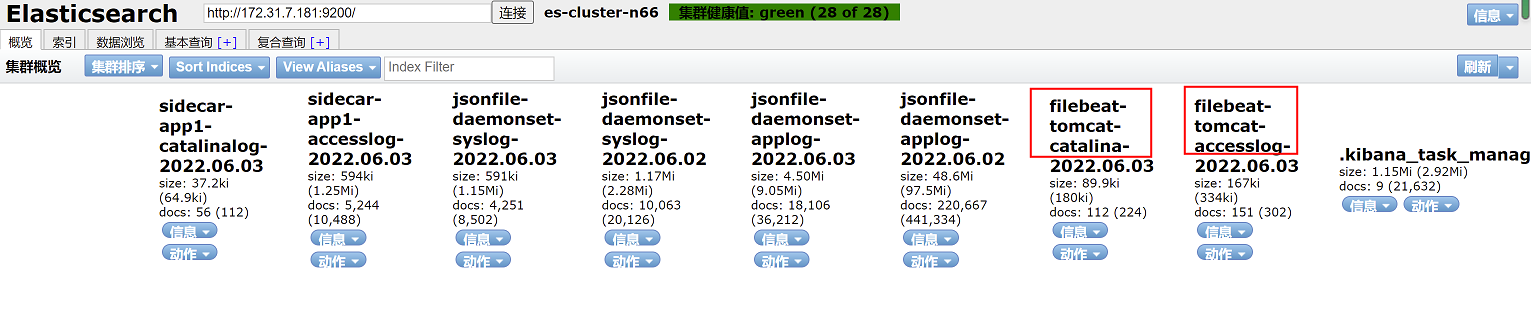
创建索引模式
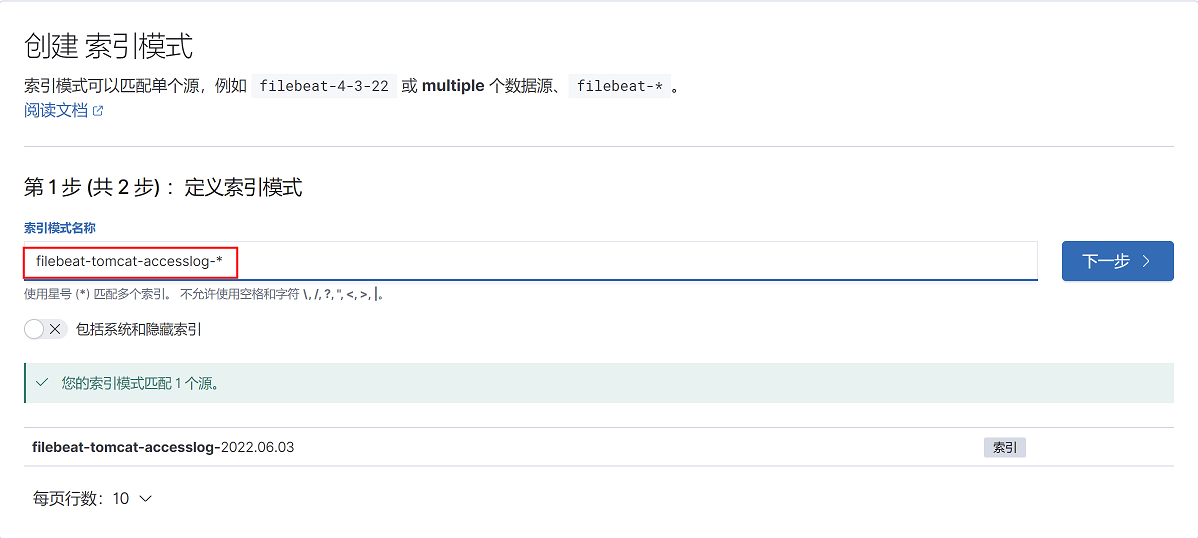
4、选择筛选字段为@timestamp,点击右下角创建索引模式
15.2.3.5.2 添加tomcat容器启动日志索引
1、选择management—management stack
2、kibana-索引模式-创建索引模式
3、填写索引,点击下一步
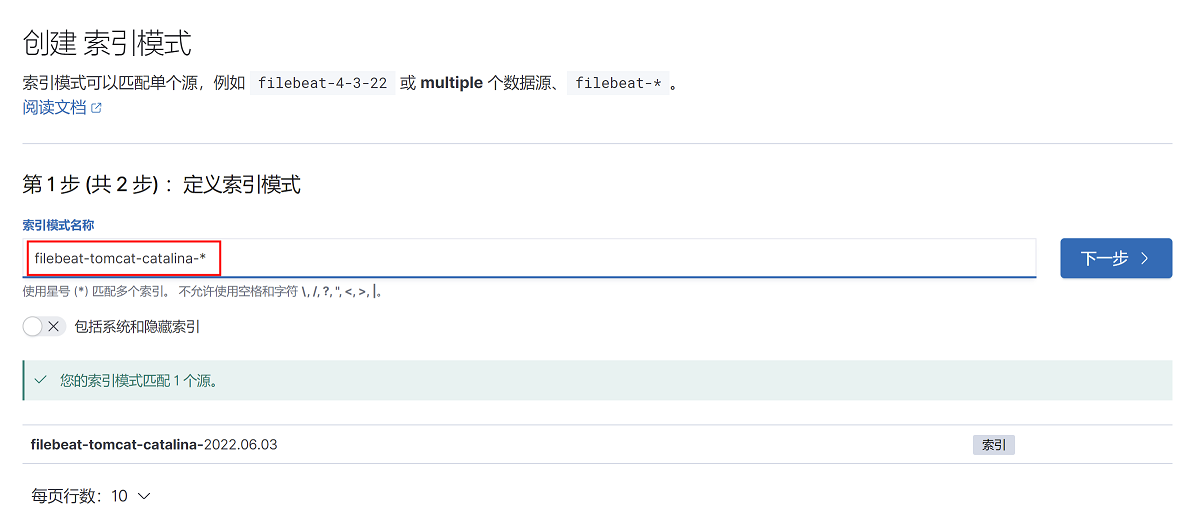
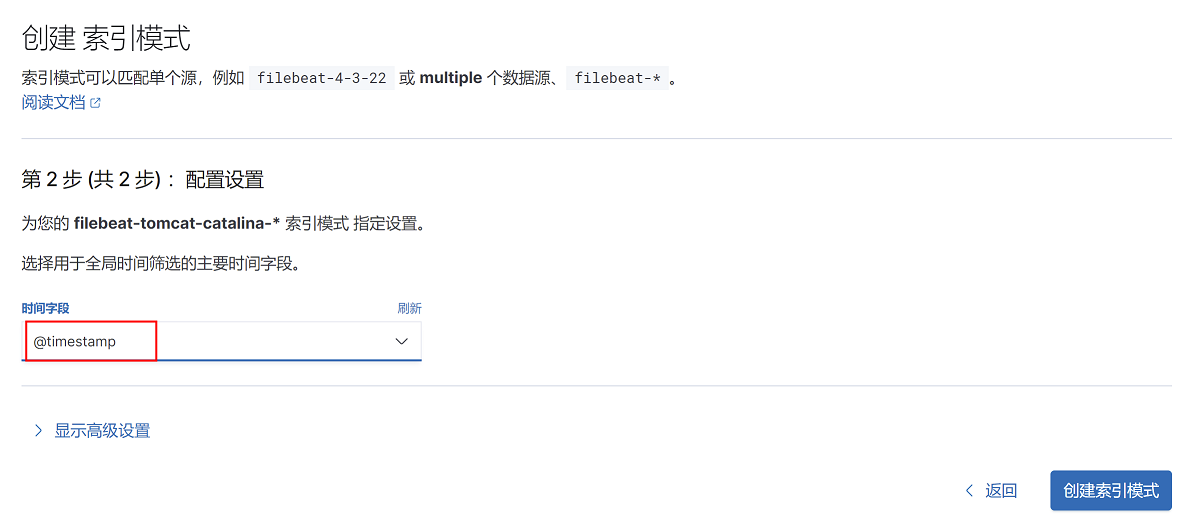
4、选择索引筛选字段@timestamp,点击创建索引模式
15.2.3.5.3 查看日志数据
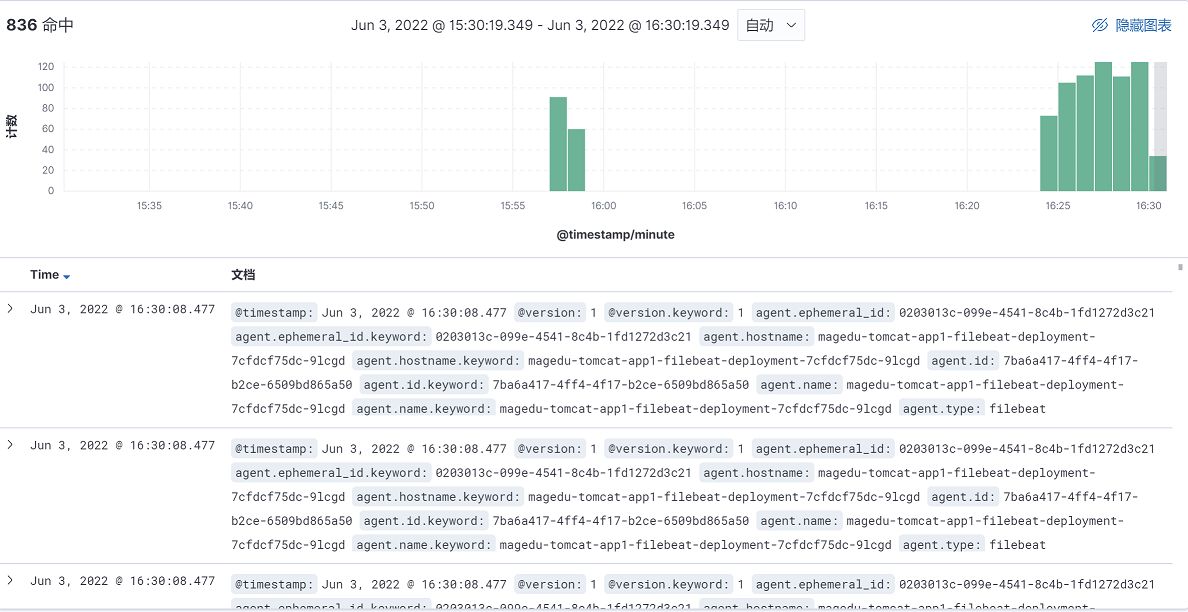
1、选择analytics---discover
2、可以通过左侧索引选择查看业务容器日志还是宿主机系统日志
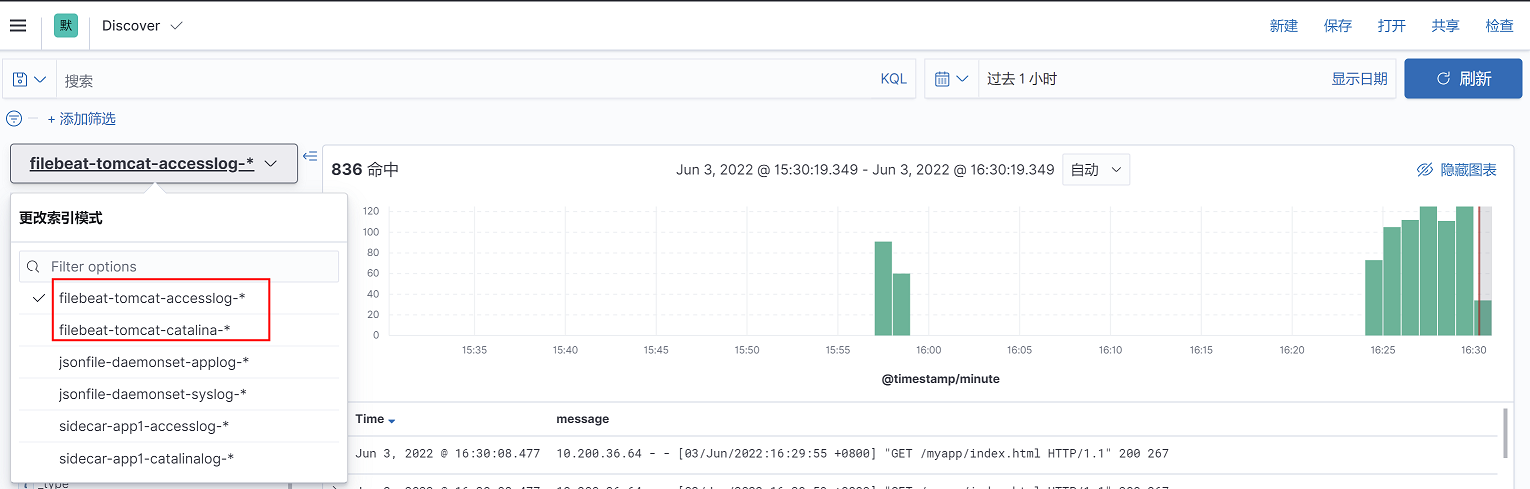
3、日志内容如下:

文章评论