
本章概述
- 通过docekr部署cadvisor
- 通过daemonset部署cadvisor
- daemonset部署node-exporter
- Deployment部署prometheus server
前言
监控Pod指标数据需要使用cadvisor,cadvisor由谷歌开源,cadvisor不仅可以收集一台机器上所有运行的容器信息,还提供基础查询界面和http接口,方便其他组件如Prometheus进行数据抓取,cAdvisor可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。
github链接:https://github.com/google/cadvisor
cAdvisor(容器顾问)让容器用户了解其运行容器的资源使用情况和性能状态,cAdvisor用于收集、聚合、处理和导出有关正在运行的容器的信息,具体来说,对于每个容器都会保存资源隔离参数、历史资源使用情况、完整历史资源使用情况的直方图和网络统计信息,此数据按容器和机器范围导出。
4.1 通过docekr部署cadvisor
4.1.1 部署cadvisor
1、获取镜像
cadvisor镜像在谷歌镜像仓库,这里已经将镜像下载完毕并上传阿里云镜像
可以通过命令直接拉取镜像:
docker pull registry.cn-hangzhou.aliyuncs.com/docker_registry01/cadvisor:v0.39.3
2、在部署cadvisor
docker run -it -d \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
registry.cn-hangzhou.aliyuncs.com/docker_registry01/cadvisor:v0.39.33、访问cadvisor
浏览器输入:172.31.7.101:8080 #172.31.7.101即部署cadvisor的主机ip

访问http://172.31.7.101:8080/metrics,可以查看容器的所有数据
4.1.2 cadvisor指标数据
| 指标名称 | 类型 | 含义 |
|---|---|---|
| container_cpu_load_average_10s | gauge | 过去10秒容器CPU的平均负载 |
| container_cpu_usage_seconds_total | counter | 容器在每个CPU内核上的累积占⽤时间 (单位:秒) |
| container_cpu_system_seconds_total | counter System | CPU累积占⽤时间(单位:秒) |
| container_cpu_user_seconds_total | counter User | CPU累积占⽤时间(单位:秒) |
| container_fs_usage_bytes | gauge | 容器中⽂件系统的使⽤量(单位:字节) |
| container_fs_limit_bytes | gauge | 容器可以使⽤的⽂件系统总量(单位:字节) |
| container_fs_reads_bytes_total | counter | 容器累积读取数据的总量(单位:字节) |
| container_fs_writes_bytes_total | counter | 容器累积写⼊数据的总量(单位:字节) |
| container_memory_max_usage_bytes | gauge | 容器的最⼤内存使⽤量(单位:字节) |
| container_memory_usage_bytes | gauge | 容器当前的内存使⽤量(单位:字节) |
| container_spec_memory_limit_bytes | gauge | 容器的内存使⽤量限制 |
| machine_memory_bytes | gauge | 当前主机的内存总量 |
| container_network_receive_bytes_total | counter | 容器⽹络累积接收数据总量(单位:字节) |
| container_network_transmit_bytes_total | counter | 容器⽹络累积传输数据总量(单位:字节) |
当能够正常采集到cAdvisor的样本数据后,可以通过以下表达式计算容器的CPU使用率:
(1)sum(irate(container_cpu_usage_seconds_total{image!=""}[1m])) without (cpu) #容器CPU使⽤率
(2)container_memory_usage_bytes{image!=""} #查询容器内存使用量(单位:字节):
(3)sum(rate(container_network_receive_bytes_total{image!=""}[1m])) without(interface) #查询容器网络接收量(速率)(单位:字节/秒):
(4)sum(rate(container_network_transmit_bytes_total{image!=""}[1m])) without(interface) #容器网络传输量 字节/秒
(5)sum(rate(container_fs_reads_bytes_total{image!=""}[1m])) without (device) #容器我呢见系统读取速率 字节/秒
(6)sum(rate(container_fs_writes_bytes_total{image!=""}[1m])) without (device) #容器文件系统写⼊速率 字节/秒cadvisor常用容器监控指标
(1)网络流量
sum(rate(container_network_receive_bytes_total{name=~".+"}[1m])) by (name) #容器网络接收的字节数(1分钟内),根据名称查询 name=~".+"
sum(rate(container_network_transmit_bytes_total{name=~".+"}[1m])) by (name) #容器网络传输的字节数(1分钟内),根据名称查询 name=~".+"
(2)容器 CPU相关
sum(rate(container_cpu_system_seconds_total[1m])) #所用容器system cpu的累计使用时间(1min钟内)
sum(irate(container_cpu_system_seconds_total{image!=""}[1m])) without (cpu) #每个容器system cpu的使用时间(1min钟内)
sum(rate(container_cpu_usage_seconds_total{name=~".+"}[1m])) by (name) * 100 #每个容器的cpu使用率
sum(sum(rate(container_cpu_usage_seconds_total{name=~".+"}[1m])) by (name) *100) #总容器的cpu使用率4.2 通过daemonset部署cadvisor
4.2.1 部署cadvisor
1、获取cadvisor镜像并上传到harbor仓库
(1)拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/docker_registry01/cadvisor:v0.39.3
(2)改标签并上传harbor仓库
docker registry.cn-hangzhou.aliyuncs.com/docker_registry01/cadvisor:v0.39.3 harbor.magedu.local/pub-images/cadvisor:v0.39.3
docker push harbor.magedu.local/pub-images/cadvisor:v0.39.3
2、创建监控专用的namespace
kubectl create ns monitoring
3、创建cadvisor
vim case1-daemonset-deploy-cadvisor.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: cadvisor
namespace: monitoring
spec:
selector:
matchLabels:
app: cAdvisor
template:
metadata:
labels:
app: cAdvisor
spec:
tolerations: #污点容忍,忽略master的NoSchedule
- effect: NoSchedule
key: node-role.kubernetes.io/master
hostNetwork: true #使用宿主机网络,注意防止端口冲突
restartPolicy: Always # 重启策略
containers:
- name: cadvisor
image: harbor.magedu.local/pub-images/cadvisor:v0.39.3
imagePullPolicy: IfNotPresent # 镜像策略
ports:
- containerPort: 8080 #指定监听端口为8080
volumeMounts:
- name: root
mountPath: /rootfs
- name: run
mountPath: /var/run
- name: sys
mountPath: /sys
- name: docker
mountPath: /var/lib/docker
volumes:
- name: root
hostPath:
path: /
- name: run
hostPath:
path: /var/run
- name: sys
hostPath:
path: /sys
- name: docker
hostPath:
path: /var/lib/docker创建cadvisor
kubectl apply -f case1-daemonset-deploy-cadvisor.yaml
查看pod,每个node均存在一个cadvisor

浏览访问cadvisor:172.31.7.111:8080
4.2.2 修改prometheus配置,收集cadvisor数据
1、修改prometheus配置文件,添加k8s集群节点ip和端口
vim /apps/prometheus/prometheus.yml #备注部分为修改内容
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090","172.31.7.191:9100"]
- job_name: "prometheus-node"
static_configs:
- targets: ["172.31.7.192:9100","172.31.7.193:9100"]
- job_name: "prometheus-container" #以下几行到行尾为修改内容
static_configs:
- targets: ["172.31.7.101:8080","172.31.7.102:8080","172.31.7.103:8080","172.31.7.111:8080","172.31.7.112:8080","172.31.7.113:8080"]2、执行命令进行热加载
curl -X POST http://172.31.7.201:9090/-/reload
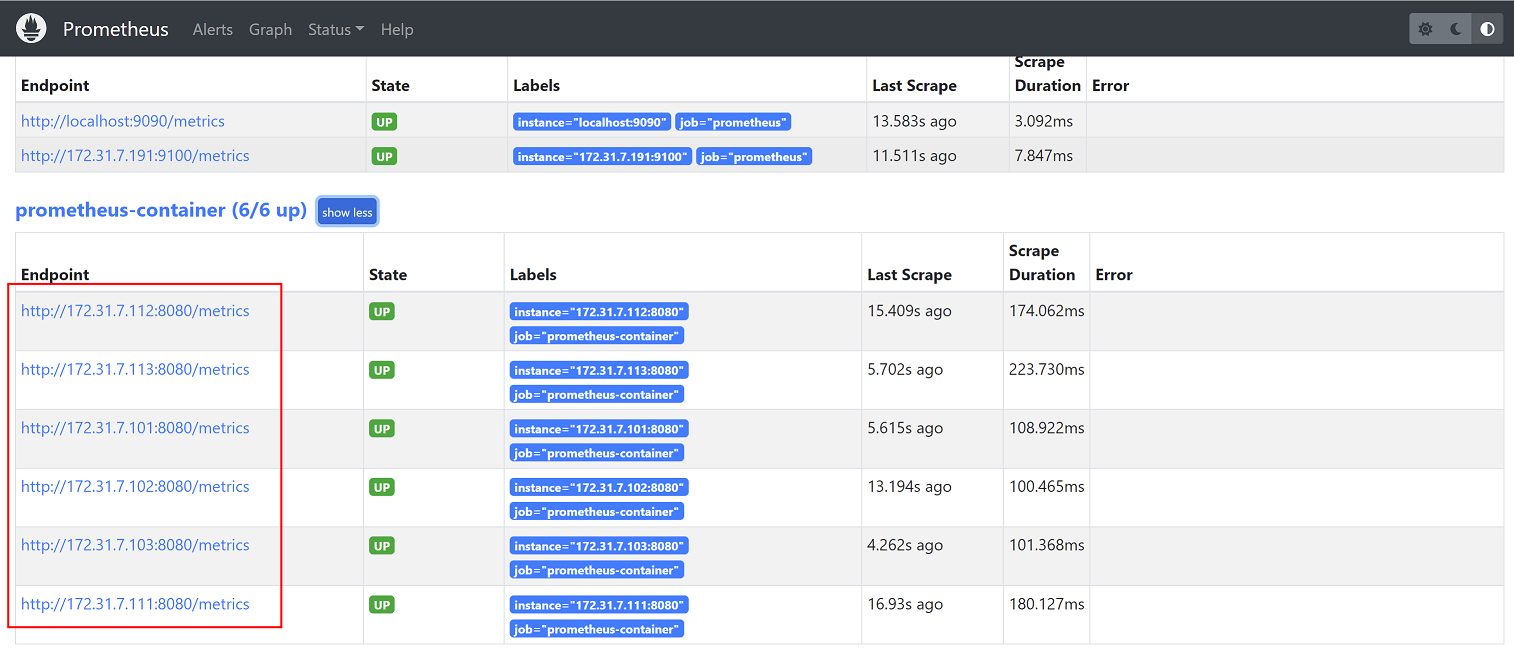
3、在prometheus监控控制台查看,已经获取到数据
4.2.3 Grafana导入pod模板
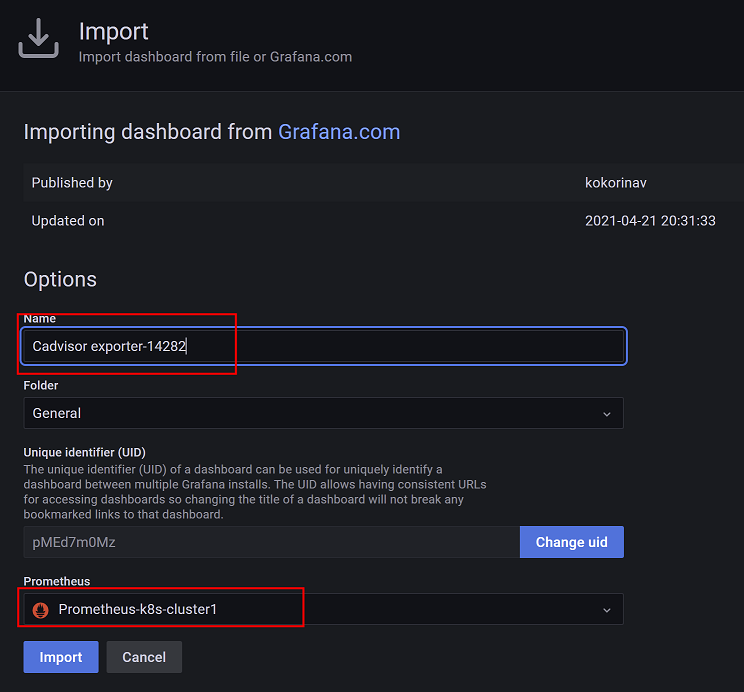
在grafana查看pod数据,要导入pod模板才可以查看
在grafana官网搜索container模板,获取模板id,然后在grafana控制台导入模板id即可
模板查询过程这里不再写出,可以参考2.7.1章节获取模板
pod模板可以使用模板id为:14282,然后在线导入模板
查看监控数据

4.3 daemonset部署node-exporter
在前面章节我们通过只对三台测试用的主机部署了node-exporter,对三台机器做了监控,但并未对k8s集群内的node节点进行监控。
要想对k8s集群内node进行监控,要在node上部署node-exporter,这里通过daemonset方式部署node-exporter对k8s集群的node节点进行监控。
4.3.1 k8s集群部署node-exporter
1、编辑yaml文件
vim case2-daemonset-deploy-node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
k8s-app: node-exporter
template:
metadata:
labels:
k8s-app: node-exporter
spec:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
containers:
- image: prom/node-exporter:v1.3.1
imagePullPolicy: IfNotPresent
name: prometheus-node-exporter
ports:
- containerPort: 9100 #指定端口为9100
hostPort: 9100
protocol: TCP
name: metrics
volumeMounts:
- mountPath: /host/proc
name: proc
- mountPath: /host/sys
name: sys
- mountPath: /host
name: rootfs
args:
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
hostNetwork: true #使用宿主机网络,注意防止端口冲突
hostPID: true创建node-exporter
kubectl apply -f case2-daemonset-deploy-node-exporter.yaml
4.3.2 修改prometheus配置,收集node-exporter数据
1、修改prometheus配置文件,添加k8s集群节点ip和端口
vim /apps/prometheus/prometheus.yml #备注部分为修改内容
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090","172.31.7.191:9100"]
- job_name: "prometheus-node"
static_configs:
- targets: ["172.31.7.192:9100","172.31.7.193:9100"]
- job_name: "prometheus-container"
static_configs:
- targets: ["172.31.7.101:8080","172.31.7.102:8080","172.31.7.103:8080","172.31.7.111:8080","172.31.7.112:8080","172.31.7.113:8080"]
- job_name: "prometheus-node-exporter" #以下几行到行尾为修改内容
static_configs:
- targets: ["172.31.7.101:9100","172.31.7.102:9100","172.31.7.103:9100","172.31.7.111:9100","172.31.7.112:9100","172.31.7.113:9100"]2、执行命令进行热加载
curl -X POST http://172.31.7.201:9090/-/reload
3、在prometheus监控控制台查看,已经获取到数据
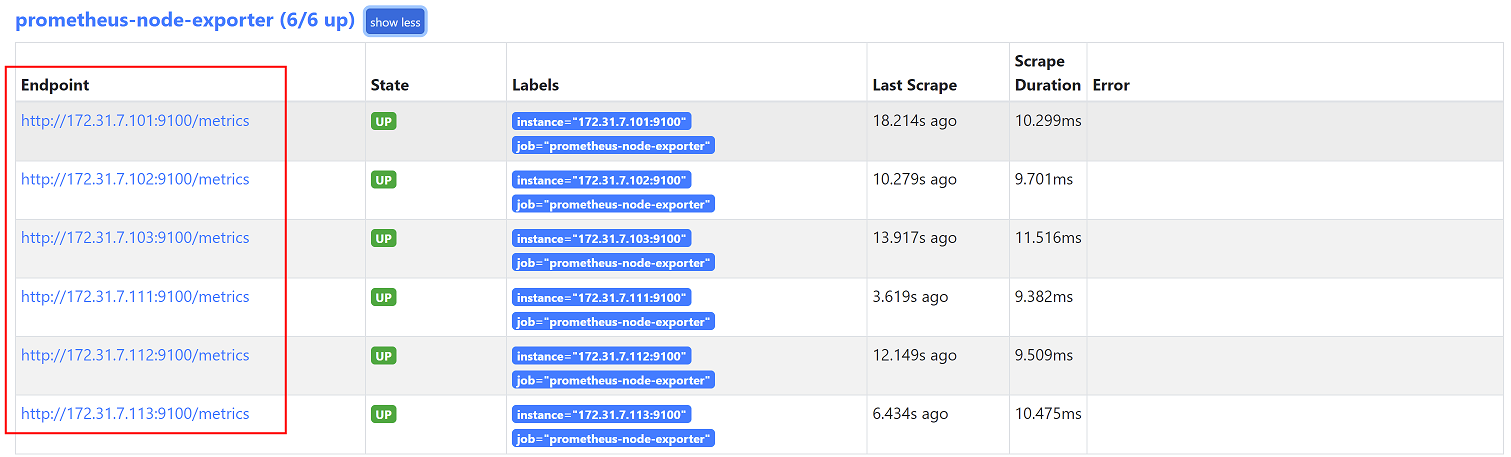
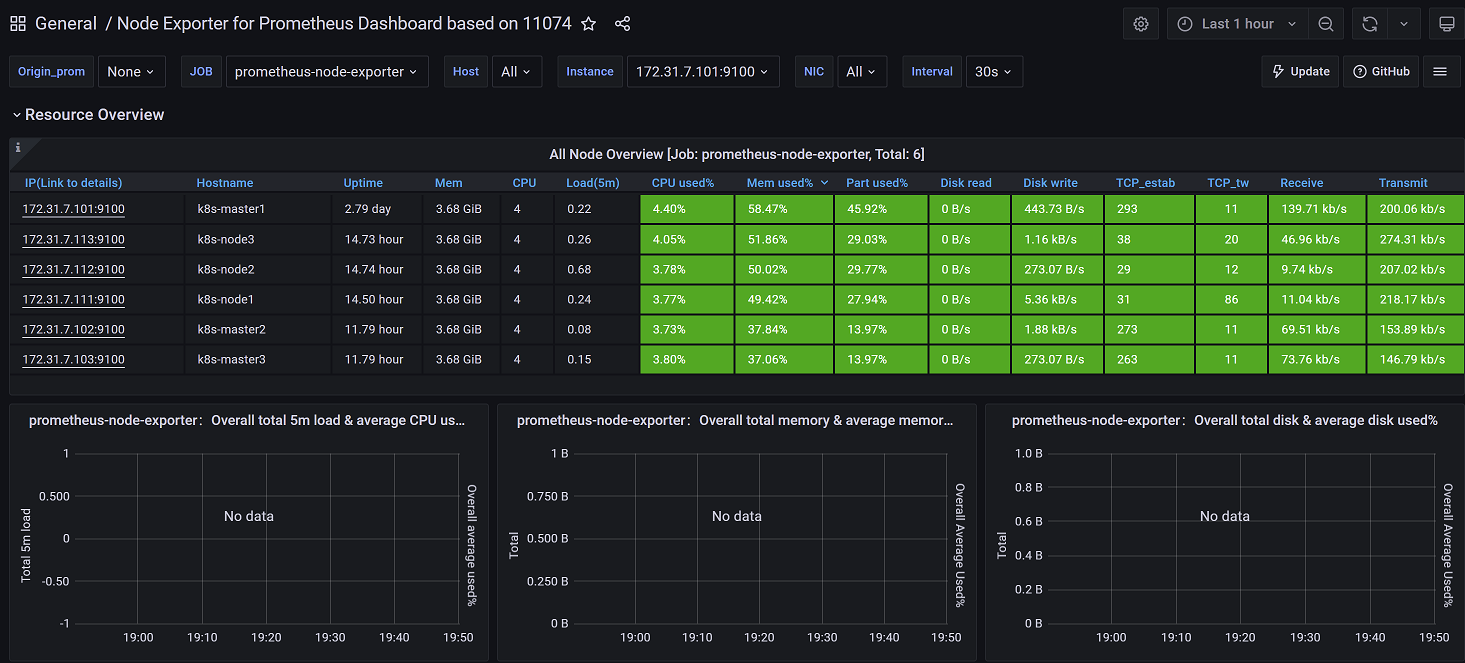
4.3.3 在grafana查看监控数据
由于node监控模板已经导入过了,可以直接查看node监控数据
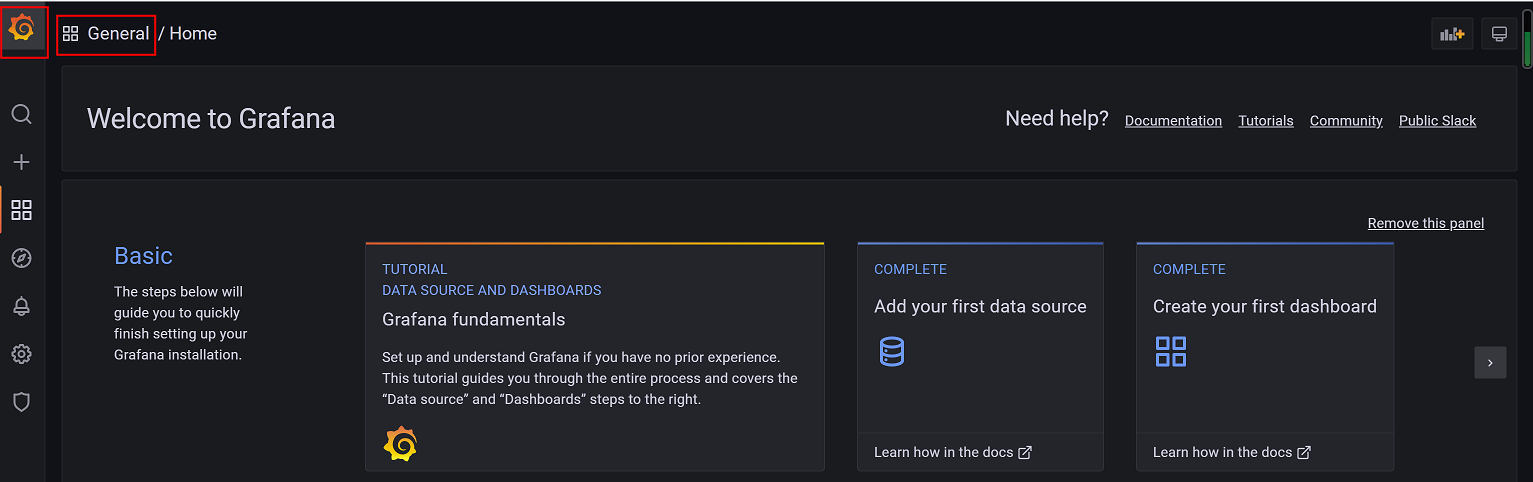
1、点击左上角图标返回首页,点击General
2、选择node模板
3、切换k8s集群对应的job
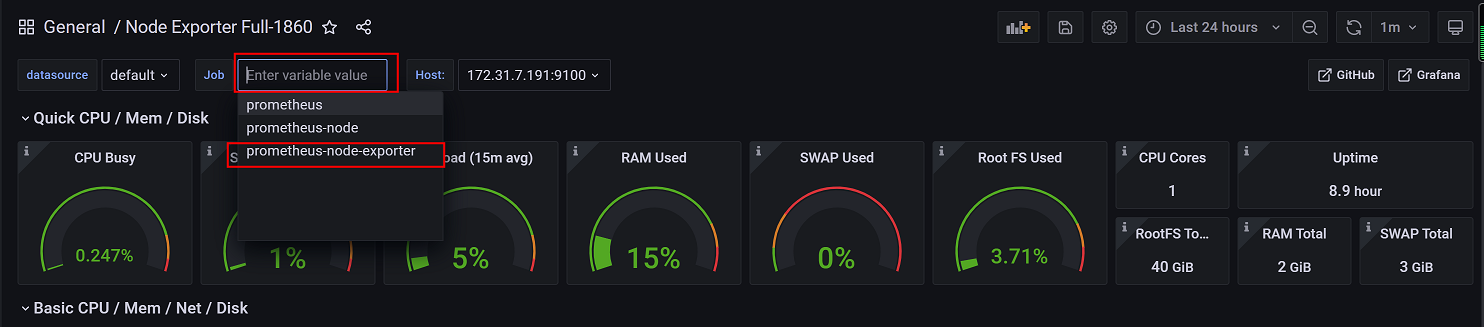
4、查看k8s集群node数据
4.4 Deployment部署prometheus server
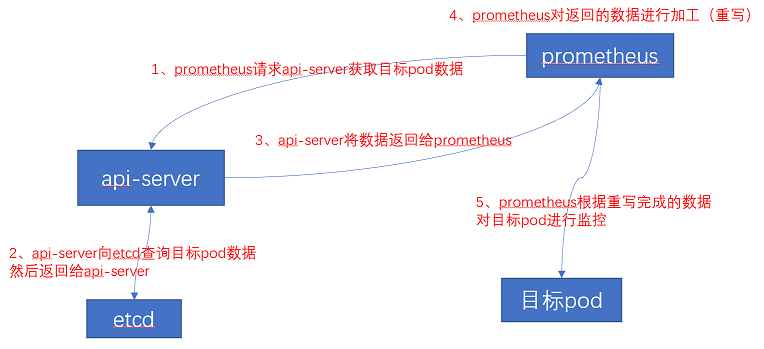
请求过程:
prometheus要提前配置好访问k8s集群的账号,获取可以访问k8s集群的权限
prometheus默认不知道k8s集群内要监控的pod地址、端口等信息
(1)prometheus配置监控信息(要监控的目标pod、端口等),请求k8s集群的api-server发现想要获取的数据
(2)api-server查询etcd获取想要的数据,etcd将数据返回给api-server
(3)api-server将数据返回给prometheus
(4)prometheus对获取到的数据进行加工(即relabel,重写),重写的原因是,api-server返回的数据中有些数据并不是想要获取的,因此需要对数据进行重写
(5)根据重写的数据,对目标pod进行数据抓取和监控4.4.1 部署prometheus server
1、创建configmap,作为prometheus的配置文件prometheus.yml
(1)编写yaml文件
在master1上执行:
vim case3-1-prometheus-cfg.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global: #prometheus全局配置
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs: #数据抓取配置
- job_name: 'kubernetes-node' #配置job_name
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor-n66'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:8080'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
namespaces: #可选指定namepace,如果不指定就是发现所有的namespace中的pod
names:
- myserver
- magedu
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name(2)根据yaml文件进行部署
kubectl apply -f case3-1-prometheus-cfg.yaml
(3)将prometheus运行在node3(172.31.7.113)并提前准备数据目录并授权
在node3节点172.31.7.113上执行:
mkdir -p /data/prometheusdata
chmod 777 /data/prometheusdata
2、创建监控账号(如账号已存在,可忽略该步骤)
在master1上执行
kubectl create serviceaccount monitor -n monitoring
3、对monitoring 账号授权
与cluster-admin角色绑定,用于访问k8s集群,获取k8s集群信息(cluster-admin角色是默认存在的,具有集群管理员权限)
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitoring --clusterrole=cluster-admin --serviceaccount=monitoring:monitor
4、创建deployment控制器,通过deployment控制器创建prometheus
vim case3-2-prometheus-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitoring
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
#matchExpressions:
#- {key: app, operator: In, values: [prometheus]}
#- {key: component, operator: In, values: [server]}
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: 172.31.7.113 #通过标签指定,把pod部署到node3节点上
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.36.1 #试用官方镜像
imagePullPolicy: IfNotPresent
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention=720h
- --web.enable-lifecycle #添加动态配置参数,可以通过传参方式热加载prometheus的配置
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/prometheus.yml #通过挂载configmap作为prometheus的配置文件
name: prometheus-config
subPath: prometheus.yml
- mountPath: /prometheus/
name: prometheus-storage-volume
volumes:
- name: prometheus-config
configMap: #指定configmap
name: prometheus-config
items:
- key: prometheus.yml
path: prometheus.yml
mode: 0644
- name: prometheus-storage-volume #指定prometheus的数据存储目录
hostPath:
path: /data/prometheusdata
type: Directory根据yaml文件进行部署
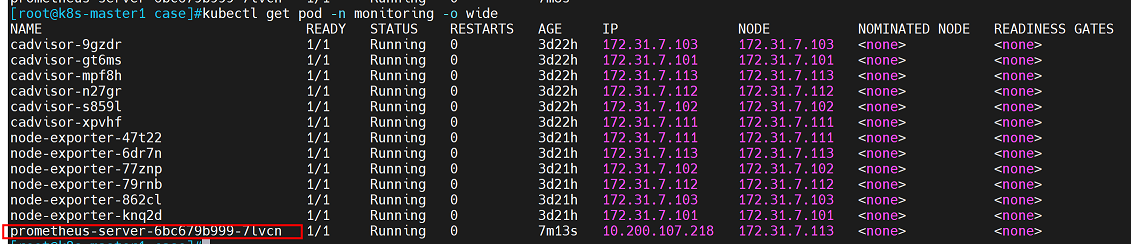
kubectl apply -f case3-2-prometheus-deployment.yaml
查看pod
5、为了可以通过外网访问k8s集群内的Prometheus,需要为prometheus创建service并暴露端口
vim case3-3-prometheus-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitoring
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
nodePort: 39090
protocol: TCP
selector:
app: prometheus
component: server创建service
kubectl apply -f case3-3-prometheus-svc.yaml
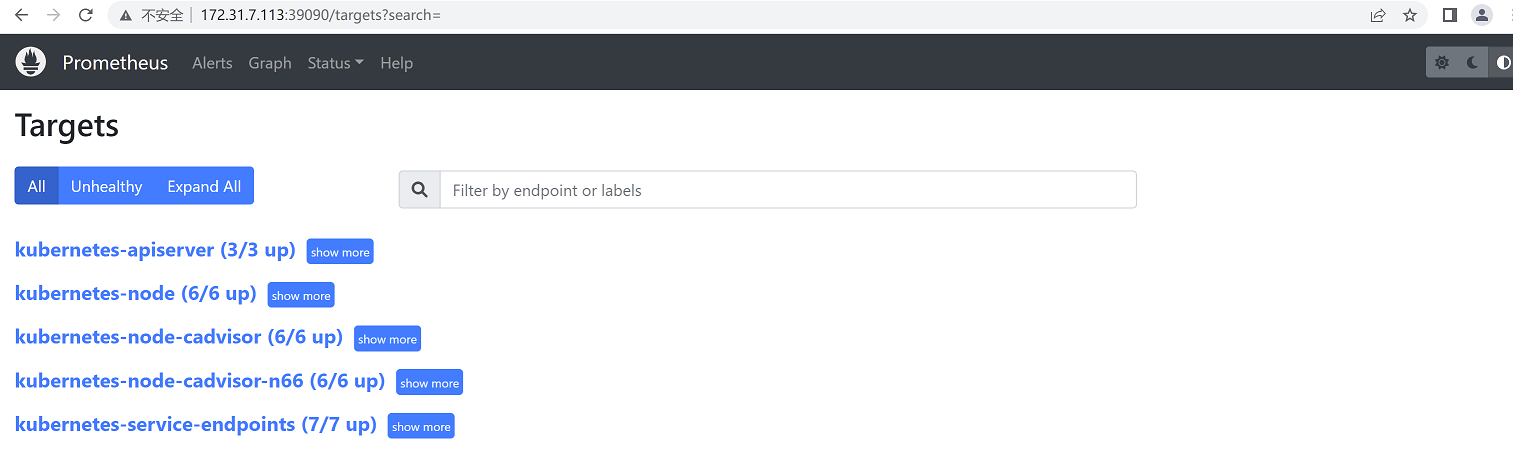
6、验证:访问prometheus
浏览器访问172.31.7.113:39090
注意:prometheus监控页面会出现很多监控项,这是因为在prometheus的配置文件中添加了服务发现的配置,这会在后面讲解服务发现时进行说明
这样一来,node-exporter、cadvisor、prometheus全都部署在了k8s集群中。

文章评论