
本章概述
- 部署方式
- 服务器准备
- 系统环境初始化
- 部署RADOS集群
- 扩展ceph集群实现高可用
前言
github链接:https://github.com/ceph/ceph
ceph官网简要部署过程:http://docs.ceph.org.cn/install/manual-deployment/
注意:在ceph集群部署时要注意操作系统的选择
查看ceph版本历史:https://docs.ceph.com/en/latest/releases/index.html
查看ceph 15即octopus 版本支持的系统:https://docs.ceph.com/en/latest/releases/octopus/
ceph从O版(即V15.2.x版本)开始对centos7半支持,即部分功能支持,部分功能不支持。centos8完全支持,但centos8版本已经不在更新和维护,Ubuntu完全支持。在O版(即V15.x.x)以前的版本完全支持centos7
在P版(即V16.2.x版本)已经不再支持centos7的操作系统,仅支持centos8版本
3.1 部署方式
ceph-ansible:https://github.com/ceph/ceph-ansible #通过python部署
ceph-salt:https://github.com/ceph/ceph-salt #通过python部署
ceph-container:https://github.com/ceph/ceph-container #通过shell部署
ceph-chef:https://github.com/ceph/ceph-chef #通过Ruby部署
cephadm: https://docs.ceph.com/en/latest/cephadm/ #ceph 官方在 ceph 15 版本以后加入的ceph 部署工具
我们这里通过python部署:ceph-deploy:https://github.com/ceph/ceph-deploy
该部署工具是一个 ceph 官方维护的基于 ceph-deploy 命令行部署 ceph 集群的工具,基于 ssh 执行可以 sudo 权限的 shell 命令以及一些 python 脚本 实现 ceph 集群的部署和管理维护。
Ceph-deploy 只用于部署和管理 ceph 集群,客户端需要访问 ceph,需要部署客户端工具。
3.2 服务器准备
构建可靠的、低成本的、可扩展的、 与业务紧密结合使用的高性能分布式存储系统
3.2.1 Ceph 分布式存储集群规划原则/目标
- 较低的 TCO (Total Cost of Ownership,总拥有成本):使用廉价的 X86 服务器。
- 较高的 IOPS (Input/Output Operations Per Second,每秒可完成的读写次数):使用 SSD/PCI-E SSD/NVMe 硬盘提高存储集群数据以提高读写性能。
- 较大的存储空间:使用单块 2T/4T 或更大容量的磁盘,提高单台服务器的总空间,节省服务器总数,降低机柜使用量。
- 较快的网络吞吐:使用 10G、40G、100G 或更快的光纤网络
- 更好的数据冗余:数据可以以三副本机制分别保存到不同的主机,宕机 2 台也不会丢失数据。
3.2.2 服务器硬件选型
官方硬件推荐:http://docs.ceph.org.cn/start/hardware-recommendations/
monitor、mgr、radosgw配置:
4C 8G~16G(小型,专用虚拟机)、8C 16G~32G(中型,专用虚拟机)、16C ~32C/32G~64G(大型/超大型,专用物理机)
MDS配置(相对配置更高一个等级)
8C 8G~16G(小型,专用虚拟机)、16C 16G~32G(中型,专用虚拟机)、326C ~64C/64G~96G(大型、超大型,物理机)
OSD 节点 CPU:
每个 OSD 进程至少有一个 CPU 核心或以上,比如服务器一共 2 颗 CPU 每个 12 核心 24线程,那么服务器总计有 48 核心 CPU,这样最多最多最多可以放 48 块磁盘。
(物理 CPU 数量*每颗 CPU 核心) / OSD 磁盘数量 = X/每 OSD CPU 核心 >= 1 核心 CPU
比如:(2 颗*每颗 24 核心) / 24 OSD 磁盘数量= 2/每 OSD CPU 核心 >= 1 核心 CPU
OSD 节点内存:
OSD 硬盘空间在 2T 或以内的时候每个硬盘 2G 内存,4T 的空间每个 OSD 磁盘 4G 内存,即大约每 1T 的磁盘空间(最少)分配 1G 的内存空间做数据读写缓存。
(总内存/OSD 磁盘总空间)= X > 1G 内存
比如: (总内存 128G/36T 磁盘总空间 )= 3G/每 T > 1G 内存3.2.3 数据分类存储
是否存在访问量不高的业务备份数据(数据库备份、配置文件备份)和访问量比较高的业务数据(静态文件、对象存储数据)都在 ceph 集群存储的场景,如果有的话可以分开不同的磁盘存储。
备份数据:SAS 7.2K/10K/15K 硬盘
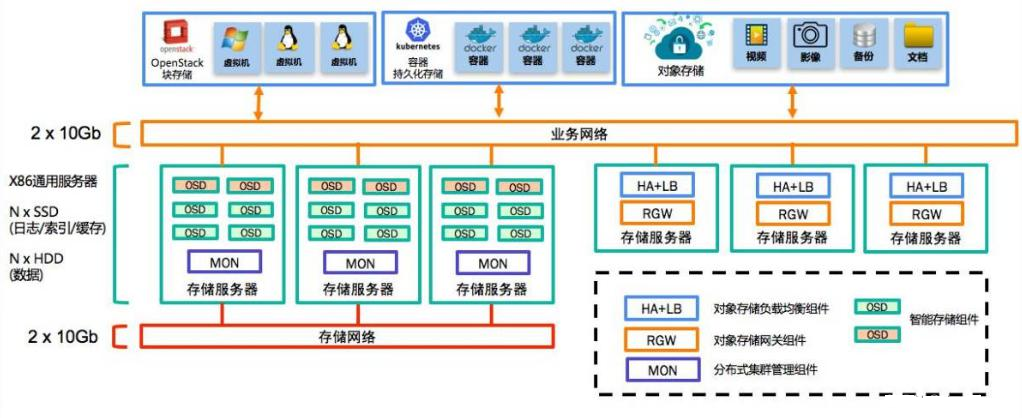
热点数据:SSD 固态硬盘3.2.4 ceph集群规划图
3.2.5 部署环境
实验环境说明:
ceph版本:
此次实验选择部署16.2.X版本,选择版本时尽量选择比较稳定的版本,不用选择较新的版本
系统版本:
各节点操作系统选择ubuntu 18.04.5 LTS 注意:不要用20.04系统(python环境报错)
网络配置:
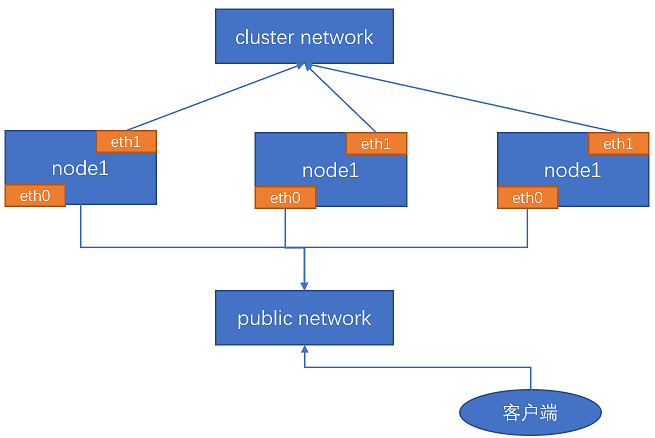
各节点需要两个网卡,分别是业务(客户端)访问使用以及ceph集群内部数据转发使用
eth0: 172.31.7.x/24 public网络,客户端访问使用
eth1: 192.168.7.x/24 cluster网络,ceph集群内部数据同步、数据恢复使用
使用两个网卡的好处:两条网络相互隔离,外部的访问流量不会影响集群内部数据转发,当外部访问网络遭受攻击时,集群内部的数据转发不受影响。当然,ceph集群这两个网络可以合并为同一个网络,但是比较推荐使用两条网络。
各节点配置
(1)推荐环境:需要10台机器(资源充足的情况)
mon: 3台 规格 2c2g
mgr: 2台 规格 2c2g
node(osd): 4台 规格 2c2g
deploy: 1台 规格 2c2g
(2)精简环境:需要5台机器(实验时资源不足可使用该配置)
mon+mgr+deploy: 2台 规格 2c3g
node(osd): 3台 规格 2c2g
OSD节点磁盘配置:
每个服务器两个以上硬盘,硬盘规格:由于是实验,每个硬盘10G以上即可注意:通过vmware虚拟机进行实验配置网卡时,172.31.7.x网段可设置为NAT模式,可以出公网,便于部署;而192.168.7.x网段则可以设置为仅主机模式,仅用于ceph集群内部数据交换使用,无需出公网。
具体网卡配置文件内容如下:
vim /etc/netplan/01-netcfg.yaml #其他主机可根据该配置文件进行修改
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eth0:
addresses: [ 172.31.7.121/24 ]
gateway4: 172.31.7.2
nameservers:
addresses:
- "223.5.5.5"
eth1:
addresses: [ 192.168.7.121/16 ]
nameservers:
addresses:
- "223.5.5.5"修改完成后执行以下命令使配置生效
netplan apply
实验环境具体配置如下:
1、四台服务器作为 ceph 集群 OSD 存储服务器,每台服务器支持两个网络,public 网络针对客户端访问,cluster 网络用于集群管理及数据同步,每台三块或以上的磁盘
172.31.7.126/192.168.7.126 node1 ceph-node1.exampl.local
172.31.7.127/192.168.7.127 node2 ceph-node2.exampl.local
172.31.7.128/192.168.7.128 node3 ceph-node3.exampl.local
172.31.7.129/192.168.7.129 node4 ceph-node4.exampl.local
各存储服务器磁盘划分:
/dev/sdb /dev/sdc /dev/sdd #3个硬盘,各分配20G2、三台服务器作为 ceph 集群 Mon 监视服务器,每台服务器可以和 ceph 集群的 cluster 网络通信。
172.31.7.121/192.168.7.121 mon1 ceph-mon1.exampl.local
172.31.7.122/192.168.7.122 mon2 ceph-mon2.exampl.local
172.31.7.123/192.168.7.123 mon3 ceph-mon3.exampl.local3、两个 ceph-mgr 管理服务器,可以和 ceph 集群的 cluster 网络通信。
172.31.7.124/192.168.7.124 mgr1 ceph-mgr1.exampl.local
172.31.7.125/192.168.7.125 mgr2 ceph-mgr2.exampl.local4、一个服务器用于部署 ceph 集群即安装 Ceph-deploy,也可以和 ceph-mgr 等复用。
172.31.7.120/192.168.7.120 deploy ceph-deploy.example.local
5、创建一个普通用户,能够通过 sudo 执行特权命令,配置主机名解析,ceph 集群部署过程中需要对各主机配置不通的主机名,另外如果是 centos 系统则需要关闭各服务器的防火墙和 selinux。
6、网络环境:
http://docs.ceph.org.cn/rados/configuration/network-config-ref/
架构图如下:
3.3 系统环境初始化
1、时间同步(各服务器时间必须一致)
可设置计划任务定时进行时间同步:
crontab -e #执行命令创建计划任务
*/5 * * * * /usr/sbin/ntpdate time1.aliyun.com &> /dev/null && hwclock -w &> /dev/null2、关闭 selinux 和防火墙(如果是 Centos)
3、配置主机域名解析或通过 DNS 解析
各节点主机名以example.local结尾
3.4 部署RADOS集群
https://mirrors.aliyun.com/ceph/ #阿里云镜像仓库
http://mirrors.163.com/ceph/ #网易镜像仓库
https://mirrors.tuna.tsinghua.edu.cn/ceph/ #清华大学镜像源
3.4.1 仓库准备
3.4.1.1 各节点配置常用镜像仓库
注意:配置时要选择ubuntu18.04版本镜像仓库
链接地址:https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/
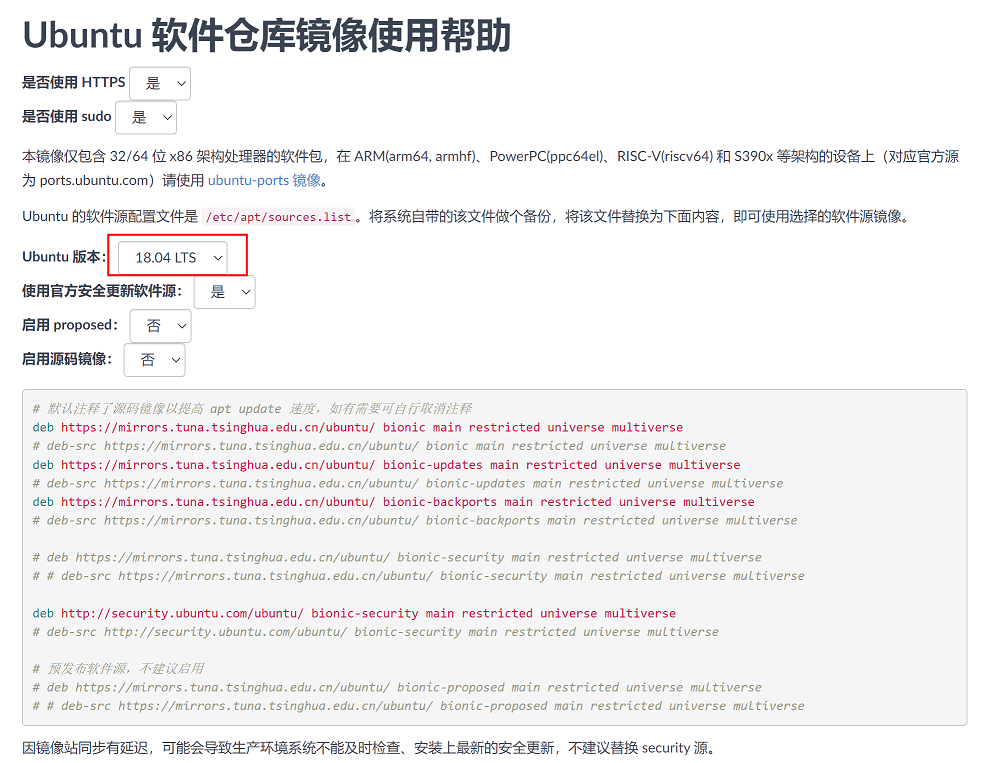
将以上镜像仓库地址复制并粘贴到/etc/pat/sources.list文件中即可
或者执行以下命令:
cat > /etc/apt/sources.list << EOF
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
EOF3.4.1.2 各节点配置ceph yum仓库
以清华大学镜像站为例
登录清华大学镜像站,搜索ceph,点击ceph右侧的问号,即可跳转配置页,根据步骤进行配置
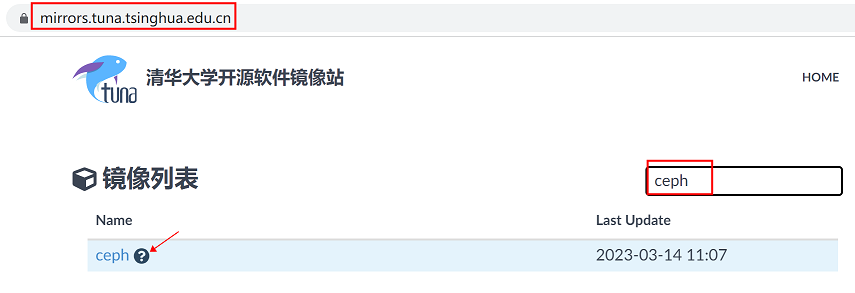
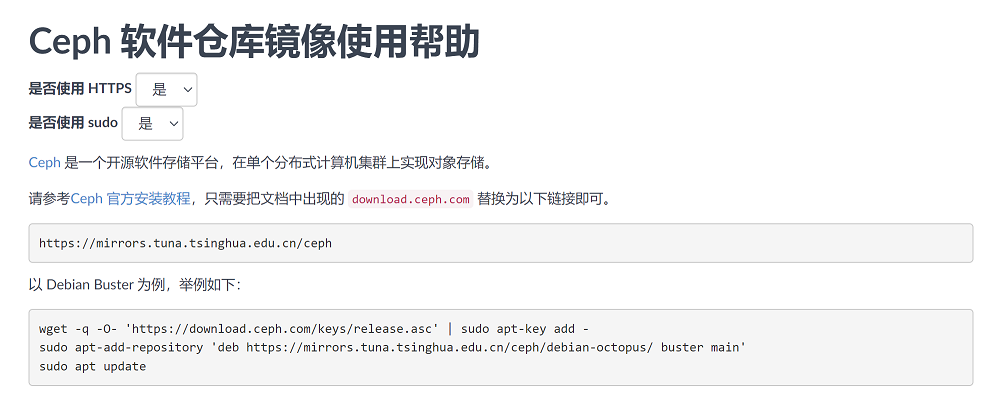
详细配置步骤如下:
1、ceph集群各节点导入 key 文件:(注意ceph集群每个节点都需要导入)
wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -注意:ubuntu镜像仓库中带有ceph,但是版本较低,因此需要配置yum仓库,安装高版本的ceph
2、ceph集群各节点配置ceph仓库
(1)ubuntu18.04
echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list注意:
echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list
以上命令中的pacific是指ceph的版本,ceph 16.2.x对应的版本是p版,即pacific,可在官网进行查看
而bionic是指ubuntu 18.04版本的代号,通过以下命令查看:
lsb_release -a

因此,使用的ubuntu操作系统和ceph如果是其他版本,则可以根据规则进行修改
验证apt仓库(标红部分为ceph镜像源)
cat /etc/apt/sources.list
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main(2)centos7.x
安装ceph-release包
yum install https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm -y各节点配置epel仓库:
yum install epel-release -y3、配置https仓库
(1)由于镜像仓库中使用的是https协议,因此需要配置https仓库,否则将无法使用https协议下的镜像源
或者将镜像仓库中所有的https协议修改http协议
方法一:
在各节点将镜像仓库中所有的https协议修改为http协议,命令如下
sed -i "s/https/http/g" /etc/apt/sources.list方法二:
在各节点安装https仓库,执行命令:
apt -y install apt-transport-https ca-certificates curl software-properties-common(2)更新镜像源
apt update
4、查看ceph版本是否为预期版本,如果跟以下结果不同,说明apt仓库配置不对,需要重新配置
apt-cache madison ceph-common

3.4.2 创建ceph集群部署用户cephadmin
推荐使用指定的普通用户部署和运行 ceph 集群,普通用户只要能以非交互方式执行 sudo命令执行一些特权命令即可,新版的 ceph-deploy 可以指定包含 root 的在内只要可以执行sudo 命令的用户,不过仍然推荐使用普通用户,ceph集群安装完成后会自动创建ceph用户(ceph集群默认会使用ceph用户运行各服务进行,如ceph-osd等),因此推荐使用除了ceph用户之外的比如 ceph、cephuser、cephadmin 这样的用户去管理 ceph 集群。
cephadmin仅用于通过ceph-deploy部署和管理ceph集群的时候使用,比如首次初始化集群和部署集群、添加节点、删除节点等,ceph集群在node节点、mgr等节点会使用ceph用户启动服务进程。
1、在包含 ceph-deploy 节点的存储节点、mon 节点和 mgr 节点等创建 cephadmin 用户。(注意:在每个节点都需要执行以下命令创建用户)
Ubuntu:
groupadd -r -g 2088 cephadmin && useradd -r -m -s /bin/bash -u 2088 -g 2088 cephadmin && echo cephadmin:123456 | chpasswd
Centos:
groupadd cephadmin -g 2088 && useradd -u 2088 -g 2088 cephadmin && echo "123456" | passwd --stdin cephadmin各服务器允许 ceph 用户以 sudo 执行特权命令:
# vim /etc/sudoers
root ALL=(ALL) ALL
cephadmin ALL=(ALL) NOPASSWD: ALL
或者:
~# echo "cephadmin ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers2、配置免秘钥登录:
由于ceph-deploy部署节点需要远程登录到其他节点部署ceph,因此需要配置ceph-deploy节点可以免密登录ceph集群其他节点。
在 ceph-deploy 节点配置允许以非交互的方式登录到各 ceph node/mon/mgr 节点,即在ceph-deploy 节点生成秘钥对,然后分发公钥到各被管理节点:
在ceph-deploy节点执行命令:
su - cephadmin #切换到cephadmin用户
ssh-keygen #生成密钥
ssh-copy-id cephadmin@172.31.7.120
ssh-copy-id cephadmin@172.31.7.121
ssh-copy-id cephadmin@172.31.7.122
ssh-copy-id cephadmin@172.31.7.123
ssh-copy-id cephadmin@172.31.7.124
ssh-copy-id cephadmin@172.31.7.125
ssh-copy-id cephadmin@172.31.7.126
ssh-copy-id cephadmin@172.31.7.127
ssh-copy-id cephadmin@172.31.7.128
ssh-copy-id cephadmin@172.31.7.129注意:本机也要进行免密认证,因为ceph-deploy也会向本机分发ceph配置文件
3.4.3 配置主机名解析
在ceph集群各节点分别添加主机名解析,便于部署
vim /etc/hosts
172.31.7.120 ceph-deploy.example.local ceph-deploy
172.31.7.121 ceph-mon1.example.local ceph-mon1
172.31.7.122 ceph-mon2.example.local ceph-mon2
172.31.7.123 ceph-mon3.example.local ceph-mon3
172.31.7.124 ceph-mgr1.example.local ceph-mgr1
172.31.7.125 ceph-mgr2.example.local ceph-mgr2
172.31.7.126 ceph-node1.example.local ceph-node1
172.31.7.127 ceph-node2.example.local ceph-node2
172.31.7.128 ceph-node3.example.local ceph-node3
172.31.7.129 ceph-node4.example.local ceph-node4验证:
随机找到一个主机名进行ping测试,看是否可以正常解析

3.4.4 安装ceph部署工具
在 ceph 部署服务器172.31.7.120节点安装部署工具 ceph-deploy
查看ceph-deploy版本
root@ceph-deploy:~# apt-cache madison ceph-deploy

可以看到当前apt仓库中已经没有ceph-deploy2.0版本,这是由于ceph-deploy2.0版本已经在apt仓库中移除,因此需要手动在github上下载
github项目地址:https://github.com/ceph/ceph-deploy
PIP下载方法:https://docs.ceph.com/projects/ceph-deploy/en/latest/
Deb下载方法:https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-16.2.9/pool/main/c/ceph-deploy/
可以根据以下步骤安装ceph-deploy2.0版本:
1、安装pip:
root@ceph-deploy:~# apt install python-pip
配置pip加速
root@ceph-deploy:~# mkdir /root/.pip
root@ceph-deploy:~# vim /root/.pip/pip.conf
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com2、使用pip安装ceph-deploy
root@ceph-deploy:~# pip2 install ceph-deploy

3、查看ceph-deploy版本
root@ceph-deploy:~# ceph-deploy --version

3.4.5 初始化mon节点
ceph-deploy用法介绍:http://docs.ceph.org.cn/man/8/ceph-deploy/#id3
$ ceph-deploy --help
new:开始部署一个新的 ceph 存储集群,并生成 CLUSTER.conf 集群配置文件和 keyring
认证文件。
install: 在远程主机上安装 ceph 相关的软件包, 可以通过--release 指定安装的版本。
rgw:管理 RGW 守护程序(RADOSGW,对象存储网关)。
mgr:管理 MGR 守护程序(ceph-mgr,Ceph Manager DaemonCeph 管理器守护程序)。
mds:管理 MDS 守护程序(Ceph Metadata Server,ceph 源数据服务器)。
mon:管理 MON 守护程序(ceph-mon,ceph 监视器)。
gatherkeys:从指定获取提供新节点的验证 keys,这些 keys 会在添加新的 MON/OSD/MD
加入的时候使用。
disk:管理远程主机磁盘。
osd:在远程主机准备数据磁盘,即将指定远程主机的指定磁盘添加到 ceph 集群作为 osd
使用。
repo: 远程主机仓库管理。
admin:推送 ceph 集群配置文件和 client.admin 认证文件到远程主机。
config:将 ceph.conf 配置文件推送到远程主机或从远程主机拷贝。
uninstall:从远端主机删除安装包。
purgedata:从远端主机/var/lib/ceph 删除 ceph 数据,会删除/etc/ceph 下的内容。
purge: 删除远端主机的安装包和所有数据。
forgetkeys:从本地主机删除所有的验证 keyring, 包括 client.admin, monitor, bootstrap 等
认证文件。
pkg: 管理远端主机的安装包。
calamari:安装并配置一个 calamari web 节点,calamari 是一个 web 监控平台。在ceph-deploy节点172.31.7.120上初始化 mon 节点
root@ceph-deploy:~# su - cephadmin
cephadmin@ceph-deploy:~$ mkdir ceph-cluster #该目录用于保存当前集群的初始化配置信息
cephadmin@ceph-deploy:~$ cd ceph-cluster/初始化 mon 节点过程如下:
ceph集群每个服务器需要单独安装 Python2:
sudo apt install python2.7 -y
sudo ln -sv /usr/bin/python2.7 /usr/bin/python2
在部署服务器172.31.7.120上执行:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy new --cluster-network 192.168.7.0/24 --public-network 172.31.7.0/24 ceph-mon1.example.local参数说明
--cluster-network 指定cluster网络,以CIDR格式,即192.168.7.0/24
--public-network 指定public网络,以CIDR格式,即172.31.7.0/24注意:可以指定多个mon节点,以空格隔开,这里为了实验演示需要,只添加一台mon节点,后面会再添加其他mon节点
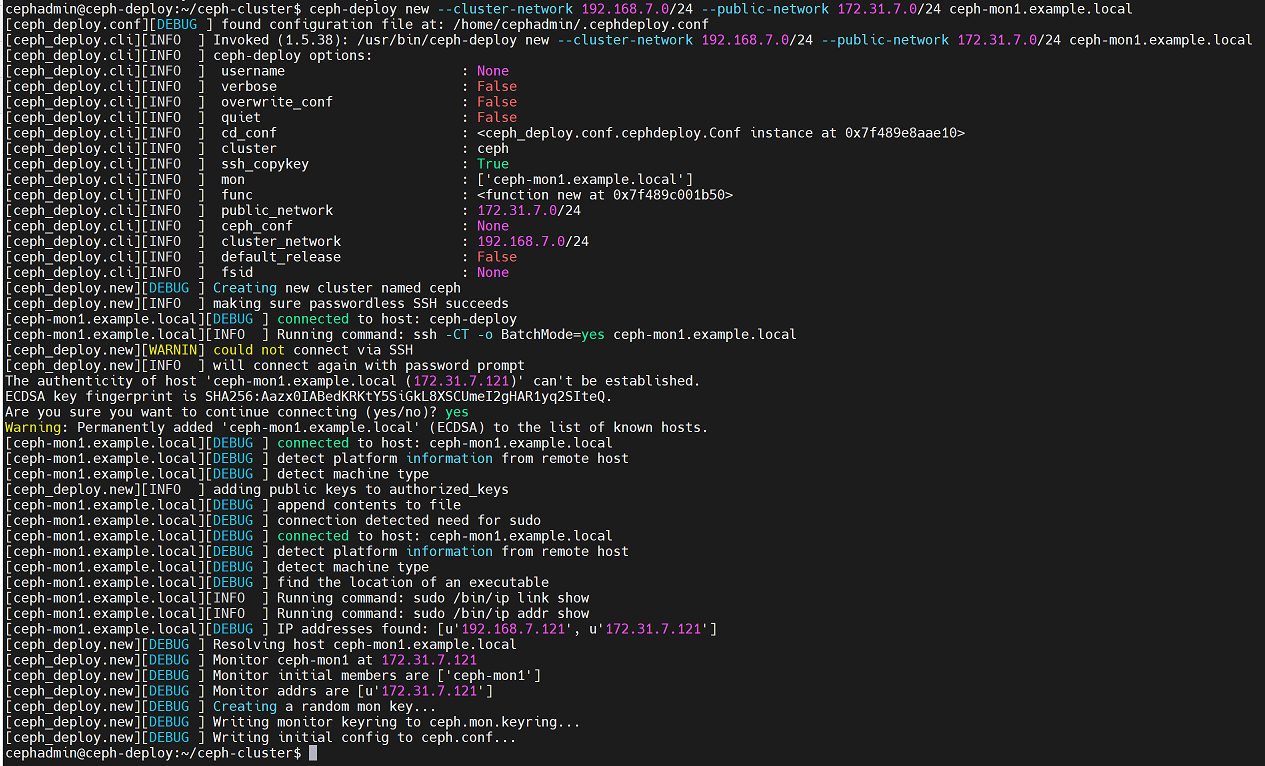
另外,该命令执行后在/home/cephadmin/ceph-cluster目录下生成了一些ceph的配置文件
cephadmin@ceph-deploy:~/ceph-cluster$ ls -lh
total 16K
-rw-rw-r-- 1 cephadmin cephadmin 263 Mar 16 17:23 ceph.conf #自动生成的配置文件
-rw-rw-r-- 1 cephadmin cephadmin 4.1K Mar 16 17:23 ceph-deploy-ceph.log #初始化日志
-rw------- 1 cephadmin cephadmin 73 Mar 16 17:23 ceph.mon.keyring #用于 ceph mon 节点内部通讯认证的秘钥环文件查看ceph.conf文件:
cephadmin@ceph-deploy:~/ceph-cluster$ cat ceph.conf
[global]
fsid = 0540d1e8-3235-494f-8404-33215b5843ea #自动生成的集群id
public_network = 172.31.7.0/24 #public网络
cluster_network = 192.168.7.0/24 #cluster网络
mon_initial_members = ceph-mon1 #以主机名指定mon节点,后续再添加mon节点,可在这里手动添加,以逗号隔开
mon_host = 172.31.7.121 #mon节点的ip地址
auth_cluster_required = cephx #认证类型为cephx,认证所用的key文件为同目录下的ceph.mon.keyring文件
auth_service_required = cephx #同上
auth_client_required = cephx #同上3.4.6 初始化ceph存储节点
初始化存储节点时,注意各个存储节点要提前配置好ceph仓库源,在3.4.1章节已经配置完毕,这里不再赘述。
在ceph-deploy部署节点上执行初始化命令:
命令如下:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node1 ceph-node2 ceph-node3 ceph-node4
参数说明:
--no-adjust-repos #不修改已有的apt仓库源,即使用当前已经配置好的仓库进行安装(默认会使用官方仓库,但是官方仓库安装较慢)
--nogpgcheck #不进行校验- 初始化过程:
此过程会在指定的 ceph node 节点按照串行的方式逐个服务器安装 epel 源和 ceph 源并安装ceph、ceph-osd、ceph-mds、ceph-mon、ceph-radosgw
安装过程中,在ceph集群的node上查看apt进程,可以看到正在安装ceph的几个组件

第一台安装完成后,会询问是否安装第二台,输入yes即可继续安装
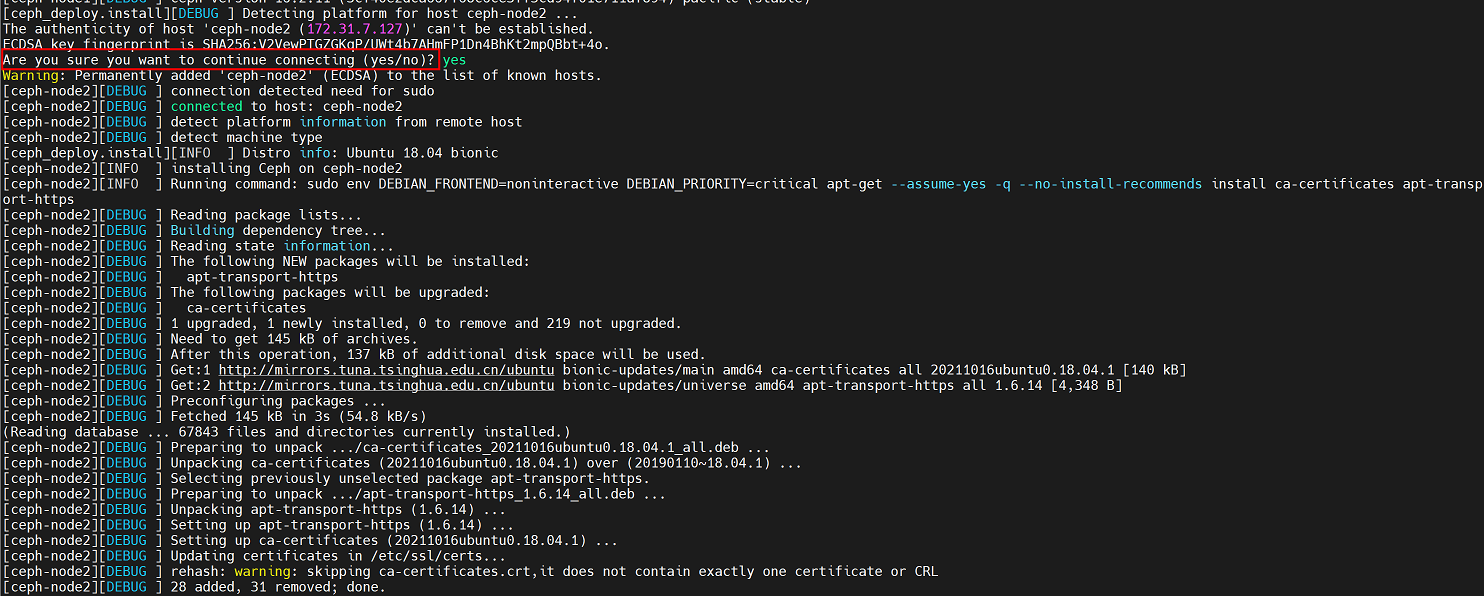
初始化完成
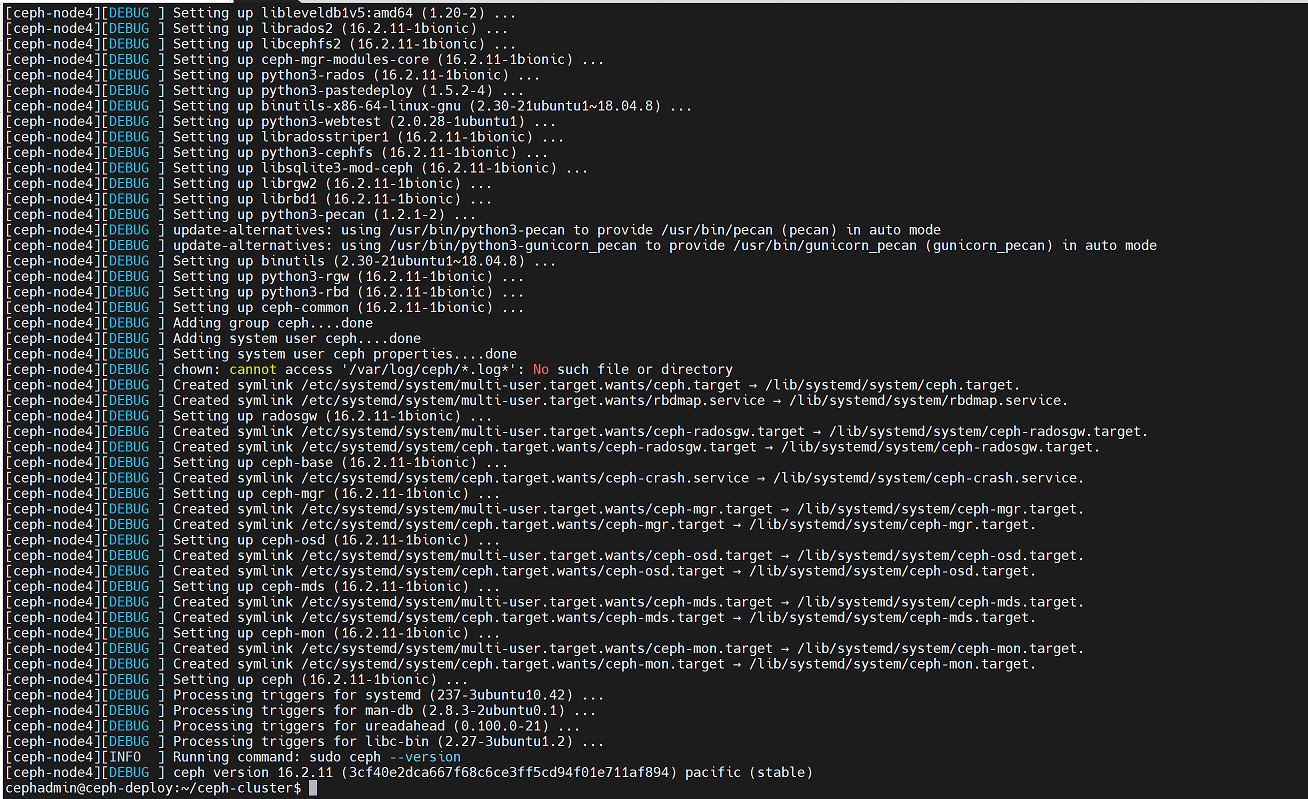
在node节点上查看ceph版本
root@ceph-node1:~# ceph --version

3.4.7 初始化mon节点并生成同步密钥
3.4.7.1 在mon节点安装ceph-mon安装包
为了加快部署进度,在部署服务器ceph-deploy节点对mon节点进行部署之前,可以先在各个mon服务器提前安装ceph-mon的包
1、在三台mon节点(172.31.7.121/122/123)上查看ceph-mon的版本是否为预期版本
apt-cache madison ceph-mon

2、在三台mon节点(172.31.7.121/122/123)上安装ceph-mon
apt install ceph-mon
在安装时,会弹出一个窗口,该窗口无需修改,保持默认即可(直接敲enter键进行下一步直至窗口关闭)

3.4.7.2 mon节点进行初始化
在ceph-deploy部署节点(172.31.7.120)上执行初始化命令:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mon create-initial
该命令会基于deploy节点上的/home/cephadmin/ceph-cluster/ceph.conf配置文件中指定的地址,对mon进行初始化。如果在执行该命令之前mon节点上没有安装ceph-mon的安装包,则会先连接到mon节点上安装ceph-mon,然后再会对mon节点进行初始化。
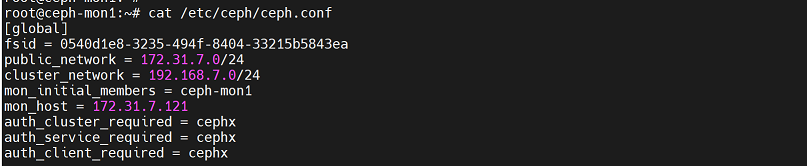
- 验证:
在mon节点172.31.7.121上查看,ceph-mon进程已经被拉起

除此之外,还会把deploy节点上的ceph.conf配置文件同步到mon节点上
cat /etc/ceph/ceph.conf
注意:
由于ceph-deploy节点上的/home/cephadmin/ceph-cluster/ceph.conf配置文件中只指定了172.31.7.121这一台mon节点,因此,此时仅对该mon节点进行了初始化,另外两台还未进行初始化。
另外,如果想要三台mon节点一块初始化,需要在ceph.conf文件中添加三台mon节点的主机名以及ip地址,然后将配置文件重新进行推送,最后执行初始化命令即可
具体配置如下:(备注部分为新增内容)
vim ceph.conf
[global]
fsid = 991e359f-f722-487a-a94d-c0344e4852c3
public_network = 172.31.7.0/24
cluster_network = 192.168.7.0/24
mon_initial_members = ceph-mon1, ceph-mon2, ceph-mon3 #此处ceph-mon2, ceph-mon3为新增内容
mon_host = 172.31.7.121, 172.31.7.122, 172.31.7.123 #此处 172.31.7.122, 172.31.7.123为新增内容
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx3.4.7.3 分发密钥
在客户端访问ceph,执行ceph命令时,需要指定key文件,即ceph.client.admin.keyring文件才可以执行命令。
在 ceph-deploy 节点把配置文件和 admin 密钥拷贝至 Ceph 集群需要执行 ceph 管理命令的节点,从而不需要后期通过 ceph 命令对 ceph 集群进行管理配置的时候每次都需要指定ceph-mon 节点地址和 ceph.client.admin.keyring 文件,另外各 ceph-mon 节点也需要同步ceph 的集群配置文件与认证文件。
另外,ceph有存放密钥文件的默认目录,即/etc/ceph目录,而此时deploy节点上不存在该目录,因此需要安装ceph-common,安装该组件后不仅会自动生成/etc/ceph目录,而且想要执行ceph命令,也需要先安装该公共组件
1、在ceph-deploy节点172.31.7.120安装ceph公共组件ceph-common
在ceph-deploy节点172.31.7.120上执行命令
su – cephadmin
cd ceph-cluster
cephadmin@ceph-deploy:~/ceph-cluster$ sudo apt install ceph-common2、分发密钥
(1)将密钥分发给ceph-deploy节点172.31.7.120
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-deploy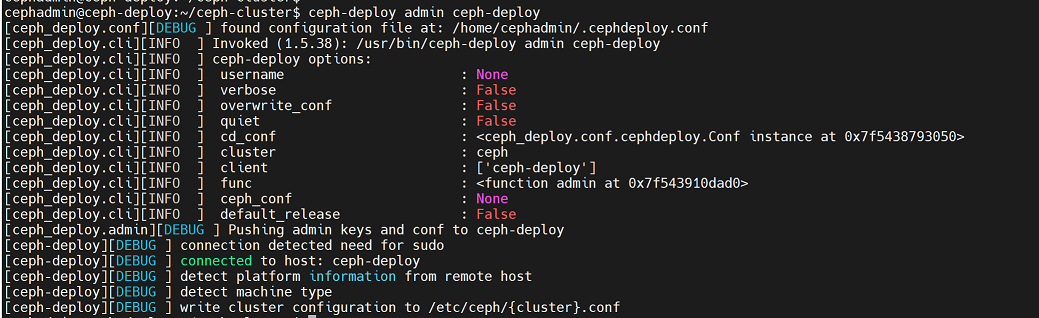
(2)将密钥分发给ceph-node节点(172.31.7.126/127/128/129)
注意:该密钥文件是整个集群admin用户的密钥文件,一旦获取该文件,将可以管理整个ceph集群,因此一定要保管好该文件。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-node1 ceph-node2 ceph-node3 ceph-node4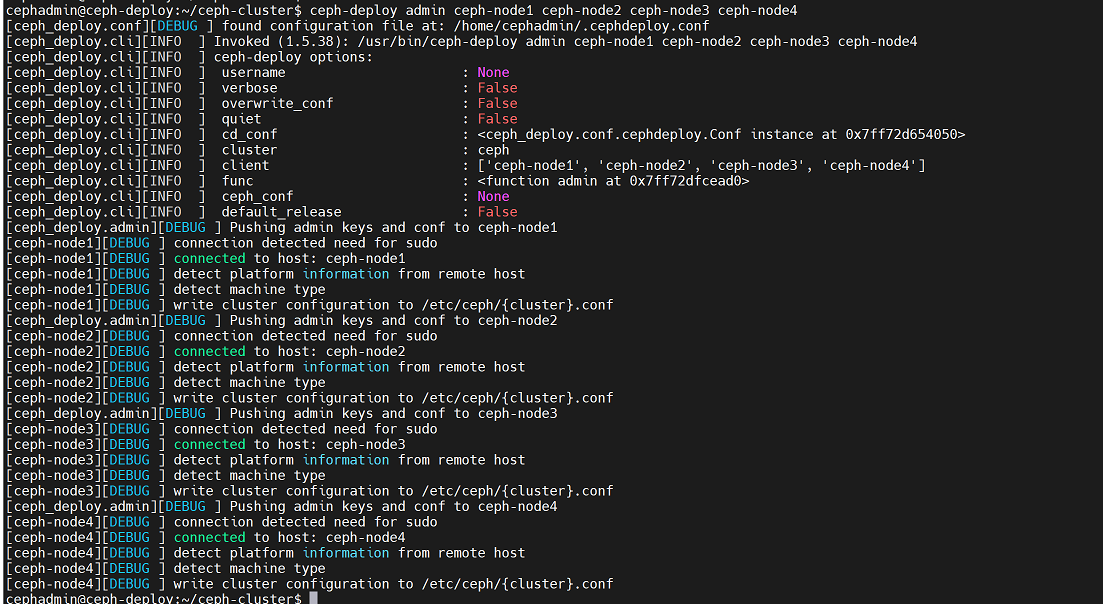
3.4.7.4 验证密钥文件
在ceph-deploy节点查看密钥文件:

在node节点查看密钥文件

可以看到密钥文件已经复制到/etc/ceph目录下,另外/etc/ceph目录也已经自动生成
3.4.7.5 为普通用户授权(修改密钥文件权限)
认证文件的属主和属组为了安全考虑,默认设置为了 root 用户和 root 组,如果需要 cephadmin用户也能执行 ceph 命令,那么就需要对 cephadmin 用户进行授权
分别在ceph-deploy和4台ceph-node节点执行以下命令:
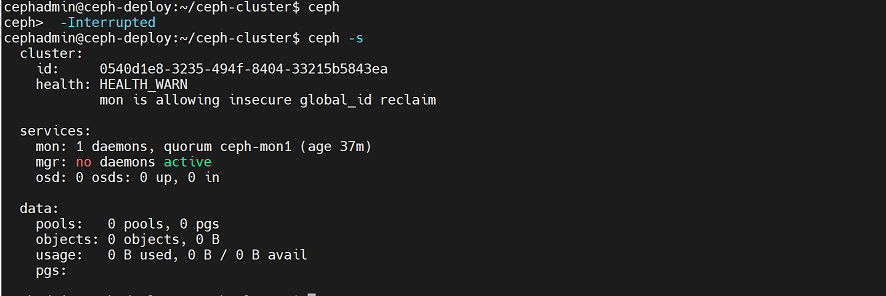
sudo setfacl -m u:cephadmin:rw /etc/ceph/ceph.client.admin.keyring验证:
切换到cephadmin用户,执行命令ceph -s
3.4.8 部署ceph-mgr节点
1、在mgr节点安装ceph-mgr安装包
查看ceph-mgr版本是否为当前最新版本
root@ceph-mgr1:~# apt-cache madison ceph-mgr
分别在两台ceph-mgr节点(172.31.7.124/125)上安装ceph-mgr安装包
root@ceph-mgr1:~# apt install ceph-mgr在安装时,会弹出一个窗口,该窗口无需修改,保持默认即可(直接敲enter键进行下一步直至窗口关闭)

2、在ceph-deploy节点初始化mgr节点
在ceph-deploy节点172.31.7.120上执行命令:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mgr create ceph-mgr1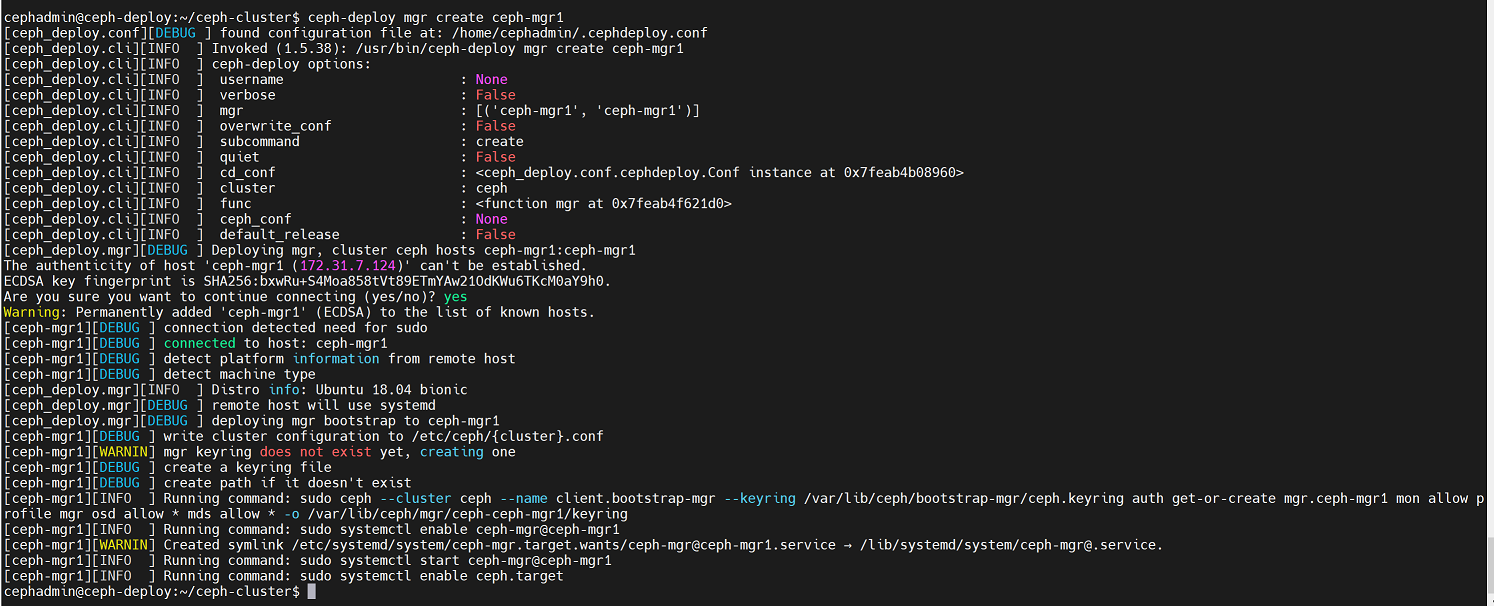
3、验证
在mgr节点查看ceph进程,可以看到ceph-mgr进程已经拉起
root@ceph-mgr1:~# ps -ef |grep ceph

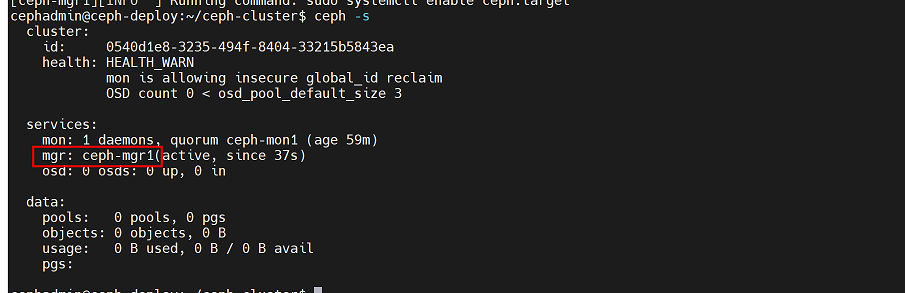
执行ceph -s命令,可以看到ceph-mgr1已经加入集群
cephadmin@ceph-deploy:~/ceph-cluster$ ceph -s
3.4.9 添加OSD节点
3.4.9.1 准备OSD节点
1、osd节点安装运行环境:
在ceph-deploy节点执行以下命令:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node1 #擦除磁盘之前通过 deploy 节点对 node 节点执行安装 ceph 基本运行环境
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node3
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node42、列出node节点磁盘(本次实验中,每个node节点除系统盘sda之外,均添加3块磁盘sdb、sdc、sdd)
su – cephadmin
cd ceph-cluster
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list ceph-node1 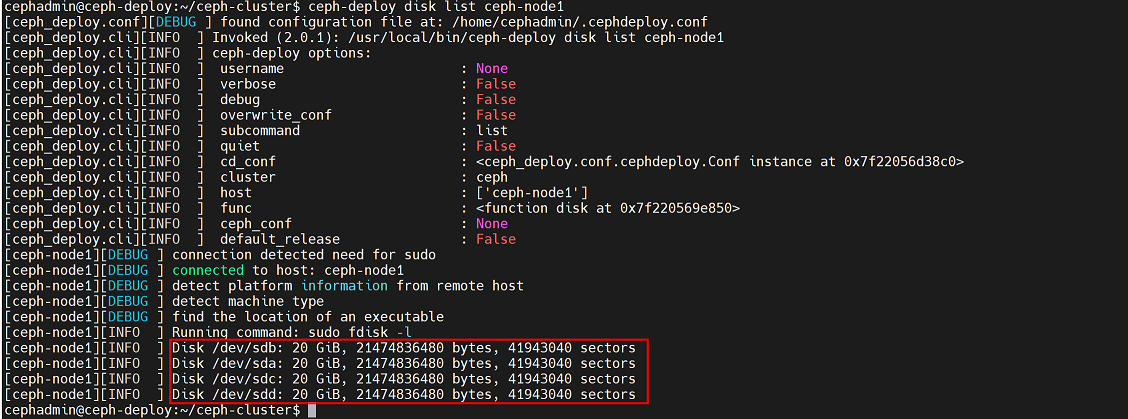
使用 ceph-deploy disk zap 擦除各 ceph node 的 ceph 数据磁盘:
ceph-node1 ceph-node2 ceph-node3 ceph-node4的存储节点磁盘擦除过程如下:
node1节点:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node1 /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node1 /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node1 /dev/sddnode2节点:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node2 /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node2 /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node2 /dev/sddnode3节点:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node3 /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node3 /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node3 /dev/sddnode4节点:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node4 /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node4 /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node4 /dev/sdd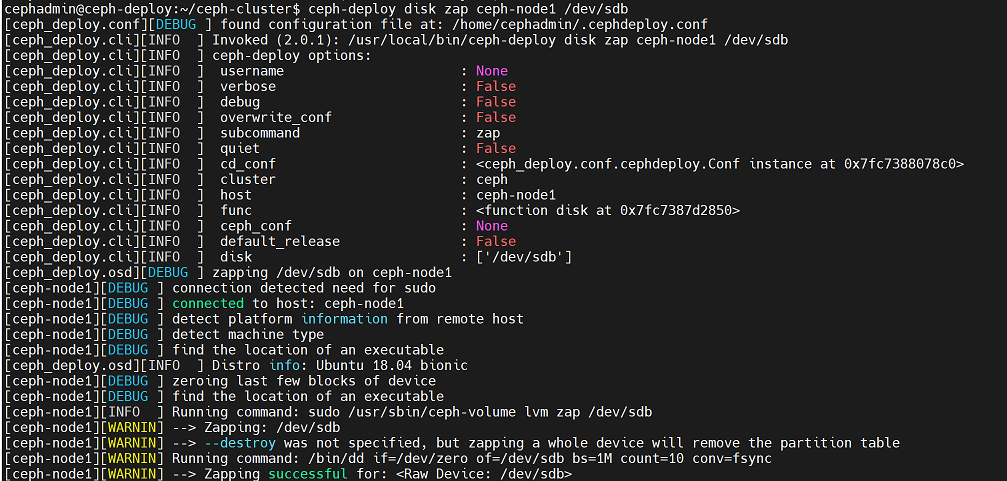
3.4.9.2 添加OSD
1、数据分类保存方式
由于数据类型不同(包括业务数据、集群元数据、日志文件等),对数据的实时读写要求也不通,因此数据需要分类保存。
数据分类保存方式:
Data:即 ceph 保存的对象数据
Block: rocks DB 数据即元数据
block-wal:数据库的 wal 日志
根据磁盘数量不同,可以将不同的数据指向不同的磁盘:
单块磁盘:机械硬盘或SSD,只能指向单个磁盘
Data:即 ceph 保存的对象数据
Block: rocks DB 数据即元数据
block-wal:数据库的 wal 日志
两块磁盘: 可以根据数据类型,将不同的数据指向不同的磁盘,提高整体性能
SSD:
Block: rocks DB 数据即元数据
block-wal:数据库的 wal 日志
机械硬盘:
Data:即 ceph 保存的对象数据
三块磁盘:可以根据数据类型,将不同的数据指向不同的磁盘,提高整体性能
NVME:
Block: rocks DB 数据即元数据
SSD:
block-wal:数据库的 wal 日志
机械硬盘:
Data:即 ceph 保存的对象数据
注意:如果有多个磁盘,也可以将所有数据类型都只想其中一种,比较方便。另外,如果要将不同的数据指向不同的磁盘,则要求所有的服务器磁盘配置都一样。osd添加命令选项:
For bluestore, optional devices can be used::
ceph-deploy osd create {node} --data /path/to/data --block-db /path/to/db-device
ceph-deploy osd create {node} --data /path/to/data --block-wal /path/to/wal-device
ceph-deploy osd create {node} --data /path/to/data --block-db /path/to/db-device --block-wal /path/to/wal-device
For filestore, the journal must be specified, as well as the objectstore::
ceph-deploy osd create {node} --filestore --data /path/to/data --journal /path/to/journal #使用 filestor 的数据和文件系统的日志的路径,journal是systemd的一个组件,用于补货系统日志信息、内核日志信息、磁盘的日志信息等。2、添加OSD
注意:如果添加osd的命令中只有--data选项,没有--block-db 和--block-wal,则说明将block-db数据、block-wal数据和--data的数据(ceph保存的对象数据)存放在一块
- 执行命令添加osd:
添加node1节点的磁盘
su – cephadmin
cd ceph-cluster
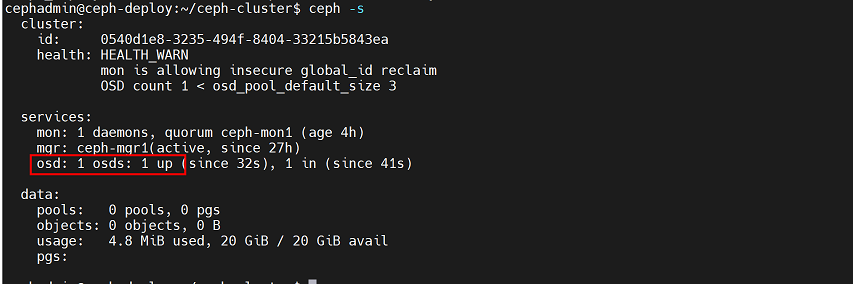
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdb可以看到被分配的osd ID为0,其他磁盘分配的osd ID会依次递增

查看osd集群信息,可看到1个osd已经加入
cephadmin@ceph-deploy:~/ceph-cluster$ ceph -s
继续添加其他磁盘:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdd添加node2节点的磁盘
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdd添加node3节点的磁盘
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdd添加node4节点的磁盘
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node4 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node4 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node4 --data /dev/sdd注意要将node节点磁盘对应的osd ID对应表进行统计,方便后期运维查询
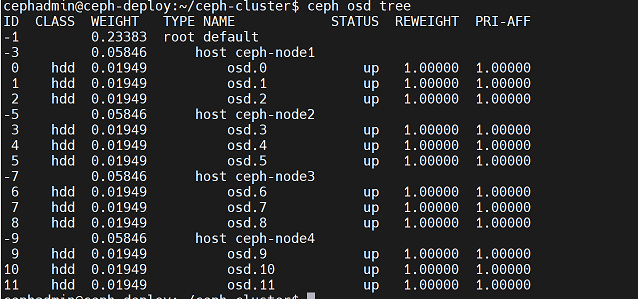
各node节点磁盘对应osd ID如下表:
| node1 | node2 | node3 | node4 | |
|---|---|---|---|---|
| /dev/sdb | 0 | 3 | 6 | 9 |
| /dev/sdc | 1 | 4 | 7 | 10 |
| /dev/sdd | 2 | 5 | 8 | 11 |
3、验证:
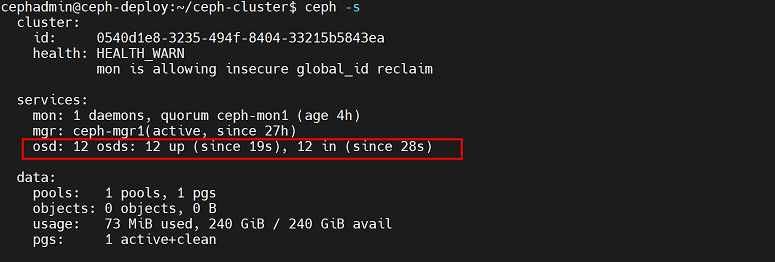
查看ceph集群信息:
可以看到已经添加了12个osd
使用以下命令可以查看各个node节点上的osd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd tree
在node节点查看osd进程,每个node节点均存在3个osd进程,每个进程对应一个osd

3.4.9.3 设置开机自启动
在node1节点172.31.7.126上执行命令:
root@ceph-node1:~# systemctl enable ceph-osd@0 ceph-osd@1 ceph-osd@2
在node2节点172.31.7.127上执行命令:
root@ceph-node2:~# systemctl enable ceph-osd@3 ceph-osd@4 ceph-osd@5
在node3节点172.31.7.128上执行命令:
root@ceph-node3:~# systemctl enable ceph-osd@6 ceph-osd@7 ceph-osd@8
在node4节点172.31.7.129上执行命令:
root@ceph-node4:~# systemctl enable ceph-osd@9 ceph-osd@10 ceph-osd@11
另外,查看ceph集群信息,会提示mon节点会允许非安全访问,health状态为WARN状态,为了解决该问题,需要修改参数
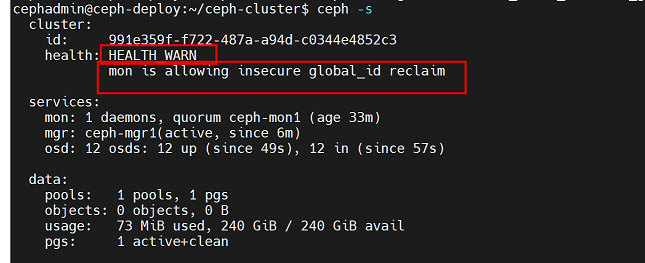
执行命令:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph config set mon auth_allow_insecure_global_id_reclaim false
再次查看集群信息,该提示已经消除,health状态已变为ok状态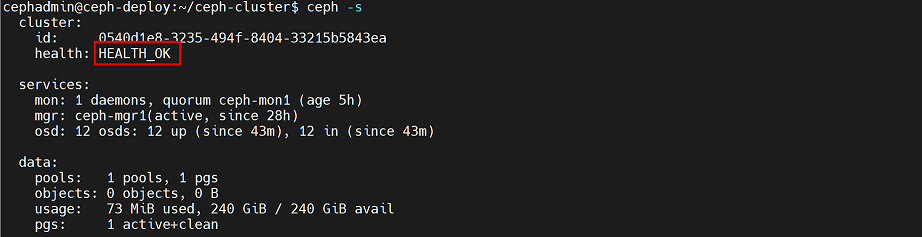
3.4.10 从 RADOS 移除 OSD
Ceph 集群中的一个 OSD 是一个 node 节点的服务进程且对应于一个物理磁盘设备,是一个专用的守护进程。在某 OSD 设备出现故障,或管理员出于管理之需确实要移除特定的 OSD设备时,需要先停止相关的守护进程,而后再进行移除操作。
对于 Luminous 及其之后的版本来说,停止和移除命令的格式分别如下所示:
- 停用设备:ceph osd out {osd-num} #osd-num是指osd ID,可通过ceph osd tree命令获取,该命令可在osd-deploy节点上执行
- 停止进程:sudo systemctl stop ceph-osd@{osd-num} #该命令需要在osd所在的node节点上执行
- 移除设备:ceph osd purge {id} --yes-i-really-mean-it #该命令可在osd-deploy节点上执行
若类似如下的 OSD 的配置信息存在于 ceph.conf 配置文件中,管理员在删除 OSD 之后手动将其删除。
不过,对于 Luminous 之前的版本来说,管理员需要依次手动执行如下步骤删除 OSD 设备:
- 于 CRUSH 运行图中移除设备:ceph osd crush remove {name}
- 移除 OSD 的认证 key:ceph auth del osd.{osd-num}
- 最后移除 OSD 设备:ceph osd rm {osd-num}
3.4.11 测试数据上传和下载
存取数据时,客户端必须首先连接至 RADOS 集群上某存储池,然后根据对象名称由相关的CRUSH 规则完成数据对象寻址。
注意:pg数量越多,则每个pg存储的数据越少,存储速度越快。
命令格式:
ceph osd pool create <pool_name> <pg_num> <pgp_num>

为了测试集群的数据存取功能,这里首先创建一个用于测试的存储池 mypool,并设定其 PG 数量为 32 个。
1、在ceph-deploy节点执行命令创建pool:
su - cephadmin
ceph osd pool create mypool 32 32 #这里的两个32是指32PG和32PGP
2、查看创建的pg和pgp组合:
ceph pg ls-by-pool mypool

由于展示内容过多,对结果进行过滤:
ceph pg ls-by-pool mypool |awk '{print $1" "$2" "$15}'注意:
下图红框中PG列为创建的PG,由于创建时指定了32个PG,所以该值共有32个。而PG列的第一个值为2.0,其中2是指存储池ID,0是指pgID,下面的值以此类推。
而ACTING列为PGP组合,创建时指定了32个PGP,因此有32种逻辑组合关系,每个逻辑组合关系里面有3个磁盘。该列的第一个值为[3,6,0]P3,其中3,6,0指的是三个磁盘的osdID,表示三副本,p3中的p是指primary,3是指osdID为3的磁盘,p3是指三个磁盘中该磁盘做为主磁盘,下面的值以此类推。这种组合正是通过CRUSH算法计算出来的。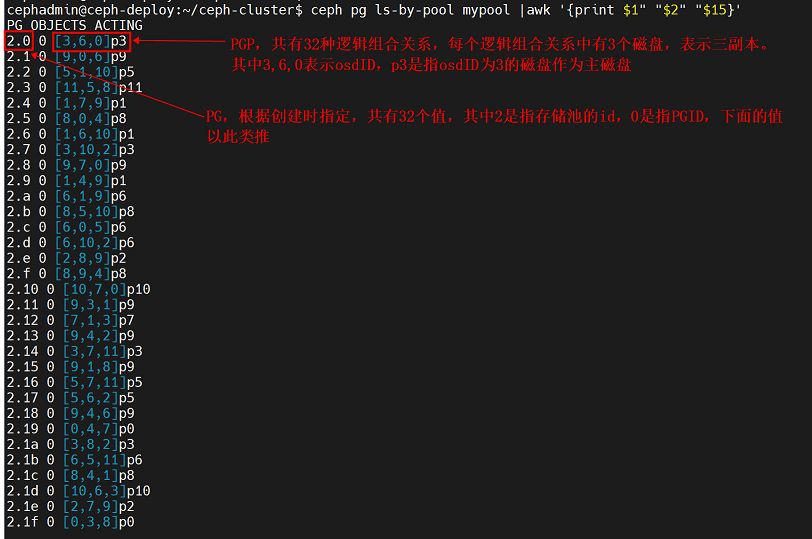
查看pool:
ceph osd pool ls

3、文件上传和下载测试
当前的 ceph 环境还没还没有部署使用块存储和文件系统使用 ceph,也没有使用对象存储的客户端,但是 ceph 的 rados 命令可以实现访问 ceph 对象存储的功能。
注意:真正的环境中很少通过使用ceph命令的方式进行数据的上传和下载,这里仅用来进行文件上传和下载的测试。
(1)文件上传:
sudo rados put msg1 /var/log/syslog --pool=mypool #把本地的/var/log/syslog命名为msg1上传到ceph存储的mypool存储池(2)列出文件:(当文件大于4M,将会被拆分为两个文件)
rados ls --pool=mypool
查看文件信息:
ceph osd map mypool msg1
显示结果表示:
文件放在了存储池 id 为 2 的 c833d430 的 PG 上,10 为当前 PG 的 id, 2.10 表示数据是在 id 为 2 的存储池当中 id 为 10 的 PG 中存储
在线的 OSD 编号 10,7,0,主 OSD 为 10,活动的 OSD 10,7,0,三个 OSD 表示数据放一共 3 个副本,PG 中的 OSD 是 ceph 的 crush算法计算出三份数据保存在哪些 OSD。
(3)下载文件:
sudo rados get msg1 --pool=mypool /opt/my.txt #将msg1文件下载到本地/tmp目录下并重命名为my.txt查看文件:

(4)修改文件
当使用相同的文件名称上传不同的文件时,后上传的文件会将之前的文件内容覆盖,因此可以通过这种方式对文件进行修改
上传文件:
sudo rados put msg1 /etc/passwd --pool=mypool #将本地/etc/passwd文件重命名为msg1并上传到mypool存储池,由于和此次也使用了msg1作为文件名,会将之前上传的/var/log/syslog文件覆盖,以达到修改文件内容的目的下载文件并查看文件内容:
sudo rados get msg1 --pool=mypool /tmp/2.txt
tail /tmp/2.txt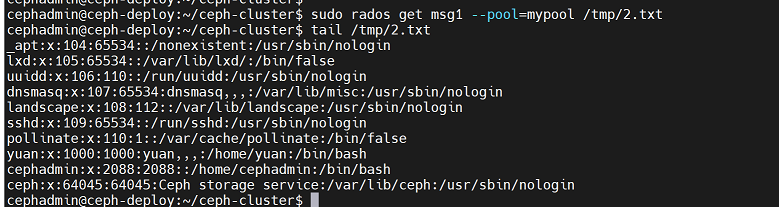
(5)删除文件
sudo rados rm msg1 --pool=mypool #删除msg1文件
rados ls --pool=mypool #查看mypool存储池的文件3.5 扩展ceph集群实现高可用
主要是扩展 ceph 集群的 mon 节点以及 mgr 节点,以实现集群高可用。
3.5.1 扩展 ceph-mon 节点
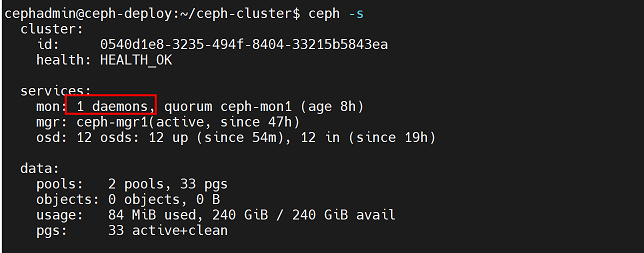
Ceph-mon 是原生具备自选举以实现高可用机制的 ceph 服务,节点数量通常是奇数。
查看当前集群情况,只有一个mon
1、使用命令添加mon2和mon3节点
在ceph-deploy节点172.31.7.120执行命令:
su – cephadmin
cd ceph-cluster
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mon add ceph-mon2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mon add ceph-mon32、查看ceph-mon状态
执行命令:
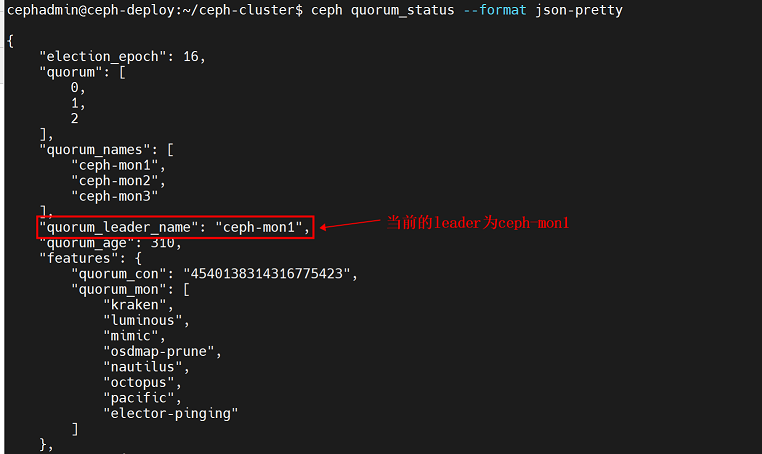
cephadmin@ceph-deploy:~/ceph-cluster$ ceph quorum_status #这种格式不方便查看
cephadmin@ceph-deploy:~/ceph-cluster$ ceph quorum_status --format json-pretty #以json格式展示可以看到ceph-mon1为leader
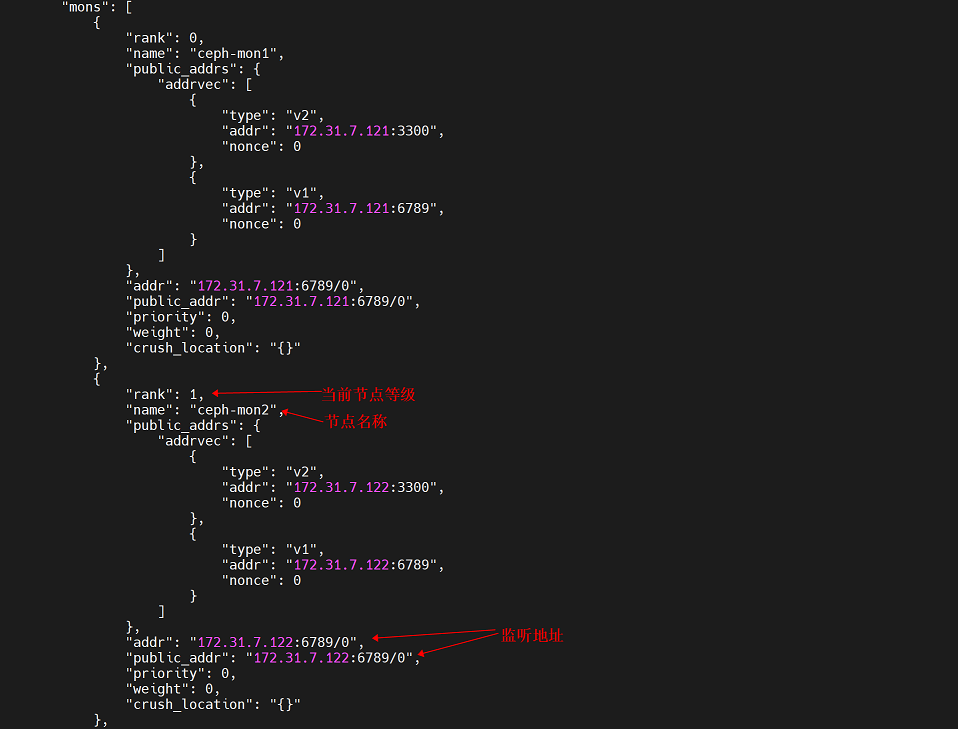
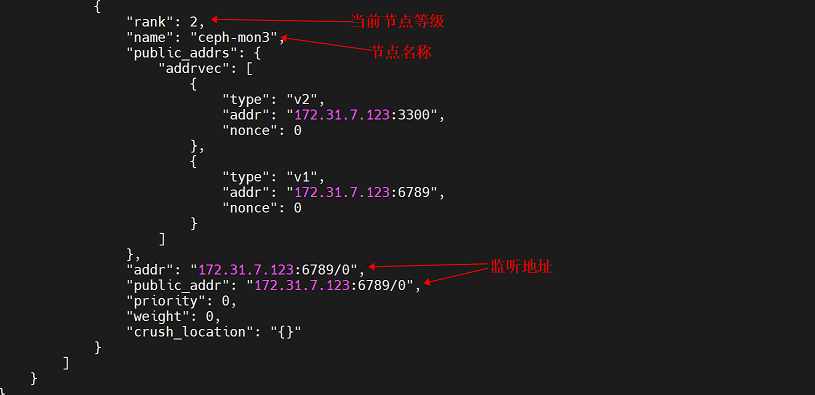
集群中各mon节点信息
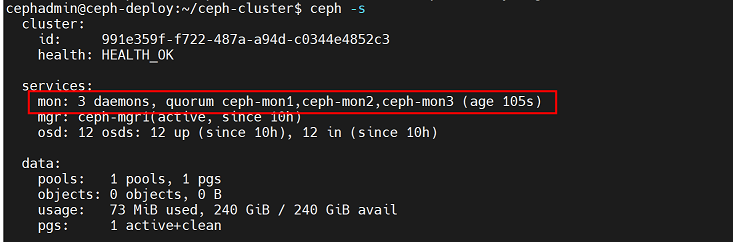
查看集群信息:
3.5.2 扩展ceph-mgr节点
1、在需要添加的mgr节点安装ceph-mgr(172.31.7.125)安装包
root@ceph-mgr2:~# apt install ceph-mgr2、在deploy节点172.31.7.120上执行命令,添加mgr2节点
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mgr create ceph-mgr2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-mgr2 #同步配置文件到ceph-mgr2节点3、验证:
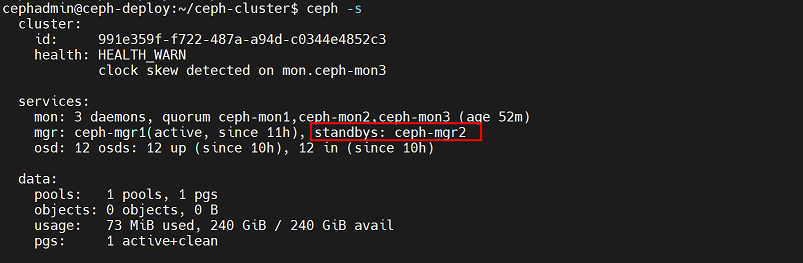
查看集群信息,mgr2添加成功

文章评论