
本章概要
- 关系型数据库基础
- 安装MySQL
- 管理数据库和表
- 函数和存储过程
- 用户和权限管理
- MySQL架构
- 存储引擎
- 服务器选项,系统和状态变量
- 优化查询和索引管理
- 锁和事务管理
- 日志管理
- 备份还原
- MySQL读写分离
- MySQL集群
1、关系型数据库基础
数据库的发展史
- 萌芽阶段:文件系统
使用磁盘文件来存储数据 - 初级阶段:第一代数据库
出现了网状模型、层次模型的数据库 - 中级阶段:第二代数据库
关系型数据库和结构化查询语言 - 高级阶段:新一代数据库
“关系-对象”型数据库
文件管理系统的缺点
- 编写应用程序不方便
- 数据冗余不可避免
- 应用程序依赖性
- 不支持对文件的并发访问
- 数据间联系弱
- 难以按用户视图表示数据
- 无安全控制功能
数据库管理系统的优点
- 相互关联的数据的集合
- 较少的数据冗余
- 程序与数据相互独立
- 保证数据的安全、可靠
- 最大限度地保证数据的正确性
- 数据可以并发使用并能同时保证一致性
数据库管理系统及其基本功能和机构
- 数据库管理系统
数据库是数据的汇集,它以一定的组织形式存于存储介质上
DBMS是管理数据库的系统软件,它实现数据库系统的各种功能。是数据库系统的核心
DBA:负责数据库的规划、设计、协调、维护和管理等工作
应用程序指以数据库为基础的应用程序 - 数据库管理系统的基本功能
数据定义
数据处理
数据安全
数据备份 - 数据库系统机构
单机架构
大型主机/终端架构
主从式架构(C/S)
分布式架构
关系型数据库
- 关系:关系就是二维表。并满足如下性质:
表中的行、列次序并不重要 - 行row:表中的每一行,又称为一条记录
- 列column:表中的每一列,称为属性,字段
- 主键(Primary key):用于惟一确定一个记录的字段
- 域domain:属性的取值范围,如,性别只能是‘男’和‘女’两个值
关系数据库
- RDBMS:关系数据库
MySQL: MySQL, MariaDB, PerconaServer
PostgreSQL: 简称为pgsql,EnterpriseDB
Oracle
MSSQL
DB2 - 数据库排名:
https://db-engines.com/en/ranking
实体-联系模型E-R
- 实体Entity
客观存在并可以相互区分的客观事物或抽象事件称为实体。
在E-R图中用矩形框表示实体,把实体名写在框内 - 属性
实体所具有的特征或性质 - 联系
联系是数据之间的关联集合,是客观存在的应用语义链
实体内部的联系:指组成实体的各属性之间的联系。如职工实体中,职工号和部门经理号之间有一种关联关系
实体之间的联系:指不同实体之间联系。例学生选课实体和学生基本信息实体之间
实体之间的联系用菱形框表示
联系类型
- 联系的类型
一对一联系(1:1)
如:学员a的基本信息对应其就业信息
一对多联系(1:n)
示例:
学员a的信息表对应考试成绩表,成绩表包括月考成绩,期中考试成绩,期末考试成绩,两个表之间通过学员id号关联,学员的一个id号对应多个考试成绩
学员成绩表被学员信息表中的id号所约束,因此学员成绩表依赖于学员信息表 外键 foreign key 简称FK
主键 简称PK
一对多用主外键来实现
主键表:被外键表依赖的表,即学员信息表
外键表:依赖于其他的表(主键表),即学员成绩表
外键字段:外键表依赖于主键表的字段,即id号
主键表中被外键表依赖的字段必须是主键
多对多联系(m:n)
示例:
课程与学员之间的关系就是多对多
学员表 student
课程表 class
使用第三张表student_class实现课程与学员之间的关系
student表
id name sex
1 a f
2 b m
3 c f
class 课程表
id classname
1 linux
2 python
3 java
student_class表
id student_id class_id
1 1 1
2 1 2
3 2 2
student_class表中的student_id、class_id属于外键,student表中的学员id号和class表中的课程id号属于相对应的主键
这样就实现了两张表的多对多的关系
对对多对的表操作进行查询,因为涉及到多个表,所以性能会差- 数据的操作:
数据提取:在数据集合中提取感兴趣的内容。SELECT
数据更新:变更数据库中的数据。INSERT、DELETE、UPDATE - 数据的约束条件:是一组完整性规则的集合
实体(行)完整性Entity integrity
域(列)完整性Domain Integrity
参考完整性Referential Integrity
简易数据规划流程
- 第一阶段:收集数据,得到字段
收集必要且完整的数据项
转换成数据表的字段 - 第二阶段:把字段分类,归入表,建立表的关联
关联:表和表间的关系
分割数据表并建立关联的优点
节省空间
减少输入错误
方便数据修改 - 第三阶段:
规范化数据库
数据库的正规化分析
- RDMBS设计范式基础概念
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同范式,各种范式呈递次规范,越高的范式数据库冗余越小 - 目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴德斯科范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)即可
范式
- 1NF:无重复的列,每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。除去同类型的字段,就是无重复的列
说明:第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库
示例:
1NF:
作者 书名1 书名2
a linux python
b python
有属性相同的列:书名
作者 书名1
a linux,python
b python
同一行有多个值
以上两种均不符合第一范式
解决方法:
a linux
a oython
b python- 2NF:属性完全依赖于主键,第二范式必须先满足第一范式,要求表中的每个行必须可以被唯一地区分。通常为表加上一个列,以存储各个实例的唯一标识PK,非PK的字段需要与整个PK有直接相关性
示例:
员工信息表
name city sex phone citynumber(城市区号)
a bj 010
b sh 021
复合主键:把多个字段(name,city)纳入主键,两个字段其中一个字段可以重复,但是两个一起不能重复
这时,区号citynumber只依赖于city,而不依赖于name,该属性没有完全依赖于主键,这就违反了第二范式
解决方法:
name city
a 1
b 2
b 2
cityid city citynumber
1 bj 010
2 sh 021- 3NF:属性不依赖于其它非主属性,满足第三范式必须先满足第二范式。第三范式要求一个数据库表中不包含已在其它表中已包含的非主关键字信息,非PK的字段间不能有从属关系
示例:
id name city sex phone citynumber(城市区号)
1 a bj 010
2 a sh 021
3 b sh 021
这里使用id号作为主键
这时,citynumber城市区号依赖于city,而city不属于主键;其他属性依赖于非主属性,违反了第三范式
解决方法:构建第三张表
id name city
1 a 1
2 b 2
3 b 2
cityid city citynumber
1 bj 010
2 sh 021
缺点:多表操作,数据库性能会变差SQL概念
- SQL: Structure Query Language
结构化查询语言
SQL解释器:
数据存储协议:应用层协议,C/S - S:server, 监听于套接字,接收并处理客户端的应用请求
- C:Client
客户端程序接口
CLI
GUI
应用编程接口
ODBC:Open Database Connectivity
JDBC:Java Data Base Connectivity
约束
- 约束:constraint,表中的数据要遵守的限制
主键:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;必须提供数据,即NOT NULL,一个表只能有一个
惟一键:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;允许为NULL,一个表可以存在多个
外键:一个表中的某字段可填入的数据取决于另一个表的主键或唯一键已有的数据
检查:字段值在一定范围内
基本概念
- 索引:将表中的一个或多个字段中的数据复制一份另存,并且按特定次序排序存储
- 关系运算:
选择:挑选出符合条件的行
投影:挑选出需要的字段
连接:表间字段的关联
数据模型
- 数据抽象:
物理层:数据存储格式,即RDBMS在磁盘上如何组织文件
逻辑层:DBA角度,描述存储什么数据,以及数据间存在什么样的关系
视图层:用户角度,描述DB中的部分数据 - 关系模型的分类:
关系模型
基于对象的关系模型
半结构化的关系模型:XML数据
2、MySQL数据库
2.1 MySQL介绍
MySQL历史
- 1979年:TcX公司Monty Widenius,Unireg
- 1996年:发布MySQL1.0,Solaris版本,Linux版本
- 1999年:MySQL AB公司,瑞典
- 2003年:MySQL 5.0版本,提供视图、存储过程等功能
- 2008年:Sun 收购
- 2009年:Oracle收购sun
- 2009年:Monty成立MariaDB
MySQL和MariaDB
- 官方网址:
https://www.mysql.com/
http://mariadb.org/ - 官方文档
https://dev.mysql.com/doc/
https://mariadb.com/kb/en/ - 版本演变:
MySQL:5.1 --> 5.5 --> 5.6 --> 5.7 -->8.0
MariaDB:5.5 -->10.0--> 10.1 --> 10.2 --> 10.3
MYSQL的特性
- 插件式存储引擎:也称为“表类型”,存储管理器有多种实现版本,功能和特性可能均略有差别;用户可根据需要灵活选择,Mysql5.5.5开始innoDB引擎是MYSQL默认引擎
MyISAM==> Aria
InnoDB==> XtraDB - 单进程,多线程
- 诸多扩展和新特性
- 提供了较多测试组件
- 开源
2.2 安装MySQL
- Mariadb安装方式:
1、源代码:编译安装
2、二进制格式的程序包:展开至特定路径,并经过简单配置后即可使用
3、程序包管理器管理的程序包
CentOS安装光盘
项目官方:https://downloads.mariadb.org/mariadb/repositories/
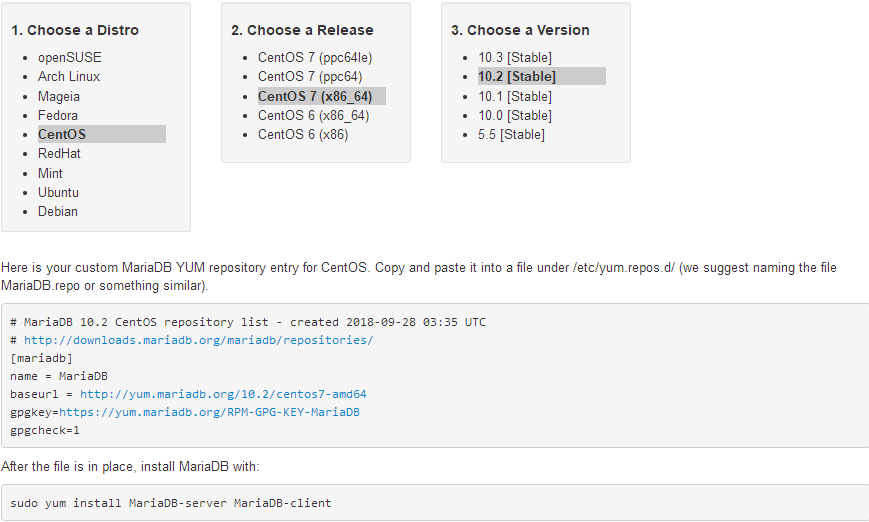
注意:
如果不想使用光盘自带的数据库,而是使用相对较新的数据库,可以使用官方提供的yum源进行安装
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/10.2/centos7-amd64
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
注意:在配置yum源时,要配置本地yum源,以解决依赖关系;安装新版本数据库名称为MariaDB-serverRPM包安装MySQL
- RPM包安装
CentOS7:安装光盘直接提供
mariadb-server 服务器包
mariadb客户端工具包
CentOS6 - 使用yum安装,存在以下问题:
(1)存在匿名用户以及空口令,即任何用户都可以以空口令登录
(2)所有登录用户只能在本地登录,不能远程登录
(3)默认存在test测试数据库,该数据库供新手练习使用,可以删除 - 使用以下脚本,提高数据库安全性
mysql_secure_installation
设置数据库管理员root口令
禁止root远程登录
删除anonymous用户帐号
删除test数据库
脚本运行过程如下:
[root@centos7-1 ~]#mysql_secure_installation
NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB
SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY!
In order to log into MariaDB to secure it, we'll need the current
password for the root user. If you've just installed MariaDB, and
you haven't set the root password yet, the password will be blank,
so you should just press enter here.
Enter current password for root (enter for none): 写入当前mysql数据库root口令,默认没有口令,直接敲enter键
OK, successfully used password, moving on...
Setting the root password ensures that nobody can log into the MariaDB
root user without the proper authorisation.
Set root password? [Y/n] y 是否设置root口令
New password: 写入新口令
Re-enter new password: 再次确认口令
Password updated successfully!
Reloading privilege tables..
... Success!
By default, a MariaDB installation has an anonymous user, allowing anyone
to log into MariaDB without having to have a user account created for
them. This is intended only for testing, and to make the installation
go a bit smoother. You should remove them before moving into a
production environment.
Remove anonymous users? [Y/n] y 是否移除匿名用户
... Success!
Normally, root should only be allowed to connect from 'localhost'. This
ensures that someone cannot guess at the root password from the network.
Disallow root login remotely? [Y/n] y 是否禁止root远程登录
... Success!
By default, MariaDB comes with a database named 'test' that anyone can
access. This is also intended only for testing, and should be removed
before moving into a production environment.
Remove test database and access to it? [Y/n] y 是否移除test测试数据库
- Dropping test database...
... Success!
- Removing privileges on test database...
... Success!
Reloading the privilege tables will ensure that all changes made so far
will take effect immediately.
Reload privilege tables now? [Y/n] y 是否立即下载权限表
... Success!
Cleaning up...
All done! If you've completed all of the above steps, your MariaDB
installation should now be secure.
Thanks for using MariaDB!注意:如果设置有误,可以再次运行脚本进行设置
一旦该脚本运行过以后,想再次以匿名用户或者空口令登录,将不会被允许
MariaDB程序
- 客户端程序:
mysql: 交互式的CLI工具
mysqldump:备份工具,基于mysql协议向mysqld发起查询请求,并将查得的所有数据转换成insert等写操作语句保存文本文件中
mysqladmin:基于mysql协议管理mysqld
mysqlimport:数据导入工具 - MyISAM存储引擎的管理工具:
myisamchk:检查MyISAM库
myisampack:打包MyISAM表,只读 - 服务器端程序
mysqld_safe
mysqld
mysqld_multi:多实例,示例:mysqld_multi--example
mysql默认不支持多实例,要想实现多实例,准备多个mysql安装程序,把配置文件加以修改,使得各自的端口号均不一样,每个实例之间相互独立,互不影响
用户账号
- mysql用户账号由两部分组成:
'USERNAME'@'HOST' - 说明:
HOST限制此用户可通过哪些远程主机连接mysql服务器
支持使用通配符:
% 匹配任意长度的任意字符
172.16.0.0/255.255.0.0 或172.16.%.%
_ 匹配任意单个字符
MySQL客户端
- mysql使用模式:
- 交互式模式:
可运行命令有两类:
客户端命令:
\h, help
\u,use
\s,status
\!,system
服务器端命令:
SQL, 需要语句结束符; - 脚本模式:
mysql –u USERNAME -p PASSWORD < /path/somefile.sql
mysql> source /path/from/somefile.sql
示例:
[root@centos7-1 ~]#cat test.sql
show databases;
[root@centos7-1 ~]#mysql -uroot -pcentos123456 < test.sql
Database
information_schema
mysql
performance_schema
注意:该命令显示结果中的列表与在mysql数据库中执行命令有细微差别,即不带边框 - mysql客户端可用选项:
-A, --no-auto-rehash 禁止补全
-u, --user=用户名,默认为root
-h, --host=服务器主机,默认为localhost
-p, --passowrd=用户密码,建议使用-p,默认为空密码
-P, --port=服务器端口
-S, --socket=指定连接socket文件路径
-D, --database= 指定默认数据库
-C, --compress启用压缩
-e “SQL“执行SQL命令
-V, --version显示版本
-v --verbose显示详细信息
--print-defaults 获取程序默认使用的配置
socket地址
- 服务器监听的两种socket地址:
ipsocket: 监听在tcp的3306端口,支持远程通信
unixsock: 监听在sock文件上,仅支持本机通信
如:/var/lib/mysql/mysql.sock
说明:host为localhost,127.0.0.1时自动使用unixsock
注意:
如果客户端服务器在同一台主机,即使服务端口号没有打开也能连接
[root@centos7-1 ~]#iptables -A INPUT -p tcp --dport 3306 -j REJECT
[root@centos7-1 ~]#mysql -uroot -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 31
Server version: 5.5.56-MariaDB MariaDB Server
Copyright (c) 2000, 2017, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]>
注意:此时mysql -uroot -p 相当于mysql -uroot -p -hlocalhost,即在本机登录。
当客户端和服务器端在同一台主机,客户端登录服务器端并不是通过网络,也没有通过端口号,而是通过/usr/lib/mysql/mysql.socket文件进行连接,socket相当于文件传输中转站,只在本地生效,如果客户端跨网络访问服务端时,则socket文件不生效
如果删除该文件,则客户端无法在本机连接服务端
mysql.socket文件,在服务启动时创建,服务关闭时将不存在;
因此只需重启服务,该文件即可重新生成执行命令
- 运行mysql命令:默认空密码登录
mysql>use mysql
mysql>select user();查看当前用户
mysql>SELECT User,Host,PasswordFROM user; - 登录系统:mysql –uroot –p
- 客户端命令:本地执行
mysql> help
每个命令都完整形式和简写格式
mysql> status 或\s - 服务端命令:通过mysql协议发往服务器执行并取回结果
每个命令都必须命令结束符号;默认为分号
SELECT VERSION();
知识扩展:更改数据库终端提示符
查看mysqlman帮助: man mysql
搜索prompt,查看提示符修改表格
格式:
在linux中执行:
shell> mysql --prompt="(\u@\h) [\d]> " 这种更改只是临时的,下次登录如果不写就会恢复默认
想要永久保存,需要把更改写入配置文件中
vim /etc/profile.d/env.sh 把变量写入配置文件中
export MYSQL_PS1="(\u@\h) [\d]> " 声明变量
source /etc/profile.d/env.sh 使文件立即生效
或者写入数据库客户端配置文件语句块中
vim /etc/my.cnf.d/mysql-clients.cnf
[mysql]
prompt="\\r:\\m:\\s> "
注意:这两个文件生效的优先级:/etc/my.cnf.d/mysql-clients.cnf文件优先级大于/etc/profile.d/env.sh文件,即数据库客户端配置文件优先生效
另外,在工作中要把生产环境与测试环境的提示符区分开,防止混淆服务器端配置
- 服务器端(mysqld):工作特性有多种配置方式
- 1、命令行选项:
- 2、配置文件:类ini格式
集中式的配置,能够为mysql的各应用程序提供配置信息
[mysqld] 服务器端配置语句块
[mysqld_safe] 服务端安全性配置语句块
[mysqld_multi] 服务端多实例配置语句块
[mysql] 客户端配置语句块
[mysqldump] 客户端数据库备份语句块
[server] 服务器配置语句块
[client] 客户端配置语句块
格式:parameter = value
说明:_和-相同
1,ON,TRUE意义相同,0,OFF,FALSE意义相同
配置文件
- 配置文件:
文件优先级从上到下,优先级逐渐变高
文件如下:
/etc/my.cnf Global选项
/etc/mysql/my.cnf Global选项
SYSCONFDIR/my.cnf Global选项,即用户指定目录下配置文件
$MYSQL_HOME/my.cnf Server-specific 选项
--defaults-extra-file=path
~/.my.cnf User-specific 选项,即用户家目录下配置文件一般情况下,写入/etc/my.cnf配置文件中
MariaDB配置
- 侦听3306/tcp端口可以在绑定有一个或全部接口IP上
- vim /etc/my.cnf
[mysqld]
skip-networking=1
关闭网络连接,只侦听本地客户端,所有和服务器的交互都通过一个socket实现,socket的配置存放在/var/lib/mysql/mysql.sock)可在/etc/my.cnf修改
通过二进制格式安装过程
- 二进制格式安装过程(以mariadb-10.2.18版本为例)
(1)准备数据目录
创建逻辑卷,供mysql存放数据使用,因为mysql存放的数据会逐渐增加,使用逻辑卷便于扩展。对硬盘进行分区,创建10G大小的分区(10G为做实验时划分的大小,在实际生产环境中,根据需求进行划分),要注意更改分区标签为8e(lvm类型),分区完毕后同步分区
示例:
创建分区为/dev/sda6
创建逻辑卷:
pvcreate /dev/sda6
vgcreate vg_data /dev/sda6
lvcreate -n lv_mysql -l 100%FREE vg_data
mkfs.xfs /dev/vg_data/lv_mysql
blkid /dev/vg_data/lv_mysql
/dev/vg_data/lv_mysql: UUID="ba3abbaf-b064-40b8-9127-f4f9453133f2" TYPE="xfs"
vim /etc/fstab
UUID=ba3abbaf-b064-40b8-9127-f4f9453133f2 /mysql xfs defaults 0 0 把逻辑卷挂在到/mysql目录下,该目录用于存放数据库数据mount -a
(2) 创建mysql用户和mysql组
mkdir /mysql/data 手动创建用户家目录
chown mysql.mysql /mysql/data 更改家目录所有者和所属组
useradd -r -s /sbin/nologin -d /mysql/data mysql 注意:在创建用户时,不能指定用户家目录(即-m选项,创建用户家目录),否则数据库安装完毕后,会自动创建以家目录中文件名为命名的数据库
(3) 准备二进制程序
tar xvf mariadb-10.2.18-linux-x86_64.tar.gz -C /usr/local/
注意:这里解压缩的文件路径必须指定为/usr/local目录,因为该文件在编译时就以该目录作为数据库应用程序存放位置。
另外,由于解压后的文件带有版本号,而该文件默认不能有版本号信息,因此,创建软链接指向该文件,而且这样的做法利用灰度发布的思路,有利于版本的切换(只需更改软链接即可)
cd /usr/local/
ln -s mariadb-10.2.18-linux-x86_64/ mysql/此时,/usr/local/mariadb-10.2.18-linux-x86_64目录下文件所有者和所属组有问题,因此需要更改该目录下所有文件的所有者和所属组
chown -R root:mysql /usr/local/mysql/
(4) 准备配置文件
配置文件可根据系统提供的模板进行修改
配置文件模板所在路径:/usr/local/mysql/support-files/
该目录下有四个模板文件,每个数据库配置文件支持的内存大小不同
my-small.cnf 支持小于等于64M内存
my-medium.cnf 支持32M-64M内存
my-large.cnf 支持512M内存
my-huge.cnf 支持1G-2G内存
根据需求,选择不同的模板文件,在这里我们使用my-huge.cnf模板文件
另外,为了防止与系统自带的数据库配置文件冲突,把配置文件存放到/etc/mysql目录下并命名为my.cnf,因为该目录下配置文件优先级高于系统自带配置文件/etc/my.cnf,该目录需要手动创建
mkdir /etc/mysql/
cd /usr/local/mysql/support-files
cp my-huge.cnf /etc/mysql/my.cnf
更改配置文件:
vim /etc/mysql/my.cnf
[mysqld]
datadir=/mysql/data 指定数据存放路径
innodb_file_per_table=on
skip_name_resolve=on
innodb_file_per_table= on 数据库的每一个表都生成一个独立的文件,便于管理;默认情况下,所有的表存放在一个文件中,这样不利于管理。该文件在10.2以上版本的数据库默认开启此功能,可以不用添加
skip_name_resolve= on 禁止把ip反向解析为名字,因为反向解析会降低数据库的性能,因此建议关闭反向解析(5)创建数据库文件
cd /usr/local/mysql/
./scripts/mysql_install_db --datadir=/mysql/data --user=mysql (6)准备服务脚本,并启动服务
服务脚本可以参考系统中提供的模板文件:/usr/local/mysql/support-files/mysql.server
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
把服务脚本复制到系统服务目录下重命名为mysqld,系统启动即可启动该服务
chkconfig --add mysqld 把服务加入服务列表中
service mysqld start 启动服务,由于该服务是二进制编译安装,因此启动服务使用service命令
为了便于使用,把该命令所在路径加入PATH变量
echo PATH=/usr/local/mysqld/bin:$PATH > /etc/profile.d/mysqld.sh (7)安全初始化
/user/local/mysql/bin/mysql_secure_installation
至此,二进制安装mysql完成
源码编译安装mariadb
具体步骤如下:
1、安装编译依赖的软件包
yum -y install bison bison-develzlib-devel libcurl-devel libarchive-devel boost-develgccgcc-c++ cmakencurses-devel gnutls-devel libxml2-devel openssl-devel libevent-devel libaio-devel 2、做准备用户和数据目录
mkdir/data
useradd -r -s /sbin/nologin -d /data/mysql mysql
tar xvfmariadb-10.2.15.tar.gz 3、cmake编译安装:
cmake的重要特性之一是其独立于源码(out-of-source)的编译功能,即编译工作可以在另一个指定的目录中而非源码目录中进行,这可以保证源码目录不受任何一次编译的影响,因此在同一个源码树上可以进行多次不同的编译,如针对于不同平台编译
编译选项:https://dev.mysql.com/doc/refman/5.7/en/source-configuration-options.html
cd mariadb-10.2.15/
cmake . -DCMAKE_INSTALL_PREFIX=/app/mysql -DMYSQL_DATADIR=/data/mysql/ -DSYSCONFDIR=/etc -DMYSQL_USER=mysql -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_ARCHIVE_STORAGE_ENGINE=1 -DWITH_BLACKHOLE_STORAGE_ENGINE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DWITHOUT_MROONGA_STORAGE_ENGINE=1 -DWITH_DEBUG=0 -DWITH_READLINE=1 -DWITH_SSL=system -DWITH_ZLIB=system -DWITH_LIBWRAP=0 -DENABLED_LOCAL_INFILE=1 -DMYSQL_UNIX_ADDR=/data/mysql/mysql.sock -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci
提示:如果出错,执行rm-f CMakeCache.txt4、生成数据库文件
cd/app/mysql/
scripts/mysql_install_db --datadir=/data/mysqldb/ --user=mysql/5、准备配置文件
cp /app/mysql/support-files/my-huge.cnf/etc/my.cnf
6、准备启动脚本
cp /app/mysql/support-files/mysql.server/etc/init.d/mysqld
7、准备环境变量
echo 'PATH=/app/mysql/bin:$PATH' > /etc/profile.d/mysql.sh
. /etc/profile.d/mysql.sh8、启动服务
chkconfig--add mysqld;
service mysqld start 实验:实现数据库多实例
-
实现数据库多实例
主要在测试环境中使用,多实例可以使相同版本,也可是使用不同版本 -
实现多实例需要提前准备:
1、用户
2、数据库存放数据的目录
3、数据库配置文件
4、数据库的启动脚本
5、数据库中存放系统数据的数据库文件 -
如果基于同一版本mysql数据库实现多实例:
1、二进制安装程序可使用同一个
2、应用程序可以使用同一个
3、用户账号可以是同一个
4、存放数据库的目录是各自独立的
5、配置文件是独立的,每个数据库的端口可能也不一样
6、服务的启动脚本是独立的,里面监听的端口号也不一样
yum安装mariadb实现多实例:
mysql账号自动生成
[root@centos7 ~]# getent passwd mysql
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
二进制程序默认目录:/usr/libexec/mysqld
规划:
自定义端口号:3306 3307 3308
存放数据库的目录:
/data/mysql/{3306,3307,3308}
以3306为例:
/data/mysql/3306/{etc,log,data,pid,bin}
etc 存放配置文件
log 存放日志文件
data 存放数据库的数据
pid 存放数据库的进程
bin 存放数据库的二进制程序
(1)创建所需的各个目录
mkdir -pv /data/mysql/{3306,3307,3308}/{etc,data,socket,log,bin,pid}
[root@centos7 data]# tree mysql
mysql
├── 3306
│ ├── bin
│ ├── data
│ ├── etc
│ ├── log
│ ├── pid
│ └── socket
├── 3307
│ ├── bin
│ ├── data
│ ├── etc
│ ├── log
│ ├── pid
│ └── socket
└── 3308
├── bin
├── data
├── etc
├── log
├── pid
└── socket
更改mysql目录的所有者和所属组为mysql
chown -R mysql.mysql mysql
(2)准备数据库数据文件:
生成系统数据库文件,使用系统提供的脚本文件:/usr/bin/mysql_install_db
/usr/bin/mysql_install_db --datadir=/data/mysql/3306/data --user=mysql 生成3306端口号的数据库文件,指定存放数据的路径以及用户账号
/usr/bin/mysql_install_db --datadir=/data/mysql/3307/data --user=mysql 生成3307端口号的数据库文件,指定存放数据的路径以及用户账号
/usr/bin/mysql_install_db --datadir=/data/mysql/3308/data --user=mysql 生成3308端口号的数据库文件,指定存放数据的路径以及用户账号
(3)准备配置文件
参考系统生成的数据库配置文件,配置所需的数据库文件
3306端口号数据库配置文件
cp /etc/my.cnf /data/mysql/3306/etc/
vim /data/mysql/3306/etc/my.cnf
[mysqld]
port=3306 指定端口号
datadir=/data/mysql/3306/data 指定存放数据的文件路径
socket=/data/mysql/3306/socket/mysql.sock 指定存放socket文件路径
[mysqld_safe]
log-error=/data/mysql/3306/log/mariadb.log 指定存放日志文件路径
pid-file=/data/mysql/3306/pid/mariadb.pid 指定存放pid文件路径
# !includedir /etc/my.cnf.d 自定义数据量不存在子配置文件,注释掉该行
3307端口号数据库配置文件
cp /etc/my.cnf /data/mysql/3307/etc/
vim /data/mysql/3307/etc/my.cnf
[mysqld]
port=3307 指定端口号
datadir=/data/mysql/3307/data 指定存放数据的文件路径
socket=/data/mysql/3307/socket/mysql.sock 指定存放socket文件路径
[mysqld_safe]
log-error=/data/mysql/3307/log/mariadb.log 指定存放日志文件路径
pid-file=/data/mysql/3307/pid/mariadb.pid 指定存放pid文件路径
# !includedir /etc/my.cnf.d 自定义数据量不存在子配置文件,注释掉该行
3308端口号数据库配置文件
cp /etc/my.cnf /data/mysql/3308/etc/
vim /data/mysql/3308/etc/my.cnf
[mysqld]
port=3308 指定端口号
datadir=/data/mysql/3308/data 指定存放数据的文件路径
socket=/data/mysql/3308/socket/mysql.sock 指定存放socket文件路径
[mysqld_safe]
log-error=/data/mysql/3308/log/mariadb.log 指定存放日志文件路径
pid-file=/data/mysql/3308/pid/mariadb.pid 指定存放pid文件路径
# !includedir /etc/my.cnf.d 自定义数据量不存在子配置文件,注释掉该行
(4)准备mysql服务脚本
可以使用以下脚本实现服务脚本:
vim mysqld
#!/bin/bash
port=3306 自定义端口号,根据需求进行更改
mysql_user="root" 指定以roo身份启动mysql
mysql_pwd="" 指定mysql的root口令
cmd_path="/usr/bin" 指定mysql程序路径,该路径为yum安装默认路径,如果是二进制安装或者源码编译安装数据库,则根据需求进行更改
mysql_basedir="/data/mysql" mysql数据库的根目录,根据需求进行更改
mysql_sock="${mysql_basedir}/${port}/socket/mysql.sock" 调用定义变量,指定数据库socket文件路径
function_start_mysql() 定义函数,启动mysql
{
if [ ! -e "$mysql_sock" ];then
printf "Starting MySQL...\n"
${cmd_path}/mysqld_safe --defaults-file=${mysql_basedir}/${port}/etc/my.cnf &> /dev/null & 使用mysqld_safe命令调用配置文件启动mysql服务
else
printf "MySQL is running...\n"
exit
fi
}
function_stop_mysql() 定义函数,关闭mysql
{
if [ ! -e "$mysql_sock" ];then
printf "MySQL is stopped...\n"
exit
else
printf "Stoping MySQL...\n"
${cmd_path}/mysqladmin -u ${mysql_user} -p${mysql_pwd} -S ${mysql_sock} shutdown 使用mysqldadmin命令关闭mysql服务
fi
}
function_restart_mysql() 定义函数,重启mysql
{
printf "Restarting MySQL...\n"
function_stop_mysql
sleep 2
function_start_mysql
}
case $1 in 使用case语句进行条件判断调用哪个函数
start)
function_start_mysql
;;
stop)
function_stop_mysql
;;
restart)
function_restart_mysql
;;
*)
printf "Usage: ${mysql_basedir}/${port}/bin/mysqld {start|stop|restart}\n"
esac
把该脚本复制到各个数据库存放服务脚本的目录下,并把脚本中对应的端口号以及根目录路径进行更改
cp mysqld /data/mysql/3306/bin/
vim /data/mysql/3306/bin/mysqld
port=3306
mysql_basedir="/data/mysql"
cp /data/mysql/3306/bin/mysqld /data/mysql/3307/bin/mysqld
vim /data/mysql/3307/bin/mysqld
port=3307
cp /data/mysql/3306/bin/mysqld /data/mysql/3308/bin/mysqld
vim /data/mysql/3308/bin/mysqld
port=3308
服务开机自启动:
3306,3307,3308三个数据库都需要进行设置,这里以3306数据库为例:
cp /data/mysql/3306/bin/mysqld /etc/init.d/mysqld3306
vim /etc/init.d/mysqld3306
#!/bin/bash
#chkconfig: 345 20 80 添加服务启动和关闭级别
#description: mysql 3307 添加描述
chkconfig --add mysqld3306 把服务加入服务启动列表
注意:每个数据库的服务启动和关闭级别不能一样
或者把服务启动脚本存放到/etc/rc.local目录中
vim /etc/rc.local
/data/mysql/3306/bin/mysqld
/data/mysql/3307/bin/mysqld
/data/mysql/3308/bin/mysqld
对启动脚本增加执行权限
chmod +x /data/mysql/3306/bin/mysqld
chmod +x /data/mysql/3307/bin/mysqld
chmod +x /data/mysql/3308/bin/mysqld
至此,数据库各实例的用户、数据库文件、配置文件、服务启动脚本都已经准备完成
启动服务:
/data/mysql/3306/bin/mysqld start
/data/mysql/3307/bin/mysqld start
/data/mysql/3308/bin/mysqld start
连接数据库:
由于客户端和服务端在同一台主机上,因此可以通过本地socket文件连接数据库
mysql -S /data/mysql/3306/socket/mysql.sock 连接3306数据库
MariaDB [(none)]> show variables like "port"; 查看连接端口号
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| port | 3306 |
+---------------+-------+
1 row in set (0.01 sec)
[root@centos7 ~]# mysql -S /data/mysql/3306/socket/mysql.sock -e 'show variables like "port" ' 通过shell命令查看数据库端口号
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| port | 3306 |
+---------------+-------+
此时,数据库虽然创建完毕,但是数据库登录时却不需要口令,因此还需要对数据库设置登录口令
mysqladmin -uroot -S /data/mysql/3306/socket/mysql.sock password "centos123456"
通过端口号连接数据库
mysql -uroot -p -P 3306 -h127.0.0.1
[root@centos7 ~]# mysql -uroot -p -P 3306 -h127.0.0.1
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 1
Server version: 5.5.56-MariaDB MariaDB Server
Copyright (c) 2000, 2017, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]>
注意:在停止服务时,提示需要输入口令
[root@centos7 ~]# /data/mysql/3306/bin/mysqld stop
Stoping MySQL...
Enter password:
这是因为服务脚本中定义的提示服务函数中存在-p${mysql_pwd}选项
function_stop_mysql()
{
if [ ! -e "$mysql_sock" ];then
printf "MySQL is stopped...\n"
exit
else
printf "Stoping MySQL...\n"
${cmd_path}/mysqladmin -u ${mysql_user} -p${mysql_pwd} -S ${mysql_sock} shutdown
fi
}
但此时,启动服务脚本中设置的却是空口令
mysql_pwd=""
解决方法:
方法1:删除服务脚本定义函数中${cmd_path}/mysqladmin -u ${mysql_user} -p${mysql_pwd} -S ${mysql_sock} shutdown即可
方法2:先给3306端口号数据库添加口令,使用mysqlamdin命令添加口令
mysqladmin -uroot -S /data/mysql/3306/socket/mysql.sock password "centos123456"
然后再启动服务脚本中设置口令项添加设置的口令
mysql_pwd="centos123456"
同样的,3307和3308端口的数据库需要做同样的更改
3307端口号数据库:
设置口令
mysqladmin -uroot -S /data/mysql/3307/socket/mysql.sock password "centos123456"
更改服务脚本设置密码项
mysql_pwd="centos123456"
3308端口号数据库:
设置口令
mysqladmin -uroot -S /data/mysql/3308/socket/mysql.sock password "centos123456"
更改服务脚本设置密码项
mysql_pwd="centos123456"
注意:由于密码在服务脚本中以明文方式显示,因此脚本要做好保密措施。或者服务脚本中不写密码,在关闭服务时会出现输入密码提示,再输入密码即可注意:mysqld_multi该命令也可以实现多实例,但要求必须是同一个数据库版本
3、管理数据库和表
关系型数据库的常见组件
- 数据库:database
- 表:table
行:row
列:column - 索引:index
- 视图:view
- 用户:user
- 权限:privilege
- 存储过程:procedure,无返回值
- 存储函数:function,有返回值
- 触发器:trigger
- 事件调度器:event scheduler,任务计划
SQL语言的兴起于语法标准
- 20世纪70年代,IBM开发出SQL,用于DB2
- 1981年,IBM推出SQL/DS数据库
- 业内标准微软和Sybase的T-SQL,Oracle的PL/SQL
- SQL作为关系型数据库所使用的标准语言,最初是基于IBM的实现在1986年被批准的。1987年,“国际标准化组织(ISO)”把ANSI(美国国家标准化组织) SQL作为国际标准。
- SQL:ANSI SQL
SQL-1986, SQL-1989, SQL-1992, SQL-1999, SQL-2003 , SQL-2008,SQL-2011
SQL语言规范
- 在数据库系统中,SQL语句不区分大小写(建议用大写)
- SQL语句可单行或多行书写,以“;”结尾
- 关键词不能跨多行或简写
- 用空格和缩进来提高语句的可读性
- 子句通常位于独立行,便于编辑,提高可读性
- 注释:
SQL标准:
/*注释内容*/ 多行注释
--注释内容单行注释,注意有空格
MySQL注释:
#
数据库对象
- 数据库的组件(对象):
数据库、表、索引、视图、用户、存储过程、函数、触发器、事件调度器等 - 命名规则:
必须以字母开头
可包括数字和三个特殊字符(# _ $)
不要使用MySQL的保留字
同一database(Schema)下的对象不能同名
SQL语句分类
- SQL语句分类:
DDL: Data DefinationLanguage 数据定义语言
CREATE,DROP,ALTER
DML: Data Manipulation Language数据操纵语言
INSERT,DELETE,UPDATE
DCL:Data Control Language 数据控制语言
GRANT,REVOKE,COMMIT,ROLLBACK
DQL:Data Query Language 数据查询语言
SELECT
SQL语句构成
- SQL语句构成:
Keyword组成clause
多条clause组成语句
示例:
SELECT * SELECT子句
FROM products FROM子句
WHERE price>400 WHERE子句说明:一组SQL语句,由三个子句构成,SELECT,FROM和WHERE是关键字
数据库操作
- 创建数据库:
CREATE DATABASE|SCHEMA [IF NOT EXISTS] 'DB_NAME';
CHARACTER SET 'character set name' 定义子句的字符集
COLLATE 'collate name' 定义子句的排序规则
注意:字符集:推荐选择utf8编码,支持全世界的语言;utf8mb64编码,兼容性更高,支持表情包
示例:
create database db1; 创建数据库
show create database db1; 查看创建数据库命令
注意,数据库默认使用的编码为latin1,即拉丁语
create database db2 character set=utf8mb4; 创建数据库db2,并指定数据库使用的编码格式
show collation 查看排序规则,排序规则推荐使用默认即可- 删除数据库
DROP DATABASE|SCHEMA [IF EXISTS] 'DB_NAME'; - 查看支持所有字符集:SHOW CHARACTER SET;
- 查看支持所有排序规则:SHOW COLLATION;
- 获取命令使用帮助:
mysql> HELP KEYWORD; - 查看数据库列表:
mysql> SHOW DATABASES;
表
- 表:二维关系
- 设计表:遵循规范
- 定义:字段,索引
字段:字段名,字段数据类型,修饰符
约束,索引:应该创建在经常用作查询条件的字段上
创建表
- 创建表:CREATE TABLE
(1) 直接创建
示例:
直接创建表(可以分开多行书写):
MariaDB [db1]> create table students (
-> id int unsigned AUTO_INCREMENT primary key,
-> name varchar (50) NOT NULL,
-> sex enum('m','f'), 性别定义使用枚举(在男和女之间选其中一个)
-> age tinyint unsigned default 20
-> );
show create table students; 查看表的创建
desc students 查看表结构的定义(2) 通过查询现存表创建;新表会被直接插入查询而来的数据
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name[(create_definition,...)] [table_options] [partition_options]select_statement
示例:
select * from 表名; 查看数据库中的某张表
create table newstudents seletc * from students; 查询students表,把表结构和信息导入newstudents表中
MariaDB [hellodb]> select * from newstudents; 此命令查看新表newstudents的内容
MariaDB [hellodb]> desc newstudents; 查看新表的表结构
+-----------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------------------+------+-----+---------+-------+
| StuID | int(10) unsigned | NO | | 0 | |
| Name | varchar(50) | NO | | NULL | |
| Age | tinyint(3) unsigned | NO | | NULL | |
| Gender | enum('F','M') | NO | | NULL | |
| ClassID | tinyint(3) unsigned | YES | | NULL | |
| TeacherID | int(10) unsigned | YES | | NULL | |
+-----------+---------------------+------+-----+---------+-------+
6 rows in set (0.01 sec)
MariaDB [hellodb]> desc students; 查看旧表的表结构
+-----------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------------------+------+-----+---------+----------------+
| StuID | int(10) unsigned | NO | PRI | NULL | auto_increment |
| Name | varchar(50) | NO | | NULL | |
| Age | tinyint(3) unsigned | NO | | NULL | |
| Gender | enum('F','M') | NO | | NULL | |
| ClassID | tinyint(3) unsigned | YES | | NULL | |
| TeacherID | int(10) unsigned | YES | | NULL | |
+-----------+---------------------+------+-----+---------+----------------+
6 rows in set (0.01 sec)跨数据库创建表
示例:
在db1数据库中创建newstudents表,从hellodb数据库复制students表的结构和内容
MariaDB [db1]> create table newstudents select * from hellodb.students;
Query OK, 25 rows affected (0.01 sec)
Records: 25 Duplicates: 0 Warnings: 0
查询表
MariaDB [db1]> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| newstudents |
| students |
+---------------+
2 rows in set (0.00 sec)
查询表内容
MariaDB [db1]> select * from newstudents;(3) 通过复制现存的表的表结构创建,但不复制数据
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name{ LIKE old_tbl_name| (LIKE old_tbl_name) }
示例:
MariaDB [db1]> create table test like newstudents; 创建新表test,该表为空表
查看两张表的表结构,发现表结构一致
MariaDB [db1]> desc test;
+-----------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------------------+------+-----+---------+-------+
| StuID | int(10) unsigned | NO | | 0 | |
| Name | varchar(50) | NO | | NULL | |
| Age | tinyint(3) unsigned | NO | | NULL | |
| Gender | enum('F','M') | NO | | NULL | |
| ClassID | tinyint(3) unsigned | YES | | NULL | |
| TeacherID | int(10) unsigned | YES | | NULL | |
+-----------+---------------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
MariaDB [db1]> desc newstudents;
+-----------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------------------+------+-----+---------+-------+
| StuID | int(10) unsigned | NO | | 0 | |
| Name | varchar(50) | NO | | NULL | |
| Age | tinyint(3) unsigned | NO | | NULL | |
| Gender | enum('F','M') | NO | | NULL | |
| ClassID | tinyint(3) unsigned | YES | | NULL | |
| TeacherID | int(10) unsigned | YES | | NULL | |
+-----------+---------------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
查看test表的内容,发现新表test为空
MariaDB [db1]> select * from test;
Empty set (0.00 sec)知识扩展:
使用以下语法也可以只复制表结构,不复制表内容
create table test2 newstudents select * from hellodb.students where 1=0;
在第二种语法的基础之上,添加一条不成立的判断语句where 1=0即可另外,数据库在5.5版本中,数据库存在一个缺点:数据库文件所在目录中,数据被集中存放在一个表ibdata1中,并没有存放各自的目录下如(db1,db2,hellodb等),各自目录下只是存放了表的定义,管理起来非常不方便。而10以上版本mariadb数据库则没有这种缺点.
解决方法:
在配置文件/etc/my.cnf中添加innodb_file_per_table=on即可
在之前编译安装数据库准备配置文件时,我们提到过该项
vim /etc/my.cnf
innodb_file_per_table=on 是指存放表时,每张表分开存放更改后重启数据库
systemctl restart mariadb
如果再添加新的数据库,每张表将会分开存放
- 注意:
Storage Engine是指表类型,也即在表创建时指明其使用的存储引擎,同一库中不同表可以使用不同的存储引擎
同一个库中表建议要使用同一种存储引擎类型
CREATE TABLE [IF NOT EXISTS] ‘tbl_name’ (col1 type1 修饰符, col2 type2 修饰符, ...) - 字段信息
col type1 字段类型
PRIMARY KEY(col1,...) 主键
INDEX(col1, ...) 索引
UNIQUE KEY(col1, ...) 惟一键 - 表选项:
ENGINE [=] engine_name 存储引擎名称
SHOW ENGINES;查看支持的engine类型
ROW_FORMAT [=] {DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT} - 获取帮助:mysql> HELP CREATE TABLE;
表操作
- 查看所有的引擎:SHOW ENGINES
- 查看表:SHOW TABLES [FROM db_name]
- 查看表结构:DESC [db_name.]tb_name
- 删除表:DROP TABLE [IF EXISTS] tb_name
- 查看表创建命令:SHOW CREATE TABLE tbl_name
- 查看表状态:SHOW TABLE STATUS LIKE 'tbl_name'
- 查看库中所有表状态:SHOW TABLE STATUS FROM db_name
数据类型
- 数据类型:
数据长什么样?
数据需要多少空间来存放? - 系统内置数据类型和用户定义数据类型
- MySql支持多种列类型:
数值类型
日期/时间类型
字符串(字符)类型
https://dev.mysql.com/doc/refman/5.5/en/data-types.html - 选择正确的数据类型对于获得高性能至关重要,三大原则:
更小的通常更好,尽量使用可正确存储数据的最小数据类型
简单就好,简单数据类型的操作通常需要更少的CPU周期
尽量避免NULL,包含为NULL的列,对MySQL更难优化
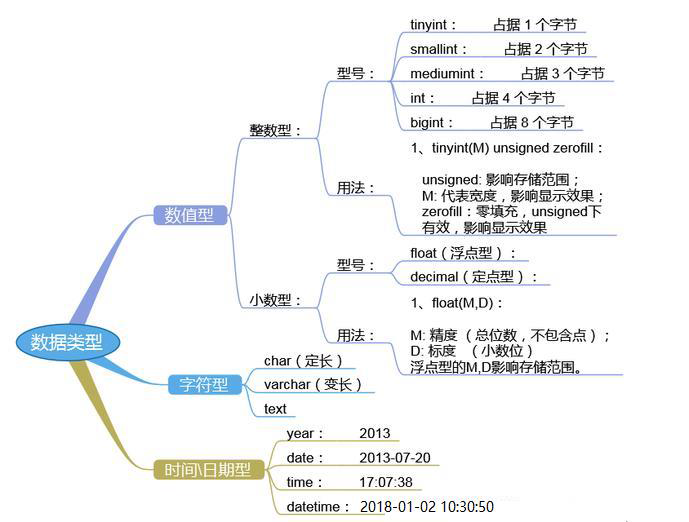
数据类型
- 1、整型
tinyint(m) 1个字节范围(-128~127) smallint(m) 2个字节范围(-32768~32767) mediumint(m) 3个字节范围(-8388608~8388607) int(m) 4个字节范围(-2147483648~2147483647) bigint(m) 8个字节范围(+-9.22*10的18次方)加了unsigned,则最大值翻倍,如:tinyintunsigned的取值范围为(0~255)
int(m)里的m是表示SELECT查询结果集中的显示宽度,并不影响实际的取值范围,规定了MySQL的一些交互工具(例如MySQL命令行客户端)用来显示字符的个数。对于存储和计算来说,Int(1)和Int(20)是相同的
BOOL,BOOLEAN:布尔型,是TINYINT(1)的同义词。zero值被视为假,非zero值视为真 - 2、浮点型(float和double),近似值
float(m,d) 单精度浮点型8位精度(4字节) m总个数,d小数位
double(m,d)双精度浮点型16位精度(8字节) m总个数,d小数位
设一个字段定义为float(6,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位 - 3、定点数
在数据库中存放的是精确值,存为十进制
decimal(m,d) 参数m\<65 是总个数,d\<30且d\<m 是小数位
MySQL5.0和更高版本将数字打包保存到一个二进制字符串中(每4个字节存9个数字)。例如,decimal(18,9)小数点两边将各存储9个数字,一共使用9个字节:小数点前的数字用4个字节,小数点后的数字用4个字节,小数点本身占1个字节
浮点类型在存储同样范围的值时,通常比decimal使用更少的空间。float使用4个字节存储。double占用8个字节
因为需要额外的空间和计算开销,所以应该尽量只在对小数进行精确计算时才使用decimal——例如存储财务数据。但在数据量比较大的时候,可以考虑使用bigint代替decima - 4、字符串(char,varchar,_text)
说明:
char(n) 固定长度,最多255个字符
varchar(n) 可变长度,最多65535个字符
tinytext 可变长度,最多255个字符
text 可变长度,最多65535个字符
mediumtext 可变长度,最多2的24次方-1个字符
longtext 可变长度,最多2的32次方-1个字符
BINARY(M) 固定长度,可存二进制或字符,长度为0-M字节
VARBINARY(M) 可变长度,可存二进制或字符,允许长度为0-M字节
内建类型:ENUM枚举, SET集合- char和varchar:
(1)char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉。所以char类型存储的字符串末尾不能有空格,varchar不限于此。
(2)char(n) 固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节(n< n>255),所以varchar(4),存入3个字符将占用4个字节。
(3)char类型的字符串检索速度要比varchar类型的快

- varchar和text:
(1)varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n< n>255),text是实际字符数+2个字节。
(2)text类型不能有默认值
(3)varchar可直接创建索引,text创建索引要指定前多少个字符。varchar查询速度快于text - 5.二进制数据:BLOB
BLOB和text存储方式不同,TEXT以文本方式存储,英文存储区分大小写,而Blob是以二进制方式存储,不分大小写
BLOB存储的数据只能整体读出
TEXT可以指定字符集,BLOB不用指定字符集 - 6.日期时间类型
说明:
date 日期'2008-12-2'
time 时间'12:25:36'
datetime 日期时间'2008-12-2 22:06:44'
timestamp 自动存储记录修改时间
YEAR(2), YEAR(4):年份timestamp字段里的时间数据会随其他字段修改的时候自动刷新,这个数据类型的字段可以存放这条记录最后被修改的时间
修饰符
- 所有类型:
说明:
NULL 数据列可包含NULL值
NOT NULL 数据列不允许包含NULL值
DEFAULT 默认值
PRIMARY KEY 主键
UNIQUE KEY 唯一键
CHARACTER SET name 指定一个字符集- 数值型
说明:
AUTO_INCREMENT 自动递增,适用于整数类型
UNSIGNED 无符号示例:
CREATE TABLE students (id int UNSIGNED NOT NULL PRIMARY KEY,name VARCHAR(20)NOT NULL,age tinyint UNSIGNED);
DESC students;
CREATE TABLE students2 (id int UNSIGNED NOT NULL ,name VARCHAR(20) NOT NULL,age tinyint UNSIGNED,PRIMARY KEY(id,name));表操作
- DROP TABLE [IF EXISTS] 'tbl_name';
- ALTER TABLE 'tbl_name'
字段:
添加字段:add
ADD col1 data_type[FIRST|AFTER col_name]
删除字段:drop
修改字段:
alter(默认值), change(字段名), modify(字段属性)
索引:
添加索引:add index
删除索引:drop index
表选项
修改: - 查看表上的索引:SHOW INDEXES FROM [db_name.]tbl_name;
- 查看帮助:Help ALTER TABLE
示例:修改表
ALTER TABLE students RENAME s1;
ALTER TABLE s1 ADD phone varchar(11) AFTER name;
ALTER TABLE s1 MODIFY phone int;
ALTER TABLE s1 CHANGE COLUMN phone mobile char(11);
ALTER TABLE s1 DROP COLUMN mobile;
Help ALTER TABLE 查看帮助
ALTER TABLE students ADD gender ENUM('m','f')
ALETR TABLE students CHANGE id sid int UNSIGNED NOT NULL PRIMARY KEY;
ALTER TABLE students ADD UNIQUE KEY(name);
ALTER TABLE students ADD INDEX(age);
DESC students;
SHOW INDEXES FROM students;
ALTER TABLE students DROP age;DML语句
- DML: INSERT, DELETE, UPDATE
- INSERT:
一次插入一行或多行数据
语法:
(1)INSERT [L OW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name[(col_name,...)]
{VALUES | VALUE} ({expr | DEFAULT},...),(...),...
[ ON DUPLICATE KEY UPDATE 如果重复更新之
col_name=expr
[, col_name=expr] ... ]
简化写法:
INSERT tbl_name[(col1,...)] VALUES (val1,...), (val21,...)
示例:
一次性添加一条记录
insert into students (name,phone,sex,age)values('mage','10086','m','30');
一次性添加多条记录
MariaDB [db1]> insert into students (name,phone,sex,age)values('wang','10000','m','20'),('li','111111','m','20');(2)INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
SET col_name={expr | DEFAULT}, ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
示例:
把其他数据库的表导入数据库中
insert ... select 写法
insert into students(name,phone,sex,age) select name,phone,sex,age from db1.students;
注意:数据类型必须一致(3)INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name[(col_name,...)]
SELECT ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
示例:
把其他数据库的表导入数据库中
insert ... set写法
insert into students set name='han',sex='m';- UPDATE:
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET col_name1={expr1|DEFAULT} [, col_name2={expr2|DEFAULT}] ...
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count] - 注意:一定要有限制条件,否则将修改所有行的指定字段
限制条件:
WHERE
LIMIT
示例:
update students set sex='f' where id=5;
可同时更改多个字段:
update students set name='li',sex='f' where id=5;
把id为5的字段名字和性别进行更改- Mysql选项:-U|--safe-updates| --i-am-a-dummy
示例:
数据库修改时一定要添加限制条件,否则将修改所有行的指定字段
为了避免出现忘记添加限制条件,可以使用以下选项:
在登录数据库时,加上-U选项,即mysql -U -uroot -p
加上-U选项后,如果在数据库中执行命令忘记添加限制条件时,会出现错误信息
MariaDB [db2]> update students set name='li',sex='f';
ERROR 1175 (HY000): You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column
为了使用方便,实现不输入-U选项也会有错误提示
在数据库客户端配置文件mysql语句块中添加safe-updates
vim /etc/my.cnf.d/mysql-clients.cnf
[mysql]
safe-updates- DELETE:
- DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
可先排序再指定删除的行数 - 注意:一定要有限制条件,否则将清空表中的所有数据
限制条件:
WHERE
LIMIT - TRUNCATE TABLE tbl_name; 清空表
-U选项也适用与delete命令,可以避免出现忘记条件限制删除全部记录的情况
DQL语句
- SELECT语法:
[ALL | DISTINCT | DISTINCTROW ]
[SQL_CACHE | SQL_NO_CACHE]
select_expr[, select_expr...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name| expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name| expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count| row_countOFFSET offset}]
[FOR UPDATE | LOCK IN SHARE MODE]
SELECT相关用法
- 字段显示可以使用别名:
col1 AS alias1, col2 AS alias2, ...
示例:
select stuid as 学员编号,name 姓名,age 年龄 from students; 把关键字段以中文显示,而且字段显示的前后顺序可以自定义
+--------------+---------------+--------+
| 学员编号 | 姓名 | 年龄 |
+--------------+---------------+--------+
| 1 | Shi Zhongyu | 22 |
| 2 | Shi Potian | 22 |
| 3 | Xie Yanke | 53 |
| 4 | Ding Dian | 32 |
| 5 | Yu Yutong | 26 |
| 6 | Shi Qing | 46 |
+--------------+---------------+--------+- WHERE子句:指明过滤条件以实现“选择”的功能:
过滤条件:布尔型表达式
算术操作符:+, -, *, /, %
比较操作符:=,<=>(相等或都为空), <>, !=(非标准SQL), >, >=, <, <=
BETWEEN min_num AND max_num
IN (element1, element2, ...)
IS NULL
IS NOT NULL - DISTINCT 去除重复列
SELECT DISTINCT gender FROM students; - LIKE:
%: 任意长度的任意字符
_:任意单个字符 - RLIKE:正则表达式,索引失效,不建议使用
- REGEXP:匹配字符串可用正则表达式书写模式,同上
- 逻辑操作符:
NOT
AND
OR
XOR - GROUP:根据指定的条件把查询结果进行“分组”以用于做“聚合”运算
avg(), max(), min(), count(), sum()
HAVING: 对分组聚合运算后的结果指定过滤条件 - ORDER BY: 根据指定的字段对查询结果进行排序
升序:ASC
降序:DESC - LIMIT [[offset,]row_count]:对查询的结果进行输出行数数量限制
- 对查询结果中的数据请求施加“锁”
FOR UPDATE: 写锁,独占或排它锁,只有一个读和写
LOCK IN SHARE MODE: 读锁,共享锁,同时多个读
示例:
比较操作符
select * from students where classid=1; 挑选出students表中班级编号为1的学员
注意:这里表名大小写敏感,书写时要与表名一致;而字段名则大小写不敏感,不用与表中字段名一致,但为了使得命令规范化,尽量使其与原内容格式保持一致。
select * from students where age > 30 and age <50;
between and 命令:
select * from students where age between 30 and 50;
挑出students表中年龄大于30小于50岁的学员
这两种写法类似,但是要注意,between and命令表示闭区间,包括30和50;而大于和小于号则是开区间,并不包括30和50
in命令:
select * from students where classid in (1,2,3);
IS NULL和IS NOT NULL命令:
select * from students where teacherid is null;
select * from students where teacherid is not null;
distinct 去除重复列
select distinct classid from students ;
like:支持通配符
% 匹配任意长度的字符
select * from students where name like 's%'; 选择以s开头的学员
select * from students where name like '%o'; 选择以o结尾的学员
建议使用左前缀写法,即's%',因为在性能优化方面,右后缀写法'%o'和包含写法'%o%'会带来性能的影响
rlike和regexp:支持正则表达式
select * from students where name rlike '^s';
这种写法不推荐使用,因为这种写法性能更差
order by:排序
select * from students order by age; 以年龄排序,默认正序排序
select * from students order by age desc; 倒序排序
默认排序是根据排序规则进行排序的
show character set; 查看默认排序规则
简体中文 gb2312
LIMIT [[offset,]row_count]: 对显示结果进行行数数量限制
select * from students limit 3;
limit 2,3 2是指偏移量,3是指显示行数
select * from students order by age limit 2,3; 是指跳过前两个,显示后三个
group:分组,分类别
count() 函数 返回select命令中检索到的行中非null值的数目
注意()内的字段的值为非空字段,即该字段的值中不能出现null,否则将不能查询出准确的值
MariaDB [hellodb]> select count(*) from students ;
+----------+
| count(*) |
+----------+
| 25 |
+----------+
1 row in set (0.00 sec)
select classid,count(*) from students group by classid ;
统计每个班级中的人数,即以班级id为分组,统计每个班级中的总人数
一旦做分组,select 后跟的语句必须是两种内容:第一,要写分组本身,第二,要跟聚合函数,即做汇总的数据,如:最大值max,最小值min,平均值avg等
如:
select classid,min(age) from students group by classid ;
统计每个班级中最小年龄的人
先分组再做过滤
注意:一旦分组,如果要在分组后再做条件过滤,则不能使用where,而是要使用having
select classid,avg(age) from students group by classid having classid in (1,2);
统计students表中1班2班的平均年龄
select classid,avg(age) from students where gender = 'm' group by classid having classid in (1,2);
统计1班2班中男生的平均年龄
注意:如果先过滤后分组,则还是使用where
对多个字段分组:
select classid,gender,count(*) from students group by classid,gender;
统计每个班级中的男生女生分别有几个,即以班级作为分组后,再以性别作为分组进行统计
select * from students where birth between '1988-01-01 00:00:00' and '1998-12-31 00:00:00';
从student表中查询出生日期在1988年到1998年的人练习:
导入hellodb.sql生成数据库
(1) 在students表中,查询年龄大于25岁,且为男性的同学的名字和年龄
select * from students where age > 25 and gender='M';
(2) 以ClassID为分组依据,显示每组的平均年龄
select avg(age) from students group by classid;
(3) 显示第2题中平均年龄大于30的分组及平均年龄
select classid,avg(age) from students group by classid having avg(age) > 30;
(4) 显示以L开头的名字的同学的信息
select * from students where name like 'L%';
或select * from students where name rlike '^L';
(5) 显示TeacherID非空的同学的相关信息
select * from students where teacherid is not null;
(6) 以年龄排序后,显示年龄最大的前10位同学的信息
select * from students order by age desc limit 10 ;
(7) 查询年龄大于等于20岁,小于等于25岁的同学的信息
select * from students where age between 20 and 25;
注意:大于小于号为开区间,不包括20或25.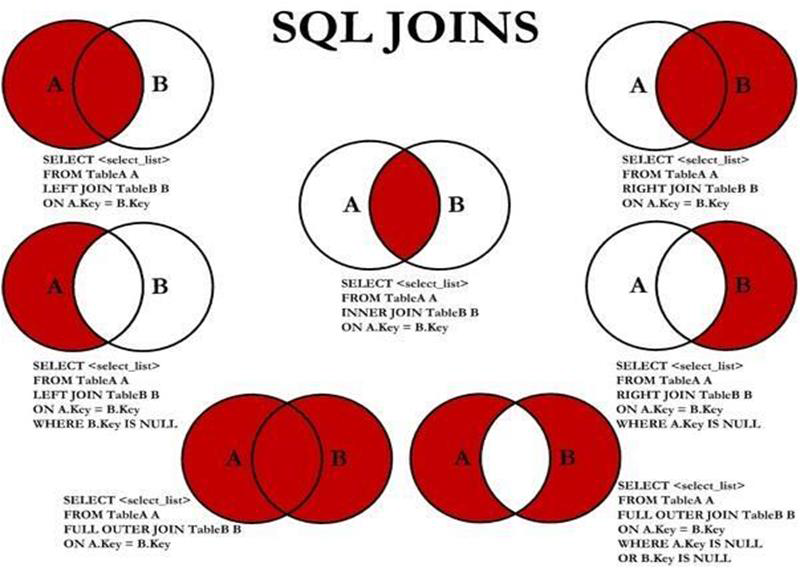
多表查询
- 交叉连接:笛卡尔乘积
- 内连接:
等值连接:让表之间的字段以“等值”建立连接关系;
不等值连接
自然连接:去掉重复列的等值连接
自连接 - 外连接:
左外连接:
FROM tb1 LEFT JOIN tb2 ON tb1.col=tb2.col
右外连接
FROM tb1 RIGHT JOIN tb2 ON tb1.col=tb2.col - 子查询:在查询语句嵌套着查询语句,性能较差
基于某语句的查询结果再次进行的查询 - 用在WHERE子句中的子查询:
用于比较表达式中的子查询;子查询仅能返回单个值
SELECT Name,AgeFROM students WHERE Age>(SELECT avg(Age) FROM students);
用于IN中的子查询:子查询应该单键查询并返回一个或多个值从构成列表
SELECT Name,AgeFROM students WHERE Age IN (SELECT Age FROM teachers);
用于EXISTS - 用于FROM子句中的子查询
使用格式:SELECT tb_alias.col1,... FROM (SELECT clause) AS tb_aliasWHERE Clause;
示例:
SELECT s.aage,s.ClassIDFROM (SELECT avg(Age) AS aage,ClassIDFROM students WHERE ClassIDIS NOT NULL GROUP BY ClassID) AS s WHERE s.aage>30;- 联合查询:UNION
SELECT Name,AgeFROM students UNION SELECT Name,AgeFROM teachers
练习:
导入hellodb.sql,以下操作在students表上执行
1、以ClassID分组,显示每班的同学的人数
select classid,class,numofstu from classes;
2、以Gender分组,显示其年龄之和
select count(age) from students group by gender;
3、以ClassID分组,显示其平均年龄大于25的班级
select classid,avg(age) from students group by classid having avg(age) > 25;
4、以Gender分组,显示各组中年龄大于25的学员的年龄之和
select gender,sum(age) from students where age > 25 group by gender;
5、显示前5位同学的姓名、课程及成绩
select student_name,course,score from courses as c inner join (select st.name as student_name,courseid,score from scores as sc inner join (select * from students limit 5) as st on st.stuid=sc.stuid )as a on c.courseid=a.courseid;
6、显示其成绩高于80的同学的名称及课程;
select student_name,course,score from courses as c inner join (select st.name as student_name,courseid,score from scores as sc inner join (select * from students limit 5) as st on st.stuid=sc.stuid group by name)as a on c.courseid=a.courseid having score > 80;
7、求前8位同学每位同学自己两门课的平均成绩,并按降序排列
select st.name as student_name,avg(score) as sc_avg from students as st inner join scores as sc on st.stuid=sc.stuid group by st.stuid order by sc_avg desc;
8、显示每门课程课程名称及学习了这门课的同学的个数
select c.course,count(stuid) as studnet_count from scores as s left join courses as c on s.courseid=c.courseid group by s.courseid;
9、显示其年龄大于平均年龄的同学的名字
`select name from students where age > (select avg(age) from students);`
10、显示其学习的课程为第1、2,4或第7门课的同学的名字
select name from students as st inner join (select distinct sc.stuid from scores as sc inner join (select * from courses where courseid in(1,2,4) or courseid in (7)) as c on sc.courseid=c.courseid) as a on st.stuid=a.stuid;
11、显示其成员数最少为3个的班级的同学中年龄大于同班同学平均年龄的同学
select student.name,student.age,student.classid,second.avg_age from (select students.name as name ,students.age as age,students.classid as classid from students left join (select count(name) as num,classid as classid from students group by classid having num>=3) as first on first.classid=students.classid) as student,(select avg(age) as avg_age,classid as classid from students group by classid) as second where student.age>second.avg_age and student.classid=second.classid;
12、统计各班级中年龄大于全校同学平均年龄的同学
select name,classid,age from students where age > (select avg(age) from students); 视图
- 视图:VIEW,虚表,保存有实表的查询结果
例如,把内连接或外连接查询出来的结果定义为视图,使用该视图可直接查询出内连接或外连接查询出的结果,类似于给查询结果定义一个别名
但是,视图本身不保存查询出来的数据,只显示查询出来的结果,数据来自于实际的表 - 创建方法:
CREATE VIEW view_name[(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION] - 查看视图定义:SHOW CREATE VIEW view_name
- 删除视图:
DROP VIEW [IF EXISTS]
view_name[, view_name] ...
[RESTRICT | CASCADE] - 视图中的数据事实上存储于“基表”中,因此,其修改操作也会针对基表实现;其修改操作受基表限制
4、函数和存储过程
函数
- 函数:系统函数和自定义函数
系统函数:https://dev.mysql.com/doc/refman/5.7/en/func-op-summary-ref.html - 自定义函数(user-defined function UDF)
保存在mysql.proc表中
创建UDF:
CREATE [AGGREGATE] FUNCTION function_name(parameter_nametype,[parameter_nametype,...])
RETURNS {STRING|INTEGER|REAL}
runtime_body
说明:
参数可以有多个,也可以没有参数
必须有且只有一个返回值
自定义函数
- 查看函数列表:
SHOW FUNCTION STATUS; - 查看函数定义
SHOW CREATE FUNCTION function_name - 删除UDF:
DROP FUNCTION function_name - 调用自定义函数语法:
SELECT function_name(parameter_value,...)
示例:无参UDF
CREATE FUNCTION simpleFun() RETURNS VARCHAR(20) RETURN "Hello World!";
示例:有参数UDF
DELIMITER //
CREATE FUNCTION deleteById(uidSMALLINT UNSIGNED) RETURNS VARCHAR(20)
BEGIN
DELETE FROM students WHERE stuid= uid;
RETURN (SELECT COUNT(uid) FROM students);
END//
DELIMITER ;- 自定义函数中定义局部变量语法:
DECLARE 变量1[,变量2,... ]变量类型[DEFAULT 默认值] - 说明:局部变量的作用范围是在BEGIN...END程序中,而且定义局部变量语句必须在BEGIN...END的第一行定义
示例: 删除一条记录,返回删除后表的总记录的值
DELIMITER //
CREATE FUNCTION addTwoNumber(x SMALLINT UNSIGNED, Y SMALLINT UNSIGNED)
RETURNS SMALLINT
BEGIN
DECLARE a, b SMALLINT UNSIGNED;
SET a = x, b = y;
RETURN a+b;
END//
DELIMITER ;
MariaDB [hellodb]> select deletebyid(26); 调用该函数,student表记录总数为26
+----------------+
| deletebyid(26) |
+----------------+
| 25 | 返回值为25
+----------------+
1 row in set (0.01 sec)在数据库中,分号表示命令输入结束,开始执行命令,为了不让分号作为命令执行的标记符号,
使用命令DELIMITER把//代替分号作为命令执行的标记,即DELIMITER //,在命令最后再次输入//表示输入命令结束,开始执行命令。
最后的DELIMITER ;表示把命令执行的标记符号从//更改为分号
- 为变量赋值语法
SET parameter_name= value[,parameter_name= value...]
SELECT INTO parameter_name
示例:
...
DECLARE x int;
SELECT COUNT(id) FROM tdb_nameINTO x;
RETURN x;
END//
select addtwonumber(10,20) as sum 给函数定义别名存储过程
- 存储过程:存储过程保存在mysql.proc表中
- 创建存储过程
CREATE PROCEDURE sp_name ([ proc_parameter [,proc_parameter ...]])
routime_body
其中:proc_parameter : [IN|OUT|INOUT] parameter_name type
其中IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出;param_name表示参数名称;type表示参数的类型 - 查看存储过程列表
SHOW PROCEDURE STATUS - 查看存储过程定义
SHOW CREATE PROCEDURE sp_name - 调用存储过程
CALL sp_name ([ proc_parameter [,proc_parameter ...]])
CALL sp_name
说明:当无参时,可以省略"()",当有参数时,不可省略"()” - 存储过程修改
ALTER语句修改存储过程只能修改存储过程的注释等无关紧要的东西,不能修改存储过程体,所以要修改存储过程,方法就是删除重建 - 删除存储过程
DROP PROCEDURE [IF EXISTS] sp_name
示例1:创建无参存储过程
delimiter //
CREATE PROCEDURE showTime()
BEGIN
SELECT now();
END//
delimiter ;
CALL showTime; #调用函数示例2:创建含参存储过程:只有一个IN参数
delimiter //
CREATE PROCEDURE selectById(IN uid SMALLINT UNSIGNED)
BEGIN
SELECT * FROM students WHERE stuid = uid;
END//
delimiter ;
call selectById(2); 调用函数示例3:
delimiter //
CREATE PROCEDURE dorepeat(n INT)
BEGIN
SET @i = 0;
SET @sum = 0;
REPEAT SET @sum = @sum+@i; SET @i = @i + 1;
UNTIL @i > n END REPEAT;
END//
delimiter ;
CALL dorepeat(100);
SELECT @sum;示例4:创建含参存储过程:包含IN参数和OUT参数
delimiter //
CREATE PROCEDURE deleteById(IN uid SMALLINT UNSIGNED, OUT num SMALLINT UNSIGNED) #num的值为删除的函数
BEGIN
DELETE FROM students WHERE stuid = uid; #删除stuid=uid的记录
SELECT row_count() into num; #把修改过行的记录数传给num
#row_count() 系统内置函数,修改过的行的记录数
END//
delimiter ;
call deleteById(2,@Line); #调用存储过程并对IN和OUT进行赋值
SELECT @Line; #显示@Line的值说明:创建存储过程deleteById,包含一个IN参数和一个OUT参数.
调用时,传入删除的ID和保存被修改的行数值的用户变量@Line.
select @Line;是指输出被影响行数
- 存储过程优势
存储过程把经常使用的SQL语句或业务逻辑封装起来,预编译保存在数据库中,当需要时从数据库中直接调用,省去了编译的过程
提高了运行速度
同时降低网络数据传输量 - 存储过程与自定义函数的区别
存储过程实现的过程要复杂一些,而函数的针对性较强
存储过程可以有多个返回值,而自定义函数只有一个返回值
存储过程一般独立的来执行,而函数往往是作为其他SQL语句的一部分来使用
流程控制
- 存储过程和函数中可以使用流程控制来控制语句的执行
- 流程控制:
IF:用来进行条件判断。根据是否满足条件,执行不同语句
CASE:用来进行条件判断,可实现比IF语句更复杂的条件判断
LOOP:重复执行特定的语句,实现一个简单的循环
LEAVE:用于跳出循环控制
ITERATE:跳出本次循环,然后直接进入下一次循环
REPEAT:有条件控制的循环语句。当满足特定条件时,就会跳出循环语句
WHILE:有条件控制的循环语句
触发器
- 触发器的执行不是由程序调用,也不是由手工启动,而是由事件来触发、激活从而实现执行
- 创建触发器
CREATE
[DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
trigger_body - 说明:
trigger_name:触发器的名称
trigger_time:{ BEFORE | AFTER },表示在事件之前或之后触发before 在事件发生之前执行某操作,该操作完成后,原有事件的操作将不会执行,即触发器执行的操作代替事件的操作 after 在事件发生之后执行某操作,该操作完成后,原有事件的操作将继续进行trigger_event::{ INSERT |UPDATE | DELETE },触发的具体事件
tbl_name:该触发器作用在表名
示例1:
CREATE TABLE student_info (
stu_id INT(11) NOT NULL AUTO_INCREMENT,
stu_name VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (stu_id)
);
CREATE TABLE student_count (
student_count INT(11) DEFAULT 0
);
INSERT INTO student_count VALUES(0);示例2:创建触发器,在向学生表INSERT数据时,学生数增加,DELETE学生时,学生数减少
CREATE TRIGGER trigger_student_count_insert
AFTER INSERT
ON student_info FOR EACH ROW
UPDATE student_count SET student_count=student_count+1;
CREATE TRIGGER trigger_student_count_delete
AFTER DELETE
ON student_info FOR EACH ROW
UPDATE student_count SET student_count=student_count-1;- 查看触发器
SHOW TRIGGERS
查询系统表information_schema.triggers的方式指定查询条件,查看指定的触发器信息。mysql> USE information_schema; Database changed mysql> SELECT * FROM triggers WHERE trigger_name='trigger_student_count_insert'; - 删除触发器
DROP TRIGGER trigger_name;
5、MySQL用户和权限管理
- 元数据数据库:mysql
系统授权表:
db, host, user
columns_priv, tables_priv, procs_priv, proxies_priv - 用户账号:
'USERNAME'@'HOST':
@'HOST':
主机名;
IP地址或Network;
通配符: % _
示例:172.16.%.%
用户管理
- 创建用户:CREATE USER
CREATE USER 'USERNAME'@'HOST' [IDENTIFIED BY 'password'];
默认权限:USAGE
create user test@'192.168.32.129' identified by 'centos';
知识扩展:
在192.168.32.129主机的/etc/hosts文件中写入192.168.32.130主机的ip与域名的对应关系
vim /etc/hosts
192.168.32.130 centos7.localdomain centos7.localdomain为130主机的主机名
则可以使用以下方式连接数据库
mysql -utest -pcentos123456 -hcentos7.localdomain 说明数据库把主机名解析为192.168.32.130连接数据库- 用户重命名:RENAME USER
RENAME USER old_user_name TO new_user_name - 删除用户:
DROP USER 'USERNAME'@'HOST'
示例:删除默认的空用户
DROP USER ''@'localhost';
- 修改密码:
mysql>SET PASSWORD FOR 'user'@'host' = PASSWORD(‘password');
mysql>UPDATE mysql.user SET password=PASSWORD('password') WHERE clause;
此方法需要执行下面指令才能生效:
mysql> FLUSH PRIVILEGES;
#mysqladmin -u root -poldpass password 'newpass' - 忘记管理员密码的解决办法:
启动mysqld进程时,为其使用如下选项:
--skip-grant-tables
--skip-networking
使用UPDATE命令修改管理员密码
关闭mysqld进程,移除上述两个选项,重启mysqld
实验:破解mysql数据库管理员密码
如何破解mysql管理员密码
(1)更改配置文件
vim /etc/my.cnf
[mysqld]
skip-grant-tables 启动数据库服务时,不检查授权表
skip-networking 生产环境中,为了防止其他用户在破解口令时连接数据库,处于维护模式,禁止其他用户登录
(2)重启数据库服务
systemctl restart mariadb
(3)再次连接数据库,无需密码
[root@centos7-1 ~]#mysql
清除或更改密码
update mysql.user set password = ''; 设置密码为空
flush privileges; update命令通过更改表的方式清空密码,因此需要刷新策略
(4)删除配置文件/etc/my.cnf中的skip-grant-tables和skip-networking,回复原有配置信息
重启数据库服务,再次连接数据库
如果是多实例配置数据库,只需在服务脚本中增加--skip-grant-tables即可
${cmd_path}/mysqld_safe --skip-grant-tables --defaults-file=${mysql_basedir}/${port}/etc/my.cnf &> /dev/null MySQL权限管理
- 权限类别:
管理类
程序类
数据库级别
表级别
字段级别 - 管理类
CREATE TEMPORARY TABLES
CREATE USER
FILE
SUPER
SHOW DATABASES
RELOAD
SHUTDOWN
REPLICATION SLAVE
REPLICATION CLIENT
LOCK TABLES
PROCESS - 程序类: FUNCTION、PROCEDURE、TRIGGER
CREATE
ALTER
DROP
EXCUTE - 库和表级别:DATABASE、TABLE
ALTER
CREATE
CREATE VIEW
DROP
INDEX
SHOW VIEW
GRANT OPTION:能将自己获得的权限转赠给其他用户 - 数据操作:
SELECT
INSERT
DELETE
UPDATE - 字段级别:
SELECT(col1,col2,...)
UPDATE(col1,col2,...)
INSERT(col1,col2,...) - 所有权限:ALL PRIVILEGES 或 ALL
授权
参考:https://dev.mysql.com/doc/refman/5.7/en/grant.html
- 语法:
GRANT priv_type [(column_list)],... ON [object_type] priv_level TO 'user'@'host' [IDENTIFIED BY 'password'] [WITH GRANT OPTION]; priv_type: ALL [PRIVILEGES] object_type:TABLE | FUNCTION | PROCEDURE priv_level: *(所有库) | *.* | db_name.* | db_name.tbl_name | tbl_name(当前库的表) | db_name.routine_name(指定库的函数,存储过程,触发器) with_option: GRANT OPTION | MAX_QUERIES_PER_HOUR count | MAX_UPDATES_PER_HOUR count | MAX_CONNECTIONS_PER_HOUR count | MAX_USER_CONNECTIONS count示例:
GRANT SELECT (col1), INSERT (col1,col2) ON mydb.mytbl TO 'someuser'@'somehost'; - 回收授权:REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level FROM user [, user] ...
示例:
REVOKE DELETE ON testdb.* FROM 'testuser'@'%' - 查看指定用户获得的授权:
Help SHOW GRANTS
SHOW GRANTS FOR 'user'@'host';
SHOW GRANTS FOR CURRENT_USER[()]; - 注意:MariaDB服务进程启动时会读取mysql库中所有授权表至内存
(1) GRANT或REVOKE等执行权限操作会保存于系统表中,MariaDB的服务进程通常会自动重读授权表,使之生效
(2) 对于不能够或不能及时重读授权表的命令,可手动让MariaDB的服务进程重读授权表:mysql> FLUSH PRIVILEGES
注意:
grant all on *.* to test@'192.168.32.129'; 授权test用户可以查询所有数据库中的所有表
在192.168.32.129主机上测试,发现并不能查看所有数据库,这时需要退出重新登录才能具有该权限,这是因为被授权用户在线时不能获取到权限,因此需要重新登录
撤销权限时也需要被撤销权限用户重新登陆数据库才能生效 6、MySQL架构
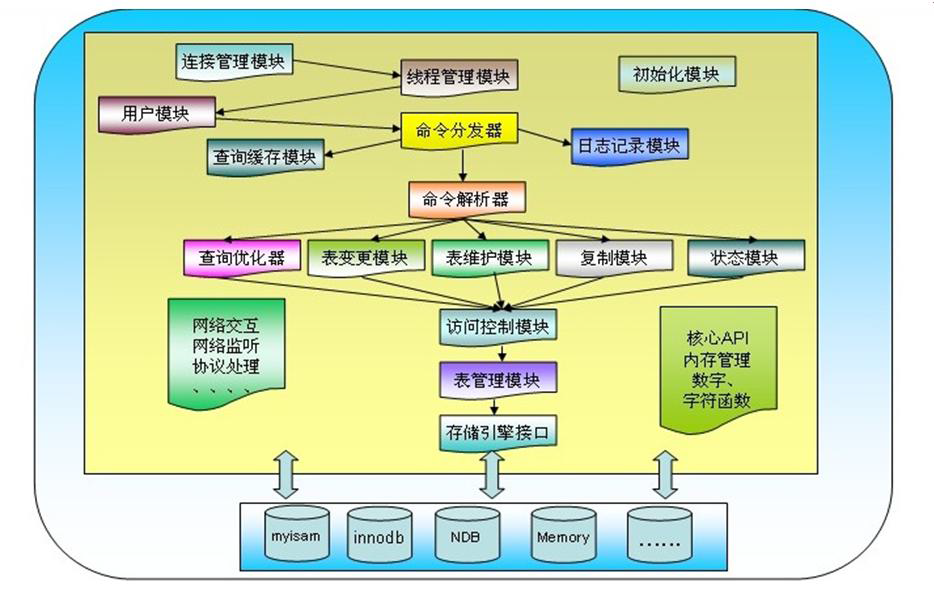
术语解释:
事务:多个操作的完整集合,这几个操作必须作为一个整体出现,一次性全部做完,myisam不支持此特性
加锁:当对数据库中的表操作时,对该表或表中的内容进行加锁,防止多个人同时操作,会影响数据库的并发性,myisam支持表级锁(更改表时,对整个表加锁),innodb支持行级锁(更改表时,只对某一行加锁),innodb并发性更高,更加灵活
MVCC 多版本并发控制机制
多个事务对某个表同时进行操作时如t1事务进行写操作,t2事务进行查询操作,此时写操作尚未完成,操作过程中形成的数据我们称之为脏数据,为了防止t2事务查看到脏数据,我们可以使用表锁进行控制,但这样一来就需要等待写操作完成后才能进行查询,这样一来就降低了效率。mvcc机制是当t2事务查询表时,查询到的表的状态为写操作之前的表状态,即查看的是表的某一时间点的一个快照。这样就形成了多个版本的并存,如果有更多事务同时进行读操作,也就形成了多版本的并发控制
select查到记录的insert事务编号比当前事务编号要小(早),delete事务编号比当前事务编号要大(晚)
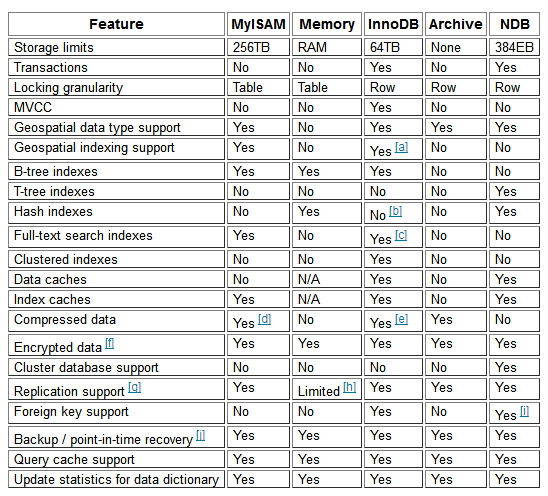
mysisam使用场景:速度快,存放不重要的数据,并发性差7、存储引擎
存储引擎
-
MyISAM引擎特点:
不支持事务
表级锁定
读写相互阻塞,写入不能读,读时不能写
只缓存索引
不支持外键约束
不支持聚簇索引
读取数据较快,占用资源较少
不支持MVCC(多版本并发控制机制)高并发
崩溃恢复性较差
MySQL5.5.5前默认的数据库引擎 -
MyISAM存储引擎适用场景
只读(或者写较少)、表较小(可以接受长时间进行修复操作) -
MyISAM引擎文件
tbl_name.frm 表格式定义
tbl_name.MYD 数据文件
tbl_name.MYI 索引文件 -
InnoDB引擎特点
行级锁
支持事务,适合处理大量短期事务
读写阻塞与事务隔离级别相关
可缓存数据和索引
支持聚簇索引
崩溃恢复性更好
支持MVCC高并发
从MySQL5.5后支持全文索引
从MySQL5.5.5开始为默认的数据库引擎 -
InnoDB数据库文件
所有InnoDB表的数据和索引放置于同一个表空间中
表空间文件:datadir定义的目录下
数据文件:ibddata1, ibddata2, ...
每个表单独使用一个表空间存储表的数据和索引
启用:innodb_file_per_table=ON
参看:https://mariadb.com/kb/en/library/xtradbinnodb-server-system-variables/#innodb_file_per_table
ON (>= MariaDB 5.5)
两类文件放在数据库独立目录中
数据文件(存储数据和索引):tb_name.ibd
表格式定义:tb_name.frm
其他存储引擎
- Performance_Schema:Performance_Schema数据库
- Memory :将所有数据存储在RAM中,以便在需要快速查找参考和其他类似数据的环境中进行快速访问。适用存放临时数据。引擎以前被称为HEAP引擎
- MRG_MyISAM:使MySQL DBA或开发人员能够对一系列相同的MyISAM表进行逻辑分组,并将它们作为一个对象引用。适用于VLDB(Very Large Data Base)环境,如数据仓库
- Archive :为存储和检索大量很少参考的存档或安全审核信息,只支持SELECT和INSERT操作;支持行级锁和专用缓存区
- Federated联合:用于访问其它远程MySQL服务器一个代理,它通过创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,而后完成数据存取,提供链接单独MySQL服务器的能力,以便从多个物理服务器创建一个逻辑数据库。非常适合分布式或数据集市环境
其他数据库引擎
- BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性
- Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性
- CSV:CSV存储引擎使用逗号分隔值格式将数据存储在文本文件中。可以使用CSV引擎以CSV格式导入和导出其他软件和应用程序之间的数据交换
- BLACKHOLE :黑洞存储引擎接受但不存储数据,检索总是返回一个空集。该功能可用于分布式数据库设计,数据自动复制,但不是本地存储
- example:“stub”引擎,它什么都不做。可以使用此引擎创建表,但不能将数据存储在其中或从中检索。目的是作为例子来说明如何开始编写新的存储引擎
其他存储引擎
- MariaDB支持的其它存储引擎:
OQGraph
SphinxSE
TokuDB
Cassandra
CONNECT
SQUENCE
管理存储引擎
- 查看mysql支持的存储引擎:
show engines; - 查看当前默认的存储引擎:
show variables like '%storage_engine%'; - 设置默认的存储引擎:
vim /etc/my.conf [mysqld] default_storage_engine= InnoDB; innodb_file_per_table=on 数据分开存放,便于管理,如果不加此项,5.5之前版本数据会集中存放,不利于管理 - 查看库中所有表使用的存储引擎
show table status from db_name; - 查看库中指定表的存储引擎
show table status like ' tb_name ';
show create table tb_name; - 设置表的存储引擎:
CREATE TABLE tb_name(... ) ENGINE=InnoDB;
ALTER TABLE tb_name ENGINE=InnoDB;
MySQL中的系统数据库
- mysql数据库
是mysql的核心数据库,类似于Sql Server中的master库,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息 - performance_schema数据库
MySQL 5.5开始新增的数据库,主要用于收集数据库服务器性能参数,库里表的存储引擎均为PERFORMANCE_SCHEMA,用户不能创建存储引擎为PERFORMANCE_SCHEMA的表 - information_schema数据库
MySQL 5.0之后产生的,一个虚拟数据库,物理上并不存在information_schema数据库类似与“数据字典”,提供了访问数据库元数据的方式,即数据的数据。比如数据库名或表名,列类型,访问权限(更加细化的访问方式)
8、服务器选项,系统和状态变量
服务器配置
- mysqld选项,服务器系统变量和服务器状态变量
https://dev.mysql.com/doc/refman/5.7/en/mysqld-option-tables.html
https://mariadb.com/kb/en/library/full-list-of-mariadb-options-system-and-status-variables/ - 注意:其中有些参数支持运行时修改,会立即生效;有些参数不支持,且只能通过修改配置文件,并重启服务器程序生效;有些参数作用域是全局的,且不可改变;有些可以为每个用户提供单独(会话)的设置
- 获取mysqld的可用选项列表:
mysqld --help –verbose
mysqld --print-defaults 获取默认设置 - 服务器系统变量:分全局和会话两种
- 服务器状态变量:分全局和会话两种
- 获取运行中的mysql进程使用各服务器参数及其值
mysql> SHOW GLOBAL VARIABLES;
mysql> SHOW [SESSION] VARIABLES; - 设置服务器选项方法:
在命令行中设置:
shell> ./mysqld_safe –-skip-name-resolve=1;
在配置文件my.cnf中设置:
skip_name_resolve=1;
服务器端设置
- 修改服务器变量的值:
mysql> help SET - 修改全局变量:仅对修改后新创建的会话有效;对已经建立的会话无效
mysql> SET GLOBAL system_var_name=value;
mysql> SET @@global.system_var_name=value; - 修改会话变量:
mysql> SET [SESSION] system_var_name=value;
mysql> SET @@[session.]system_var_name=value; - 状态变量(只读):用于保存mysqld运行中的统计数据的变量,不可更改
mysql> SHOW GLOBAL STATUS;
mysql> SHOW [SESSION] STATUS;
示例:
set global character_set_results=gb2312 更改全局变量,对全部用户有效
show global variables like '%char%'; 查看全局变量
set character_set_results=gb2312 更改会话变量,只对当前会话有效
show variables like '%char%'; 查看会话变量
注意:会话级别变量优先级高于全局级别变量,而且一旦重启服务变量设置会恢复默认服务器选项和服务器变量的区别:
服务器选项:可以加入配置文件中/etc/my.cnf,以-作为分隔符,重启服务才能生效
mysqld --verbose --help 查看服务器选项列表
服务器变量:不支持加入配置文件,以_作为分隔符,如果支持动态dynamic,则可以不重启服务生效,使用set命令设置,查询命令show variables like ' '服务器变量SQL_MODE
- SQL_MODE:对其设置可以完成一些约束检查的工作,可分别进行全局的设置或当前会话的设置,参看:https://mariadb.com/kb/en/library/sql-mode/
- 常见MODE:
NO_AUTO_CREATE_USER
禁止GRANT创建密码为空的用户
NO_ZERO_DATE
在严格模式,不允许使用‘0000-00-00’的时间
ONLY_FULL_GROUP_BY
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么将认为这个SQL是不合法的
NO_BACKSLASH_ESCAPES
反斜杠“\”作为普通字符而非转义字符
PIPES_AS_CONCAT
将"||"视为连接操作符而非“或运算符”
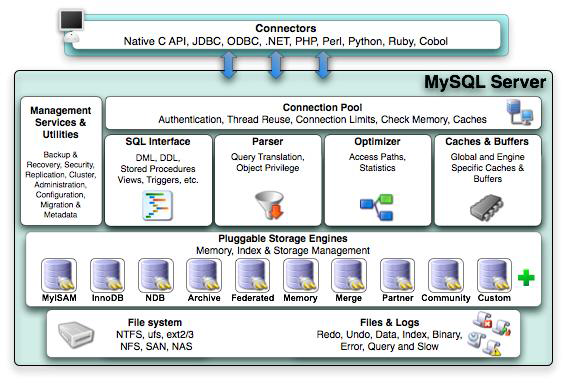
mysql架构
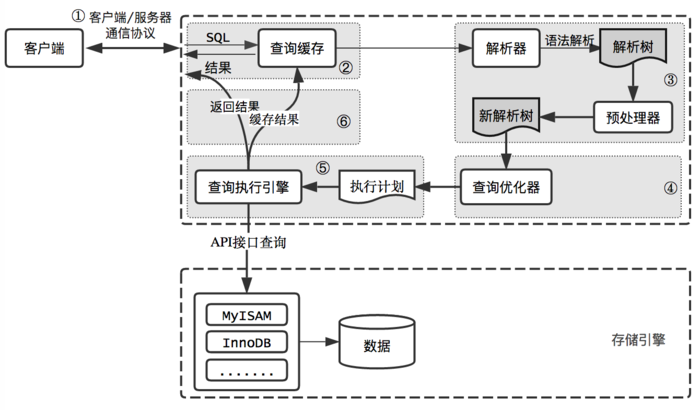
查询的执行路径
知识扩展:
查看状态变量
show status like '';
show status like '%select%';
MariaDB [hellodb]> show status like '%select%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| Com_insert_select | 0 |
| Com_replace_select | 0 |
| Com_select | 2 |
| Select_full_join | 0 |
| Select_full_range_join | 0 |
| Select_range | 0 |
| Select_range_check | 0 |
| Select_scan | 8 |
+------------------------+-------+
其中的com_select对应的值为当前用户select查询次数
MariaDB [hellodb]> show status like '%insert%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| Com_insert | 0 |
| Com_insert_select | 0 |
| Delayed_insert_threads | 0 |
| Innodb_ibuf_discarded_inserts | 0 |
| Innodb_ibuf_merged_inserts | 0 |
| Innodb_rows_inserted | 0 |
| Qcache_inserts | 0 |
+-------------------------------+-------+
其中的com_insert对应的值为当前用户insert插入数据次数
查看当前用户连接数
MariaDB [hellodb]> show variables like '%connect%';
+--------------------------+-----------------+
| Variable_name | Value |
+--------------------------+-----------------+
| character_set_connection | utf8 |
| collation_connection | utf8_general_ci |
| connect_timeout | 10 |
| extra_max_connections | 1 |
| init_connect | |
| max_connect_errors | 10 |
| max_connections | 151 |
| max_user_connections | 0 |
+--------------------------+-----------------+
其中max_connections为当前数据库最大连接数为151
调整最大连接数:查看该变量是否也是服务器选项,是否能够写入配置文件
去官方网站查询https://dev.mysql.com/doc/refman/5.7/en/mysqld-option-tables.html,发现既是选项又是变量
如果使用set命令更改只是临时更改,重启服务就会失效
set global max_connections = 1000 只支持global
永久更改需要写入配置文件
vim /etc/my.cnf
global max_connections = 1000
查看当前有多少用户正在连接
MariaDB [hellodb]> show status like 'threads%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 0 |
| Threads_connected | 1 |
| Threads_created | 2 |
| Threads_running | 1 |
+-------------------+-------+
4 rows in set (0.00 sec)
Threads_connected表示连接数据库的线程数为1
Threads_connected表示连接数据库且正在工作的线程数为1
skip_name_resolve 是否支持反向解析ip地址
OFF 不忽略名字解析
ON 忽略名字解析
show variables like 'skip_name_resolve'; 查看该选项的设置
默认情况下为OFF,即不忽略名字解析,会尝试把ip地址解析为名字,可能会导致连接数据库失败,如做集群时会用到该选项
该选项不支持动态更改,为global级别变量
vim /etc/my.cnf
skip_name_resolve=ON 设置为忽略名字解析
重启数据库服务
skip_networking 进入维护模式9、优化查询和索引管理
查询缓存
- 查询缓存( Query Cache )原理
缓存SELECT操作或预处理查询的结果集和SQL语句,当有新的SELECT语句或预处理查询语句请求,先去查询缓存,判断是否存在可用的记录集,判断标准:与缓存的SQL语句,是否完全一样,区分大小写 - 优缺点
不需要对SQL语句做任何解析和执行,当然语法解析必须通过在先,直接从Query Cache中获得查询结果,提高查询性能
查询缓存的判断规则,不够智能,也即提高了查询缓存的使用门槛,降低其效率;
查询缓存的使用,会增加检查和清理Query Cache中记录集的开销 - 哪些查询可能不会被缓存
查询语句中加了SQL_NO_CACHE参数
查询语句中含有获得值的函数,包含自定义函数,如:NOW()
CURDATE()、GET_LOCK()、RAND()、CONVERT_TZ()等
对系统数据库的查询:mysql、information_schema 查询语句中使用SESSION级别变量或存储过程中的局部变量
查询语句中使用了LOCK IN SHARE MODE、FOR UPDATE的语句,查询语句中类似SELECT …INTO 导出数据的语句
对临时表的查询操作;存在警告信息的查询语句;不涉及任何表或视图的查询语句;某用户只有列级别权限的查询语句
事务隔离级别为Serializable时,所有查询语句都不能缓存 - 查询缓存相关的服务器变量
query_cache_min_res_unit:查询缓存中内存块的最小分配单位,默认4k,较小值会减少浪费,但会导致更频繁的内存分配操作,较大值会带来浪费,会导致碎片过多,内存不足
query_cache_limit:单个查询结果能缓存的最大值,默认为1M,对于查询结果过大而无法缓存的语句,建议使用SQL_NO_CACHE
query_cache_size:查询缓存总共可用的内存空间;单位字节,必须是1024的整数倍,最小值40KB,低于此值有警报
query_cache_wlock_invalidate:如果某表被其它的会话锁定,是否仍然可以从查询缓存中返回结果,默认值为OFF,表示可以在表被其它会话锁定的场景中继续从缓存返回数据;ON则表示不允许
query_cache_type:是否开启缓存功能,取值为ON, OFF, DEMAND
示例:
MariaDB [hellodb]> show variables like '%query_cache%';
+------------------------------+---------+
| Variable_name | Value |
+------------------------------+---------+
| have_query_cache | YES |
| query_cache_limit | 1048576 | 单个查询结果能缓存的最大值,即缓存中查询结果能分配到的空间最大值
| query_cache_min_res_unit | 4096 | 缓存中内存块的最小分配单位:4K
| query_cache_size | 0 | 查询缓存总共可用的内存空间
| query_cache_strip_comments | OFF |
| query_cache_type | ON | 是否开启缓存功能
| query_cache_wlock_invalidate | OFF | 如果表被锁定,其他yoghurt是否可以从查询缓存中返回结果
+------------------------------+---------+
set global query_cache_size=10485760 更改缓存可用的内存空间为10M
vim /etc/my.cnf 在配置文件中更改此选项
set global query_cache_size=10M - SELECT语句的缓存控制
SQL_CACHE:显式指定存储查询结果于缓存之中
SQL_NO_CACHE:显式查询结果不予缓存 - query_cache_type参数变量
query_cache_type的值为OFF或0时,查询缓存功能关闭
query_cache_type的值为ON或1时,查询缓存功能打开,SELECT的结果符合缓存条件即会缓存,否则,不予缓存,显式指定SQL_NO_CACHE,不予缓存,此为默认值
query_cache_type的值为DEMAND或2时,查询缓存功能按需进行,显式指定SQL_CACHE的SELECT语句才会缓存;其它均不予缓存
参看:https://mariadb.com/kb/en/library/server-system-variables/#query_cache_type
https://dev.mysql.com/doc/refman/5.7/en/query-cache-configuration.html - 查询缓存相关的状态变量:SHOW GLOBAL STATUS LIKE ‘Qcache%';
Qcache_free_blocks:处于空闲状态 Query Cache中内存 Block 数
Qcache_total_blocks:Query Cache 中总Block ,当Qcache_free_blocks相对此值较大时,可能用内存碎片,执行FLUSH QUERY CACHE清理碎片
Qcache_free_memory:处于空闲状态的 Query Cache 内存总量
Qcache_hits:Query Cache 命中次数
Qcache_inserts:向 Query Cache 中插入新的 Query Cache 的次数,即没有命中的次数
Qcache_lowmem_prunes:记录有多少条查询因为内存不足而被移除出查询缓存
Qcache_not_cached:没有被 Cache 的 SQL 数,包括无法被 Cache 的 SQL 以及由于 query_cache_type 设置的不会被 Cache 的 SQL语句
Qcache_queries_in_cache:在 Query Cache 中的 SQL 数量
示例:
MariaDB [hellodb]> show status like 'qcache%';
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 10222536 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 0 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 1 |
+-------------------------+----------+命中率和内存使用率估算
- 查询缓存中内存块的最小分配单位
query_cache_min_res_unit :(query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache - 查询缓存命中率
Qcache_hits / ( Qcache_hits + Qcache_inserts ) * 100% - 查询缓存内存使用率
(query_cache_size – qcache_free_memory) / query_cache_size * 100%
InnoDB存储引擎
- InnoDB存储引擎的缓冲池:
通常InnoDB存储引擎缓冲池的命中不应该小于99% - 查看相关状态变量:
show global status like 'innodb%read%';
Innodb_buffer_pool_reads: 表示从物理磁盘读取页的次数
Innodb_buffer_pool_read_ahead: 预读的次数
Innodb_buffer_pool_read_ahead_evicted: 预读页,但是没有读取就从缓冲池中被替换的页数量,一般用来判断预读的效率
Innodb_buffer_pool_read_requests: 从缓冲池中读取页次数
Innodb_data_read: 总共读入的字节数
Innodb_data_reads: 发起读取请求的次数,每次读取可能需要读取多个页
索引
- 索引是特殊数据结构:定义在查找时作为查找条件的字段
- 索引实现在存储引擎
- 优点:
索引可以降低服务需要扫描的数据量,减少了IO次数
索引可以帮助服务器避免排序和使用临时表
索引可以帮助将随机I/O转为顺序I/O - 缺点:
占用额外空间,影响插入速度 - 索引类型:
B+ TREE、HASH、R TREE
聚簇(集)索引、非聚簇索引:数据和索引是否存储在一起
主键索引、二级(辅助)索引
稠密索引、稀疏索引:是否索引了每一个数据项
简单索引、组合索引
左前缀索引:取前面的字符做索引
覆盖索引:从索引中即可取出要查询的数据,性能高
B-TREE索引
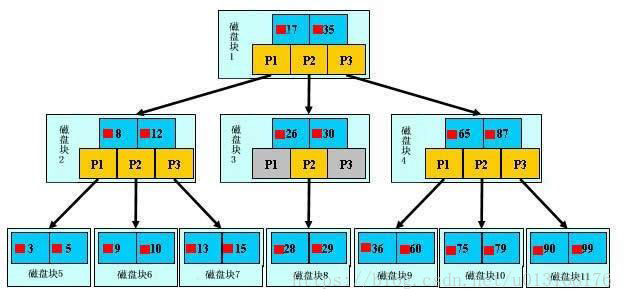
B+TREE索引
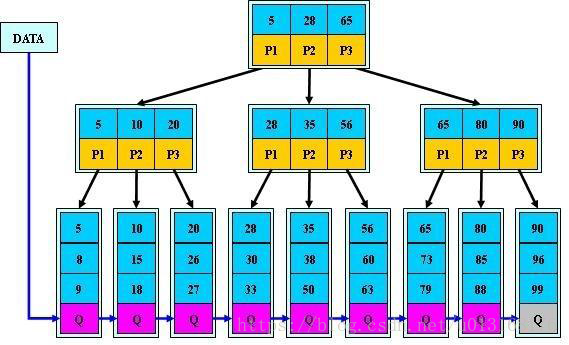
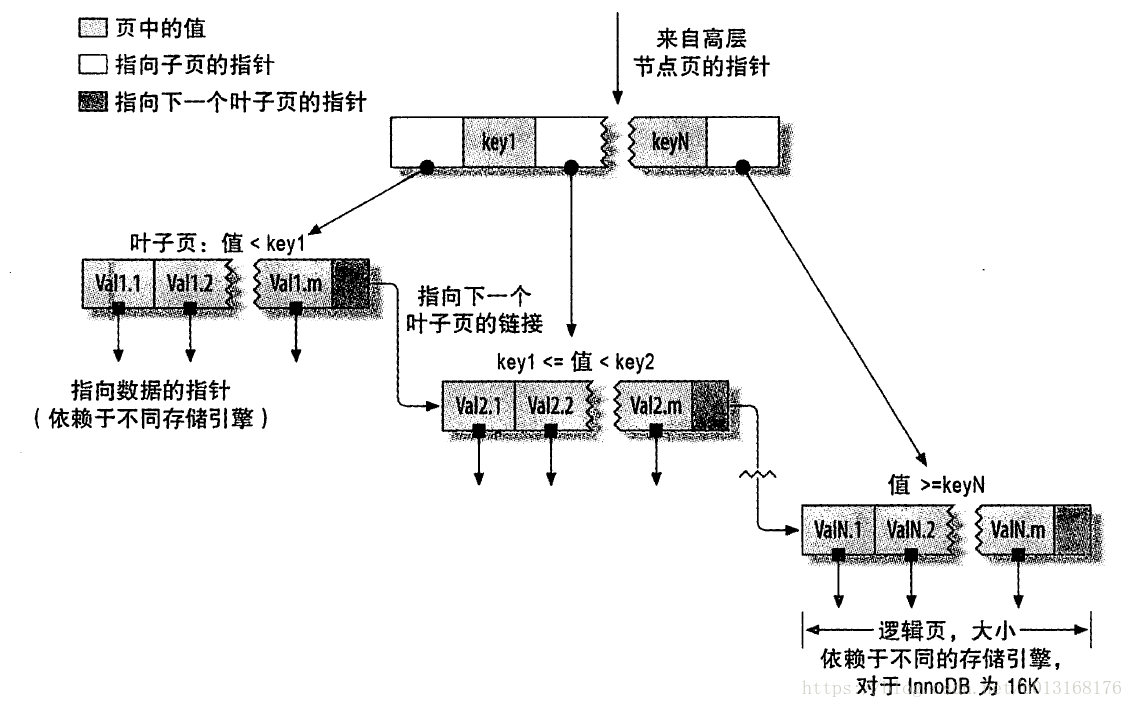
- B+Tree索引:顺序存储,每一个叶子节点到根结点的距离是相同的;左前缀索引,适合查询范围类的数据
- 可以使用B+Tree索引的查询类型:
全值匹配:精确所有索引列,如:姓wang,名xiaochun,年龄30
匹配最左前缀:即只使用索引的第一列,如:姓wang
匹配列前缀:只匹配一列值开头部分,如:姓以w开头的
匹配范围值:如:姓ma和姓wang之间
精确匹配某一列并范围匹配另一列:如:姓wang,名以x开头的
只访问索引的查询 - B+Tree索引的限制:
如不从最左列开始,则无法使用索引,如:查找名为xiaochun,或姓为g结尾
不能跳过索引中的列:如:查找姓wang,年龄30的,只能使用索引第一列
如果查询中某个列是为范围查询,那么其右侧的列都无法再使用索引:如:姓wang,名x%,年龄30,只能利用姓和名上面的索引 - 特别提示:
索引列的顺序和查询语句的写法应相匹配,才能更好的利用索引
为优化性能,可能需要针对相同的列但顺序不同创建不同的索引来满足不同类型的查询需求
B-TREE和B+TREE的区别:
B-TREE B树 每个节点最多3个分支,每个节点都存放数据,占用空间较大,不支持范围查询(查询效率很低)
B+TREE B+树 根节点和分支节点不存放数据,只存放索引,数据存放在叶子节点,叶子节点之间有链表关系,知道下一个叶子节点的位置,适合范围查询Hash索引
- Hash索引:基于哈希表实现,只有精确匹配索引中的所有列的查询才有效,索引自身只存储索引列对应的哈希值和数据指针,索引结构紧凑,查询性能好
- Memory存储引擎支持显式hash索引,InnoDB和MyISAM存储引擎不支持
- 适用场景:只支持等值比较查询,包括=, <=>, IN()
- 不适合使用hash索引的场景
不适用于顺序查询:索引存储顺序的不是值的顺序
不支持模糊匹配
不支持范围查询
不支持部分索引列匹配查找:如A,B列索引,只查询A列索引无效
其他索引
- 地理空间索引( Geospatial indexing ):
MyISAM支持地理空间索引,可以使用任意维度组合查询,使用特有的函数访问,常用于做地理数据存储,使用不多
InnoDB从MySQL5.7之后也开始支持 - 全文索引(FULLTEXT):
在文本中查找关键词,而不是直接比较索引中的值,类似搜索引擎
InnoDB从MySQL 5.6之后也开始支持
聚簇索引和非聚簇索引
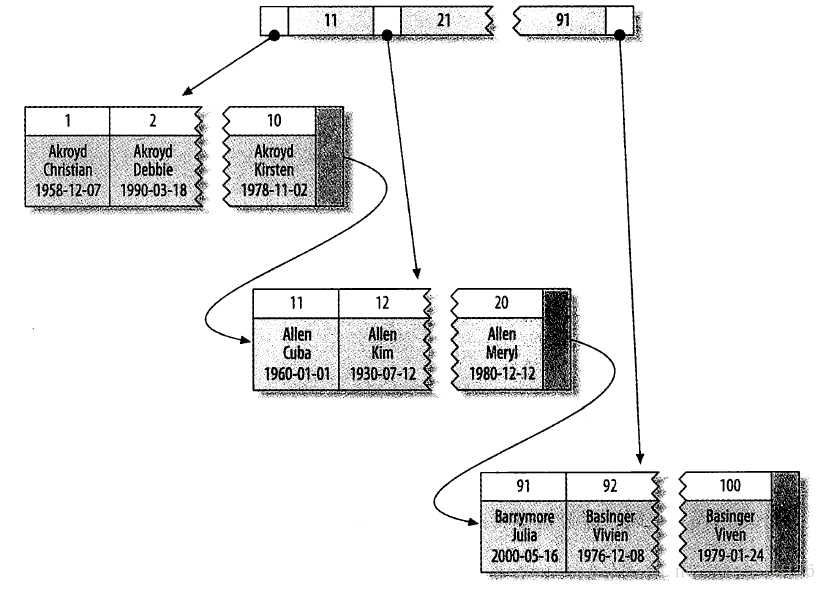
聚簇索引和非聚簇索引,主键和二级索引
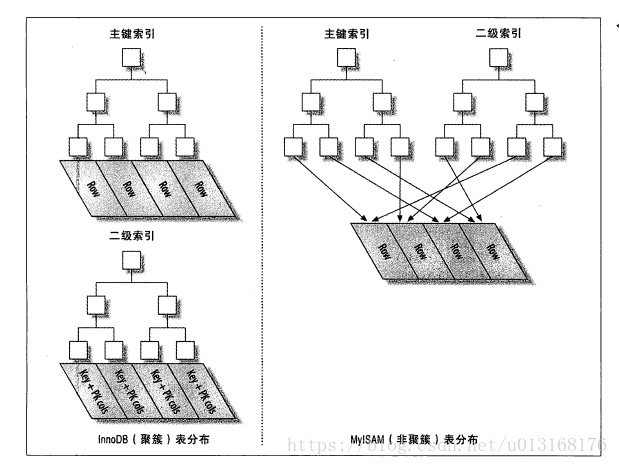
其他索引
- 冗余和重复索引:
冗余索引:(A),(A,B)
重复索引:已经有索引,再次建立索引 - 索引优化策略:
独立地使用列:尽量避免其参与运算,独立的列指索引列不能是表达式的一部分,也不能是函数的参数,在where条件中,始终将索引列单独放在比较符号的一侧
左前缀索引:构建指定索引字段的左侧的字符数,要通过索引选择性来评估左前缀索引:如果某字段长度很长,可以限定其中左起多少个字符作为索引,如name字段有50个字符长度,如果用其中20个字符不会出现重复,那么就可以用前20个字符作为索引 注意:限定的长度的字符不能重复,如wang1,wang2,wang3 ,不能用wang作为索引索引选择性:不重复的索引值和数据表的记录总数的比值
多列索引:AND操作时更适合使用多列索引,而非为每个列创建单独的索引
选择合适的索引列顺序:无排序和分组时,将选择性最高放左侧
索引优化建议
- 只要列中含有NULL值,就最好不要在此例设置索引,复合索引如果有NULL值,此列在使用时也不会使用索引
- 尽量使用短索引,如果可以,应该制定一个前缀长度
- 对于经常在where子句使用的列,最好设置索引
- 对于有多个列where或者order by子句,应该建立复合索引
- 对于like语句,以%或者‘-’开头的不会使用索引,以%结尾会使用索引
- 尽量不要在列上进行运算(函数操作和表达式操作)
- 尽量不要使用not in和<>操作
SQL语句性能优化
- 查询时,能不要就不用,尽量写全字段名
- 大部分情况连接效率远大于子查询
- 多表连接时,尽量小表驱动大表,即小表 join 大表
- 在有大量记录的表分页时使用limit
- 对于经常使用的查询,可以开启缓存
- 多使用explain和profile分析查询语句
- 查看慢查询日志,找出执行时间长的sql语句优化
管理索引
- 创建索引:
CREATE INDEX index_name ON tbl_name (index_col_name,...);
help CREATE INDEX使用alter命令添加索引 alter table students add index idx_age(age); 创建惟一键索引 create unique index uni_idx_name on students(name); - 删除索引:
DROP INDEX index_name ON tbl_name;使用alter命令删除惟一键索引 alter table students drop key uni_idx_name; - 查看索引:
SHOW INDEXES FROM [db_name.]tbl_name; - 优化表空间:
OPTIMIZE TABLE tb_name - 查看索引的使用
SET GLOBAL userstat=1;
SHOW INDEX_STATISTICS
EXPLAIN
- 通过EXPLAIN来分析索引的有效性:
- EXPLAIN SELECT clause
获取查询执行计划信息,用来查看查询优化器如何执行查询
示例:
创建索引
create index index_name on students(name);
查看查询数据是否利用索引
MariaDB [hellodb]> explain select * from students where age=10;
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | students | ALL | NULL | NULL | NULL | NULL | 25 | Using where |
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
没有使用索引查询
MariaDB [hellodb]> explain select * from students where name like 'ren%';
+------+-------------+----------+-------+---------------+------------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+-------+---------------+------------+---------+------+------+-----------------------+
| 1 | SIMPLE | students | range | index_name | index_name | 152 | NULL | 1 | Using index condition |
+------+-------------+----------+-------+---------------+------------+---------+------+------+-----------------------+
使用索引查询- 输出信息说明:
参考 https://dev.mysql.com/doc/refman/5.7/en/explain-output.html - id: 当前查询语句中,每个SELECT语句的编号
复杂类型的查询有三种:
简单子查询
用于FROM中的子查询
联合查询:UNION
注意:UNION查询的分析结果会出现一个额外匿名临时表
示例:
使用复杂查询语句,有多个子句的id号
MariaDB [hellodb]> explain select stuid,name from students union select tid,name from teachers;
+------+--------------+------------+-------+---------------+--------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+--------------+------------+-------+---------------+--------------+---------+------+------+-------------+
| 1 | PRIMARY | students | index | NULL | idx_name_age | 153 | NULL | 25 | Using index |
| 2 | UNION | teachers | ALL | NULL | NULL | NULL | NULL | 4 | |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | |
+------+--------------+------------+-------+---------------+--------------+---------+------+------+-------------+- select_type:
简单查询为SIMPLE
复杂查询:
SUBQUERY: 简单子查询
PRIMARY:最外面的SELECT
DERIVED: 用于FROM中的子查询
UNION:UNION语句的第一个之后的SELECT语句
UNION RESULT: 匿名临时表
示例:
子查询subquery
MariaDB [hellodb]> explain select name,age from students where age > (select avg(age) from students);
+------+-------------+----------+-------+---------------+--------------+---------+------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+-------+---------------+--------------+---------+------+------+--------------------------+
| 1 | PRIMARY | students | index | index_age | idx_name_age | 153 | NULL | 25 | Using where; Using index |
| 2 | SUBQUERY | students | index | NULL | index_age | 1 | NULL | 25 | Using index |
+------+-------------+----------+-------+---------------+--------------+---------+------+------+--------------------------+
DERIVED: 用于FROM中的子查询
centos7系统想要在explain查询字段中看到derived字段,需要进行相关设置才能显示出来
set optimizer_switch='derived_merge=off';
MariaDB [hellodb]> explain select a.name,a.age from (select * from students) as a;
+------+-------------+------------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+------------+------+---------------+------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 25 | |
| 2 | DERIVED | students | ALL | NULL | NULL | NULL | NULL | 25 | |
+------+-------------+------------+------+---------------+------+---------+------+------+-------+
const:返回单个行
MariaDB [hellodb]> explain select * from students where stuid = 5;
+------+-------------+----------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | students | const | PRIMARY | PRIMARY | 4 | const | 1 | |
+------+-------------+----------+-------+---------------+---------+---------+-------+------+-------+- table:SELECT语句关联到的表
- type:关联类型或访问类型,即MySQL决定的如何去查询表中的行的方式,以下顺序,性能从低到高
ALL: 全表扫描
index:根据索引的次序进行全表扫描;如果在Extra列出现“Using index”表示了使用覆盖索引,而非全表扫描
range:有范围限制的根据索引实现范围扫描;扫描位置始于索引中的某一点,结束于另一点
ref: 根据索引返回表中匹配某单个值的所有行
eq_ref:仅返回一个行,但与需要额外与某个参考值做比较
const, system: 直接返回单个行 - possible_keys:查询可能会用到的索引
- key: 查询中使用到的索引
- key_len: 在索引使用的字节数
- ref: 在利用key字段所表示的索引完成查询时所用的列或某常量值
- rows:MySQL估计为找所有的目标行而需要读取的行数
- Extra:额外信息
Using index:MySQL将会使用覆盖索引,以避免访问表
Using where:MySQL服务器将在存储引擎检索后,再进行一次过滤
Using temporary:MySQL对结果排序时会使用临时表
Using filesort:对结果使用一个外部索引排序
10、锁和事务管理
并发控制
- 锁粒度:
表级锁
行级锁 - 锁:
读锁:共享锁,只读不可写,多个读互不阻塞
写锁:独占锁,排它锁,一个写锁会阻塞其它读和它锁 - 实现
存储引擎:自行实现其锁策略和锁粒度
服务器级:实现了锁,表级锁;用户可显式请求 - 分类:
隐式锁:由存储引擎自动施加锁
显式锁:用户手动请求
示例:
lock tables teachers read; 对teachers表加读锁
加读锁后,其他终端只能读该表,不能写
lock tables students write; 加写锁
加写锁后,自己可读可写,别人不可读不可写
注意:加锁时,要重启服务或清除缓存,否则加锁可能无效
启用缓存的情况下,可以通过修改变量,使缓存不生效
query_cache_wlock_invalidate 启用该项表示不允许从缓存中返回数据
此变量为会话级,要想全局生效则需要更改配置文件
set query_cache_wlock_invalidate=on
更改配置文件
vim /etc/my.cnf
[mysqld]
query_cache_wlock_invalidate=on- 锁策略:在锁粒度及数据安全性寻求的平衡机制
- 显示使用锁
LOCK TABLES
tbl_name [[AS] alias] lock_type
[, tbl_name [[AS] alias] lock_type] ...
lock_type: READ , WRITE
UNLOCK TABLES 解锁
FLUSH TABLES [tb_name[,...]] [WITH READ LOCK]
关闭正在打开的表(清除查询缓存),通常在备份前加全局读锁对服务器全部数据库加锁,即不仅对当前数据库生效,对其他数据库也生效 还可以清除查询缓存信息,即flush tables 其他表全部关闭后,才能使用此命令加锁 flush tables with read lock; 对所有数据库的所有表加读锁(只能读不能写),无需写表名 unlock tabls 解锁SELECT clause [FOR UPDATE | LOCK IN SHARE MODE]
查询时加写或读锁
事务
- 事务Transactions:一组原子性的SQL语句,或一个独立工作单元
- 事务日志:记录事务信息,实现undo,redo等故障恢复功能
存放完整的事务操作和不完整的事务操作 系统根据事务日志决定是否继续执行事务操作(事务动作已经全部写入事务日志)和撤销事务操作(事务动作没有完全写入事务日志) myisam存储引擎不支持事务日志,因此该存储引擎恢复能力差 - ACID特性:
A:atomicity原子性;整个事务中的所有操作要么全部成功执行,要么全部失败后回滚
C:consistency一致性;数据库总是从一个一致性状态转换为另一个一致性状态
如:账户转账,转账人转走1万元,收账人收到1万元,两个动作要么都做,要么都不做,即两个动作要保持一致,确保数据保持一致
I:Isolation隔离性;一个事务所做出的操作在提交之前,是不能为其它事务所见;隔离有多种隔离级别,实现并发
D:durability持久性;一旦事务提交,其所做的修改会永久保存于数据库中 - 启动事务:
BEGIN
BEGIN WORK
START TRANSACTION - 结束事务:
COMMIT:提交
ROLLBACK: 回滚
注意:只有事务型存储引擎中的DML语句方能支持此类操作 - 自动提交:set autocommit={1|0} 默认为1,为0时设为非自动提交
建议:显式请求和提交事务,而不要使用“自动提交”功能 - 事务支持保存点:savepoint
SAVEPOINT identifier
ROLLBACK [WORK] TO [SAVEPOINT] identifier
RELEASE SAVEPOINT identifier
示例:
update students set classid=5 where stuid=23; 对学生表进行更改
savepoint sp23 创建保存点
update students set classid=10 where stuid=24; 对学生表进行更改
savepoint sp24 创建保存点
update students set classid=30 where stuid=25; 对学生表进行更改
rollback to savepoint sp24; 回滚到sp24保存点,即stuid=25的操作会被撤销
rollback to savepoint sp23; 回滚到sp23保存点,即stuid=24的操作会被撤销事务隔离级别
- 事务隔离级别:从上至下更加严格
READ UNCOMMITTED 可读取到未提交数据,产生脏读两个会话:会话1和会话2 会话1开启事务写入数据,会话2同样开启事务,在该事务内可以读取到会话1未提交的数据READ COMMITTED 可读取到提交数据,读取不到未提交数据。即在数据提交之前读取到的数据为写数据之前的旧数据,在数据提交之后读取到的数据为提交后更改的新数据,这样就读取到多个提交数据,导致每次读取数据不一致,也就是不可重复读
两个会话:会话1和会话2 会话1开启事务写入数据,会话2同样开启事务,在该事务内可以读取到会话1未提交前的旧数据 会话1提交数据完成事务,会话2开启事务,在该事务内可以读取到会话1提交后的新数据REPEATABLE READ 可重复读,多次读取数据都一致,产生幻读,即读取过程中,即使有其它提交的事务修改数据,也只能读取到未修改前的旧数据,等其他事务提交完毕以后读取的数据也是提交前的旧数据。该选项为MySQL默认设置。
两个会话:会话1和会话2 会话1开启事务写入数据,会话2同样开启事务,在该事务内容读取到会话1未提交前的旧数据 会话1提交数据完成事务,会话2开启事务,在该事务内读取到的还是会话1提交前的旧数据,当会话2提交数据完成事务后,才能看到会话1提交的新数据SERIALIZABILE 可串行化,未提交的读事务阻塞修改事务,或者未提交的修改事务阻塞读事务。导致并发性能差
两个会话:会话1和会话2 会话1开启事务读取数据,会话2开启事务,在该事务内可以读取数据,但无法写入数据,只有等会话1完成事务,会话2才可以写入数据 会话1开启事务写入数据,会话2开启事务,在该事务内无法读取数据,也无法写入数据,只有等会话1完成事务,会话2才可以读或写数据 会话2会一直等待,直至会话超时会话超时的相关变量:
MariaDB [hellodb]> show variables like '%timeout%'; 其中,innodb_lock_wait_timeout是指等待超时时间,默认为50秒,该变量可以手动更改超时时间 - MVCC: 多版本并发控制,和事务级别相关
| 事务隔离级别 | 脏读可能性 | 不可重复读可能性 | 幻读可能性 | 加锁读 |
|---|---|---|---|---|
| 读未提交(read-uncommited) | 是 | 是 | 是 | 否 |
| 不可重复读(read-commited) | 否 | 是 | 是 | 否 |
| 可重复读(repeatable-read) | 否 | 否 | 是 | 否 |
| 串行化(serializable) | 否 | 否 | 否 | 是 |
- 指定事务隔离级别:
服务器变量tx_isolation指定,默认为REPEATABLE-READ,可在GLOBAL和SESSION级进行设置
SET tx_isolation=''
READ-UNCOMMITTED
READ-COMMITTED
REPEATABLE-READ
SERIALIZABLE
服务器选项中指定
vim /etc/my.cnf
[mysqld]
transaction-isolation=SERIALIZABLE
注意:服务器变量和服务器选项(即写入配置文件中的选项)并不一样,书写时要注意
并发控制
- 死锁:
两个或多个事务在同一资源相互占用,并请求锁定对方占用的资源的状态如果会话1开启事务对某行进行操作,会话2页对该行进行操作,那么操作会处于等待状态,直至等待超时退出操作 如何强制会话2退出等待状态 show processlist 查看事务列表,显示操作id号 kill 2 关闭正在执行的事务,2为事务id号,用show processlist可以查看 - 事务日志:
事务日志的写入类型为“追加”,因此其操作为“顺序IO”;通常也被称为:预写式日志 write ahead logging
日志文件: ib_logfile0, ib_logfile1
建议:将事务日志存放在一个干净的,独立的分区中
11、日志管理
- 日志
事务日志 transaction log
中继日志 reley log
错误日志 error log
通用日志 general log
慢查询日志 slow query log
二进制日志 binary log
事务日志
- 事务日志:transaction log
事务型存储引擎自行管理和使用,建议和数据文件分开存放更改事务日志路径 mkdir /data/mysqllogs/ 创建自定义事务日志目录 chown mysql.mysql /data/mysqllogs/ 更改权限 vim /etc/my.cnf 更改配置文件 [mysqld] mysqld语句块下 innodb_log_group_home_dir=/data/mysqllogs/ 指定事务日志文件路径redo log
undo log
Innodb事务日志相关配置:
show variables like '%innodb_log%';
innodb_log_file_size 5242880 每个日志文件大小,默认大小为5M
innodb_log_files_in_group 2 日志组成员个数
innodb_log_group_home_dir ./ 事务文件路径
注意:./是指/var/lib/mysql - 中继日志:relay log
主从复制架构中,从服务器用于保存从主服务器的二进制日志中读取的事件开启事务,执行数据库写操作,在提交之前进行事务回滚,回滚完毕后数据库大小不会更改,即执行命令把数据写入数据库,数据库文件变大,但是取消该操作,数据库文件大小不会自动缩减会原来的大小 使用以下命令释放多余的空间:optimize table testlog;
错误日志
- 错误日志
mysqld启动和关闭过程中输出的事件信息
mysqld运行中产生的错误信息
event scheduler运行一个event时产生的日志信息
在主从复制架构中的从服务器上启动从服务器线程时产生的信息 - 错误日志相关配置
SHOW GLOBAL VARIABLES LIKE 'log_error'
错误文件路径:
log_error=/PATH/TO/LOG_ERROR_FILE
是否记录警告信息至错误日志文件
log_warnings=1|0 默认值1
更改错误日志路径:配置文件/etc/my.cnf下 [mysqld_safe] log-error=/var/log/mariadb/mariadb.log
通用日志
- 通用日志:记录对数据库的通用操作,包括错误的SQL语句,会造成日志量较多,占用空间较大,一般情况下不用开启,系统默认为关闭状态
文件:file,默认值
表:table - 通用日志相关设置
general_log=ON|OFF
开启日志,系统会在/var/lib/mysql/目录下自动生成centos7.log文件存放通用日志
general_log_file=HOSTNAME.log
log_output=TABLE|FILE|NONE
示例:
查看mysql数据库中的general_log表
MariaDB [mysql]> use mysql;
MariaDB [mysql]> select * from general_log;
+----------------------------+---------------------------+-----------+-----------+--------------+---------------------------+
| event_time | user_host | thread_id | server_id | command_type | argument |
+----------------------------+---------------------------+-----------+-----------+--------------+---------------------------+
| 2018-10-12 15:09:44.271858 | root[root] @ localhost [] | 2 | 0 | Query | select * from general_log |
| 2018-10-12 15:09:51.461674 | root[root] @ localhost [] | 2 | 0 | Query | select * from general_log |
+----------------------------+---------------------------+-----------+-----------+--------------+---------------------------+
mysql -e 'select * from mysql.general_log' > test.log 把日志从数据库导出慢查询日志
- 慢查询日志:记录执行查询时长超出指定时长的操作
slow_query_log=ON|OFF 开启或关闭慢查询
long_query_time=N 慢查询的阀值,单位秒
slow_query_log_file=HOSTNAME-slow.log 慢查询日志文件
log_slow_filter = admin,filesort,filesort_on_disk,full_join,
full_scan,query_cache,query_cache_miss,tmp_table,tmp_table_on_disk 上述查询类型且查询时长超过long_query_time,则记录日志
log_queries_not_using_indexes=ON 不使用索引或使用全索引扫描,不论是否达到慢查询阀值的语句是否记录日志,默认OFF,即不记录
log_slow_rate_limit = 1 多少次查询才记录,mariadb特有
log_slow_verbosity= Query_plan,explain 记录内容
log_slow_queries = OFF 同slow_query_log 新版已废弃
示例:
开启慢查询日志
set global slow_query_log=on;
慢查询日志位置:/var/lib/mysql/centos7-slow.log
set long_query_time=3 时间阀值,默认为10秒,即命令执行超过10秒就会被记录,更改为3秒
或:在日志文件中更改(永久保存)
vim /etc/my.cnf
[mysqld]
slow_query_log=on 开启慢查询日志
long_query_time=3 设置时间阀值为3秒,即超过3秒就记录下来
测试:
select sleep(2) from teachers; teachers表有4条记录,每条记录sleep2秒,该命令执行需要8秒
查看慢查询日志
cat /var/lib/mysql/centos7-slow.log知识扩展:
查询命令中有多个子句,查看每个子句查询所占用的时间
show variables like '%profiling%'; 查询变量
set profiling=on 开启命令分析功能
show profiles 查看命令执行过程,查看执行命令id号为1
show profile for query 1 查看命令执行详细过程,可以查看sql命令过程中每一步骤占用时间
示例:
MariaDB [hellodb]> select * from testlog where name="wang99000";
+-------+-----------+-------+
| id | name | age |
+-------+-----------+-------+
| 99000 | wang99000 | 99000 |
+-------+-----------+-------+
1 row in set (0.00 sec)
MariaDB [hellodb]> show profiles;
+----------+------------+----------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------------------+
| 1 | 0.00006964 | select * from testlog where name="wang99000" |
+----------+------------+----------------------------------------------+
1 row in set (0.00 sec)
MariaDB [hellodb]> show profile for query 1 ;
+--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.000020 |
| Waiting for query cache lock | 0.000005 |
| checking query cache for query | 0.000007 |
| checking privileges on cached | 0.000003 |
| checking permissions | 0.000017 |
| sending cached result to clien | 0.000010 |
| updating status | 0.000004 |
| cleaning up | 0.000003 |
+--------------------------------+----------+二进制日志
- 二进制日志
记录导致数据改变或潜在导致数据改变的SQL语句
记录已提交的日志
不依赖于存储引擎类型
功能:通过“重放”日志文件中的事件来生成数据副本
注意:建议二进制日志和数据文件分开存放
注意:
二进制日志与事务日志的区别:
1、事务日志依赖于事务功能,依赖于存储引擎;二进制日志并不依赖于存储引擎
2、二进制日志记录数据库已经确定的增删改操作,也即是只记录事务提交过的操作;事务日志记录的是提交过的以及未提交的操作
3、事务日志文件大小确定,默认为5M,因此日志文件在写的过程中不断覆盖旧日志,会丢失以前的日志文件;二进制日志是不断累积的文件,系统默认不会被覆盖和删除
二进制日志记录执行过程,并不记录数据库初始状态,因此二进制日志需要与备份文件相结合才能发挥作用- 二进制日志记录格式
二进制日志记录三种格式
基于“语句”记录:statement,记录语句,默认模式如某条命令更改了很多条记录,但该日志只记录这条命令,并不记录结果 update students set age=20; 只记录该命令 有时会造成有些记录无法还原,如某学员的生日为update students set birth=now(),还原时执行该命令,日期无法还原为正确的日期基于“行”记录:row,记录数据,日志量较大
记录数据库中每一行的更改记录 update students set age=20; 记录该命令更改的每一条记录 可以完全还原,但是产生的日志量最大混合模式:mixed, 让系统自行判定该基于哪种方式进行
格式配置
show variables like ‘binlog_format';mariadb10.2.3版本以前使用statement语句模式 mariadb10.2.4版本以后使用mixed混合模式 - 二进制日志文件的构成
有两类文件
日志文件:mysql|mariadb-bin.文件名后缀,二进制格式
如: mariadb-bin.000001
索引文件:mysql|mariadb-bin.index,文本格式 - 二进制日志相关的服务器变量:
sql_log_bin=ON|OFF:是否记录二进制日志,默认ON
log_bin=/PATH/BIN_LOG_FILE:指定文件位置;默认OFF,表示不启用二进制日志功能,上述两项都开启才可
示例:
把此选项写入配置文件,即使不指定路径,也可以开启功能
log_bin写入配置文件时需要指定文件路径,即log_bin=mysql-bin;如果不指定路径,则系统默认文件名为/var/lib/mysql/目录下的mariadb-bin.000001和mariadb-bin.index
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin 指定文件名为mysql-bin
mysql-bin.index 记录当前有效的二进制日志文件是哪些文件
[root@centos7 mysql]# cat mariadb-bin.index
./mariadb-bin.000001
注意:重启数据库服务,二进制日志文件会自动增加 binlog_format=STATEMENT|ROW|MIXED:二进制日志记录的格式,默认STATEMENT
max_binlog_size=1073741824:单个二进制日志文件的最大体积,到达最大值会自动滚动,默认为1G
说明:文件达到上限时的大小未必为指定的精确值
sync_binlog=1|0:设定是否启动二进制日志即时同步磁盘功能,默认0,由操作系统负责同步日志到磁盘
expire_logs_days=N:二进制日志可以自动删除的天数。默认为0,即不自动删除
- 二进制日志相关配置
查看mariadb自行管理使用中的二进制日志文件列表,及大小
SHOW {BINARY | MASTER} LOGS
查看使用中的二进制日志文件
SHOW MASTER STATUS
查看二进制文件中的指定内容
SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count]
show binlog events in ‘mysql-bin.000001' from 6516 limit 2,3
示例:
查看二进制文件中的指定内容
MariaDB [hellodb]> show binlog events in 'mysql-bin.000001' from 48355435 ;
+------------------+----------+------------+-----------+-------------+--------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+----------+------------+-----------+-------------+--------------------------------------------------------------+
| mysql-bin.000001 | 48355435 | Query | 1 | 48355506 | BEGIN |
| mysql-bin.000001 | 48355506 | Query | 1 | 48355617 | use `hellodb`; insert students values(26,'wang',20,'m',10,1) |
| mysql-bin.000001 | 48355617 | Xid | 1 | 48355644 | COMMIT /* xid=600022 */ |
| mysql-bin.000001 | 48355644 | Query | 1 | 48355715 | BEGIN |
| mysql-bin.000001 | 48355715 | Query | 1 | 48355824 | use `hellodb`; insert students values(27,'li',30,'m',15,1) |
| mysql-bin.000001 | 48355824 | Xid | 1 | 48355851 | COMMIT /* xid=600024 */ |
+------------------+----------+------------+-----------+-------------+--------------------------------------------------------------+
MariaDB [hellodb]> show binlog events in 'mysql-bin.000001' from 48355435 limit 2,3;
+------------------+----------+------------+-----------+-------------+------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+----------+------------+-----------+-------------+------------------------------------------------------------+
| mysql-bin.000001 | 48355617 | Xid | 1 | 48355644 | COMMIT /* xid=600022 */ |
| mysql-bin.000001 | 48355644 | Query | 1 | 48355715 | BEGIN |
| mysql-bin.000001 | 48355715 | Query | 1 | 48355824 | use `hellodb`; insert students values(27,'li',30,'m',15,1) |
+------------------+----------+------------+-----------+-------------+------------------------------------------------------------+日志文件以及相关命令
- mysqlbinlog:二进制日志的客户端命令工具
- 命令格式:
mysqlbinlog [OPTIONS] log_file…
--start-position=# 指定开始位置
--stop-position=#
--start-datetime=
--stop-datetime=
时间格式:YYYY-MM-DD hh:mm:ss
--base64-output[=name]
示例:mysqlbinlog --start-position=6787 --stop-position=7527 /var/lib/mysql/mariadb-bin.000003 mysqlbinlog --start-datetime="2018-01-30 20:30:10" --stop-datetime="2018-01-30 20:35:22" mariadb-bin.000003 - 二进制日志事件的格式:
格式如下:
#at 328
#151105 16:31:40 server id 1 end_log_pos 431 Query thread_id=1 exec_time=0 error_code=0
use \`mydb`/*!*/;
SET TIMESTAMP=1446712300/*!*/;
CREATE TABLE tb1 (id int, name char(30))
/\*!\*/; 事件发生的日期和时间:151105 16:31:40
事件发生的服务器标识:server id 1
事件的结束位置:end_log_pos 431
事件的类型:Query
事件发生时所在服务器执行此事件的线程的ID:thread_id=1
语句的时间戳与将其写入二进制文件中的时间差:exec_time=0
错误代码:error_code=0
事件内容:
GTID:Global Transaction ID,mysql5.6以mariadb10以上版本专属属性:GTID
- 清除指定二进制日志:
PURGE { BINARY | MASTER } LOGS
{ TO 'log_name' | BEFORE datetime_expr }
示例:
PURGE BINARY LOGS TO ‘mariadb-bin.000003’;删除3之前的日志
PURGE BINARY LOGS BEFORE '2017-01-23';
PURGE BINARY LOGS BEFORE '2017-03-22 09:25:30';- 删除所有二进制日志,index文件重新记数
RESET MASTER [TO #]; 日志文件从#开始记数,默认从1开始,一般是master第一次启动时执行,MariaDB10.1.6开始支持TO # - 切换日志文件:
FLUSH LOGS;
切换日志使用场景:需要做阶段性备份,把新日志和旧日志(已备份)分开存放
12、备份还原
-
为什么要备份
灾难恢复:硬件故障、软件故障、自然灾害、黑客攻击、误操作测试等数据丢失场景 -
备份注意要点
能容忍最多丢失多少数据
恢复数据需要在多长时间内完成
需要恢复哪些数据 -
还原要点
做还原测试,用于测试备份的可用性
还原演练 -
备份类型:
完全备份,部分备份
完全备份:整个数据集
部分备份:只备份数据子集,如部分库或表
完全备份、增量备份、差异备份
增量备份:仅备份最近一次完全备份或增量备份(如果存在增量)以来变化的数据,备份较快,还原复杂
差异备份:仅备份最近一次完全备份以来变化的数据,备份较慢,还原简单 -
注意:二进制日志文件不应该与数据文件放在同一磁盘
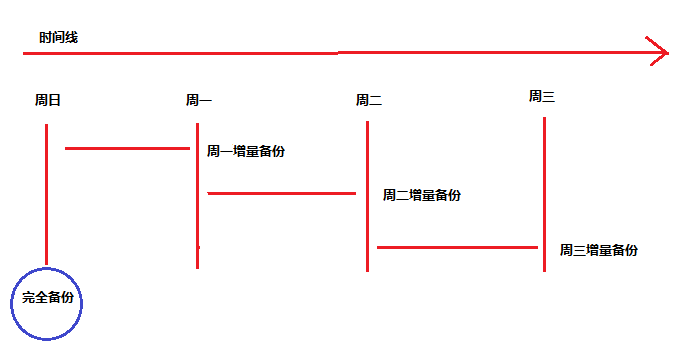
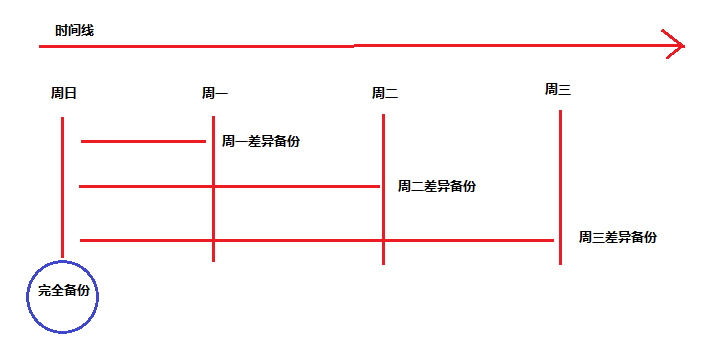
-
冷、温、热备份
冷备:读写操作均不可进行
温备:读操作可执行;但写操作不可执行
热备:读写操作均可执行
MyISAM:温备,不支持热备
InnoDB:都支持 -
物理和逻辑备份
物理备份:直接复制数据文件进行备份,与存储引擎有关,占用较多的空间,速度快
逻辑备份:从数据库中“导出”数据另存而进行的备份,与存储引擎无关,占用空间少,速度慢,可能丢失精度 -
备份时需要考虑的因素
温备的持锁多久
备份产生的负载
备份过程的时长
恢复过程的时长 -
备份什么
数据
二进制日志、InnoDB的事务日志
程序代码(存储过程、函数、触发器、事件调度器)
服务器的配置文件 -
备份工具
cp, tar等复制归档工具:物理备份工具,适用所有存储引擎;只支持冷备;完全备份和部分备份
LVM的快照:先加锁,做快照后解锁,几乎热备;借助文件系统工具进行备份
mysqldump:逻辑备份工具,适用所有存储引擎,温备;支持完全或部分备份;对InnoDB存储引擎支持热备,结合binlog的增量备份
xtrabackup:由Percona提供支持对InnoDB做热备(物理备份)的工具,支持完全备份、增量备份
MariaDB Backup: 从MariaDB 10.1.26开始集成,基于Percona XtraBackup 2.3.8实现
mysqlbackup:热备份, MySQL Enterprise Edition组件
mysqlhotcopy:PERL 语言实现,几乎冷备,仅适用于MyISAM存储引擎,使用LOCK TABLES、FLUSH TABLES和cp或scp来快速备份数据库
cp、tar工具备份
- 使用cp,tar工具进行冷备
注意:mariadb数据库建议把数据文件和表定义文件分开存放,即在配置文件中添加innodb_file_per_table选项。
另外,两台服务器的数据库版本要一致
示例:备份整个数据库
关闭数据库服务
systemctl stop mariadb
把数据库整个目录/var/lib/mysql打包
tar Jcvf /data/mysql.bak.tar.xz /var/lib/mysql
注意:要把数据库配置文件也要做备份
把备份文件复制到第二台服务器
scp /data/mysql.bak.tar.xz 192.168.32.131:/data
scp /etc/my.cnf 192.168.32.131:/etc/
第二台服务器:
关闭数据库服务
systemctl stop mariadb
删除数据库文件(模拟数据库文件损坏)
rm -rf /var/lib/mysql/*
解压备份文件
cd /data
tar xf /data/mysql.bak.tar.xz
cp -ar /data/var/lib/mysql/* /var/lib/mysql/
注意:文件权限问题
启动服务
systemctl start mariadb示例:备份部分数据库
关闭数据库服务
systemctl stop mariadb
进入数据库目录,把需要备份的部分数据库文件以及事务日志打包
cp -av /var/lib/mysql/{hellodb2,ib_log*} /data
注意:要把数据库配置文件进行备份
把备份文件打包并压缩
tar Jcvf /data/mysql1.bak.tar.xz /var/lib/mysql/{hellodb2,ib_log*}
复制传给第二台服务器
scp mysql1.bak.tar.xz 192.168.32.131:/data
第二台服务器:
关闭数据库服务
systemctl stop mariadb
解压备份文件并复制到/var/lib/mysql目录下
cd /data
tar xf /data/mysql1.bak.tar.xz
cp -ar /data/var/lib/mysql/* /var/lib/mysql/
启动服务
systemctl start mariadb基于LVM的备份
- (1) 请求锁定所有表
mysql> FLUSH TABLES WITH READ LOCK; - (2) 记录二进制日志文件及事件位置
mysql> FLUSH LOGS;
mysql> SHOW MASTER STATUS;
mysql -e 'SHOW MASTER STATUS' > /PATH/TO/SOMEFILE - (3) 创建快照
lvcreate -L # -s -p r -n NAME /DEV/VG_NAME/LV_NAME - (4) 释放锁
mysql> UNLOCK TABLES; - (5) 挂载快照卷,执行数据备份
- (6) 备份完成后,删除快照卷
- (7) 制定好策略,通过原卷备份二进制日志
示例:逻辑卷快照备份
注意:前提是数据库放到逻辑卷中,关闭selinux
准备工作:
创建分区/dev/sda6 分区类型为lvm类型,即8e
创建逻辑卷
pvcreate /dev/sda6
vgcreate vg_data /dev/sda6
创建两个逻辑卷分别存放数据库数据和二进制日志文件
lvcreate -n lv_mysqldata -L 2G vg_data
lvcreate -n lv_binlog -L 4G vg_data
格式化分区
mkfs.xfs /dev/vg_data/lv_mysqldata
mkfs.xfs /dev/vg_data/lv_binlog
挂载逻辑卷
mkdir /vg_data/{mysqldata,binlog} -pv
mount /dev/vg_data/lv_mysqldata /vg_data/mysqldata/
mount /dev/vg_data/lv_binlog /vg_data/binlog/
写入/etc/fstab
vim /etc/fstab
/vg_data/lv_mysqldata /vg_data/mysqldata xfs defaults 0 0
/vg_data/lv_binlog /vg_data/binlog xfs defaults 0 0
更改逻辑卷权限
chown -R mysql.mysql /vg_data
更改配置文件
vim /etc/my.cnf
[mysqld]
datadir=/vg_data/mysqldata
log_bin=/vg_data/binlog/mysql-bin
innodb_file_per_table=on
systemctl restart mariadb
根据逻辑卷快照备份恢复数据库数据:
请求锁定所有表
mysql> FLUSH TABLES WITH READ LOCK;
记录二进制日志文件及事件位置
mysql> FLUSH LOGS;
mysql> SHOW MASTER STATUS;
mysql -e 'SHOW MASTER STATUS' > /root/bin.log
[root@centos7 ~]# cat bin.log
Log_name File_size
mysql-bin.000001 7655
在做完快照备份后,会写入新的数据,记录创建快照备份时的二进制日志文件及事件位置,便于根据二进制日志中的事件位置信息恢复从创建快照备份到现在这一段时间内的数据
创建快照,进行数据备份,
lvcreate -s -p r -n snap_mysql -L 1G /dev/vg_data/lv_mysqldata
进入数据库释放锁
mysql> UNLOCK TABLES;
挂载快照卷,执行数据备份
mount -o nouuid,norecovery /dev/vg_data/snap_mysql /mnt
由于快照逻辑卷和数据库数据逻辑卷uuid一样,因此挂载时要使用-o nouuid,norecovery选项
打包并压缩备份文件到/data/目录下
tar Jcvf /data/mysql.bak.xz /mnt
备份完毕删除快照(逻辑卷快照会影响服务器系统性能,因此使用完毕,立即删除)
umount /mnt
lvremove /dev/vg_data/snap_mysql
逻辑卷快照备份后数据的修改(为了实验而故意做的修改,便于实验结果的验证)
insert teachers values(5,'aa',30,'M');
insert teachers values(6,'bb',20,'M');
模拟破坏数据
rm -rf /vg/data/mysqldata/*
还原快照备份的数据
解压备份文件并复制到数据库存放数据目录下
cd /data
tar xf mysql.bak.xz
cp -ar /data/mnt/* /vg_data/mysqldata/
此时数据库中的数据为逻辑卷快照备份的数据
使用二进制日志把数据库数据恢复到当前最新状态
为了防止数据库恢复过程中其他用户访问生成新的数据库文件,可以使用防火墙或锁防止其他人访问
在做备份时,当时的事件位置信息为7655,我们对二进制日志进行分析,把日志中7655后的所有二进制日志文件导出来
[root@centos7 ~]# cat bin.log
Log_name File_size
mysql-bin.000001 7655
查看最新的日志位置编号
mysql -e 'show master logs'
重启服务,根据事件位置导出所需的二进制日志文件
systemctl restart mariadb
mysqlbinlog --start-position=7655 mysql-bin.000001 > /root/binlog.sql
mysqlbinlog mysql-bin.000002 >> /root/binlog.sql
为了防止在导入二进制日志文件时生成新的二进制日志文件,需要暂时关闭二进制日志功能
MariaDB [(none)]> set sql_log_bin=off;
导入二进制日志恢复数据
MariaDB [(none)]> source /root/binlog.sql
开启二进制日志功能,开始正常记录日志
MariaDB [(none)]> set sql_log_bin=on;备份和恢复
- 逻辑备份工具:mysqldump, mydumper, phpMyAdmin
- Schema和数据存储在一起、巨大的SQL语句、单个巨大的备份文件
- mysqldump工具:客户端命令,通过mysql协议连接至mysql服务器进行备份
该工具会把结果默认在屏幕打印出来,需要重定向到其他文件中该工具会把结果默认在屏幕打印出来,需要重定向到其他文件中
示例:mysqldump hellodb 把hellodb数据库创建表的过程在屏幕打印出来 mysqldump hellodb > /data/hellodb_bak.sql 结合重定向进行备份
需要注意的是:
查看备份文件/data/hellodb_bak.sql可以发现,该备份文件中并没有创建数据库的命令,如果直接导入数据库备份文件,会出现错误
如:
[root@centos7 ~]# mysql < /data/hellodb_bak.sql
ERROR 1046 (3D000) at line 22: No database selected
因此在还原之前要先把数据库创建出来,创建出来的数据库名称可以不用与原数据库名称一致
mysql -e 'create database hi' 创建数据库
mysql hi < /data/hellodb2_bak.sql 导入数据库
缺点:这种方法虽然可以恢复数据库数据,但是在不知道原有数据库属性的情况下(如原有数据库字符集为utf8,新创建数据库字符集为latin1),创建数据库导入数据库备份文件,可能会导致数据不一致。因此这种备份方式不推荐使用。- 语法:
mysqldump [OPTIONS] database [tables]
mysqldump [OPTIONS] –B DB1 [DB2 DB3...]
mysqldump [OPTIONS] –A [OPTIONS] - mysqldump参考: https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html
- mysqldump常见选项:
-A, --all-databases 备份所有数据库,含create database,而且数据库属性也会备份下来
-B , --databases db_name… 指定备份的数据库,包括create database语句
注意:一般情况下,备份数据库需要输入数据库用户名密码
示例:
备份数据库
mysqldump -uroot -p -B hi hellodb2 > /data/bak_B.sql 这里我们方便做实验,为空口令登录
还原数据库
mysql < /data/bak_B.sql
为了节省空间,可以在备份的同时压缩备份文件,使用gzip,xz工具进行压缩
mysqldump -B hi |gzip > /data/hi_bak.sql.gz -E, --events:备份相关的所有event scheduler
-R, --routines:备份所有存储过程和自定义函数
--triggers:备份表相关触发器,默认启用,用--skip-triggers,不备份触发器
--default-character-set=utf8 指定字符集
--master-data[=#]: 此选项须启用二进制日志
1:所备份的数据之前加一条记录为CHANGE MASTER TO语句,非注释,不指定#,默认为1
2:记录为注释的CHANGE MASTER TO语句
此选项会自动关闭--lock-tables功能,自动打开-x | --lock-all-tables功能(除非开启--single-transaction)
示例:
在备份日志中标明二进制日志位置
mysqldump -A --master-data=1 > /data/all.sql
less /data/all.mysql 查看日志内容
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=29085596;
#在所备份的数据之前加一条记录为CHANGE MASTER TO语句,该语句默认不存在,还原时不能直接拿来用,因此加上该语句后可以直接拿来就用,便于使用
备份时的日志位置为mysql-bin.000001文件中的29085596位置;当使用二进制日志还原时,可以从此位置还原到当前最新状态
如:在教师表插入一条数据
mysql -e 'use hi;insert teachers values(5,"a",30,"m")'
此时二进制日志最新位置为29085796
当数据丢失后,在备份的基础上,只需还原从29085596到现在位置(即29085796 )的二进制日志即可。-F, --flush-logs :备份前滚动日志,锁定表完成后,执行flush logs命令,生成新的二进制日志文件,配合-A 或 -B 选项时,会导致刷新多次数据库。建议在同一时刻执行转储和日志刷新,可通过和--single-transaction或-x,--master-data 一起使用实现,此时只刷新一次日志
示例:
[root@centos7 ~]# mysqldump -A -F > all_F.sql
[root@centos7 ~]# mysql -e 'show master logs'
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 29085839 |
| mysql-bin.000002 | 288 |
| mysql-bin.000003 | 288 |
| mysql-bin.000004 | 288 |
| mysql-bin.000005 | 288 |
| mysql-bin.000006 | 288 |
| mysql-bin.000007 | 245 |
+------------------+-----------+
由于有6个数据库,因此刷新6次,出现6个新的日志
可通过和--single-transaction或-x,--master-data 一起使用时刷新一次日志--compact 紧致格式,去掉注释内容,只留下二进制日志数据,一般情况下不推荐使用该选项
示例:
[root@centos7 ~]# mysqldump -B hi > /data/hi_bak.sql 未添加该选项
[root@centos7 ~]# wc -l /data/hi_bak.sql
240 /data/hi_bak.sql
[root@centos7 ~]# mysqldump -B hi --compact > /data/hi_bak.sql 添加该选项
[root@centos7 ~]# wc -l /data/hi_bak.sql
89 /data/hi_bak.sql -d, --no-data 只备份表结构
-t, --no-create-info 只备份数据,不备份create table
-n,--no-create-db 不备份create database,可被-A或-B覆盖
--flush-privileges 备份mysql或相关时需要使用
-f, --force 忽略SQL错误,继续执行
--hex-blob 使用十六进制符号转储二进制列,当有包括BINARY, VARBINARY,BLOB,BIT的数据类型的列时使用,避免乱码
-q, --quick 不缓存查询,直接输出,加快备份速度
- MyISAM备份选项:
支持温备;不支持热备,所以必须先锁定要备份的库,而后启动备份操作
锁定方法如下:
-x,--lock-all-tables:加全局读锁,锁定所有库的所有表,同时加--single-transaction或--lock-tables选项会关闭此选项功能
注意:数据量大时,可能会导致长时间无法并发访问数据库
-l,--lock-tables:对于需要备份的每个数据库,在启动备份之前分别锁定其所有表,默认为on,--skip-lock-tables选项可禁用,对备份MyISAM的多个库,可能会造成数据不一致
注:以上选项对InnoDB表一样生效,实现温备,但不推荐使用 - InnoDB备份选项: 支持热备,可用温备但不建议用
--single-transaction
此选项Innodb中推荐使用,不适用MyISAM,此选项会开始备份前,先执行START TRANSACTION指令开启事务
此选项通过在单个事务中转储所有表来创建一致的快照。 仅适用于存储在支持多版本控制的存储引擎中的表(目前只有InnoDB可以); 转储不保证与其他存储引擎保持一致。 在进行单事务转储时,要确保有效的转储文件(正确的表内容和二进制日志位置),没有其他连接应该使用以下语句:ALTER TABLE,DROP TABLE,RENAME TABLE,TRUNCATE TABLE
此选项和--lock-tables(此选项隐含提交挂起的事务)选项是相互排斥
备份大型表时,建议将--single-transaction选项和--quick结合一起使用
示例1:完全备份还原至最新状态
恢复虚拟机到初始状态,以新的机器进行试验
安装mariadb-server
mkdir /data/binlog
chown mysql.mysql /data/binlog
(1)准备工作:
vim /etc/my.cnf
[mysqld]
log-bin=/data/binlog/mysql-bin 启用二进制日志并指定路径
建议数据库数据和二进制日志分离存放
重启数据库
(2)备份:对数据库进行备份并压缩
mysqldump -A -F --single-transaction --master-data=2 | gzip > /data/all`date +%F`.sql.gz
解压数据库备份文件
cd /datta
gzip -d all.sql.gz
查看备份文件中备份时的位置信息
less all.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=245;
对数据库增加新的数据,模拟备份后新增加数据
MariaDB [hellodb]> insert teachers values(5,'a',20,'M');
MariaDB [hellodb]> insert teachers values(6,'b',30,'M');
(3)模拟破坏数据库
rm -rf /var/lib/mysql/*
停止服务
systemctl stop mariadb
注意:从还原开始,禁止用户访问数据库,防止用户看到还原产生的“脏数据”
(4)还原:还原到备份时状态
在新的服务器重装系统,安装数据库(注意数据库版本要一致)
启动服务,自动生成空的数据库文件。如果是二进制安装,则需要执行生成数据库的脚本来生成数据库文件,进而导入备份数据库文件
systemctl start mariadb
由于启动数据库服务,导入备份数据库文件会产生二进制日志,那么二进制日志位置将会产生变化,产生变化后无法再使用二进制日志把数据库恢复的最新状态,因此需要关闭暂时二进制日志功能
msql
MariaDB [(none)]> set sql_log_bin=off;
注意:由于当前对二进制功能的设置为会话级,因此不能退出当前数据库会话,否则会失效,因此需要另外开启一个会话进行后续设置;如果退出当前会话,则需要分析二进制日志文件找到导入备份数据库文件前的位置,导出所需的二进制日志
导入数据库备份文件
cd /data/
gzip -d all.sql.gz 解压备份文件
mysql < /data/all.sql
此时,数据库恢复到备份时的状态,
(5)还原到数据库最新状态
grep "CHANGE MASTER" /data/all.sql 查看position位置信息:mysql-bin.000002 245
通过分析查看二进制日志,导出恢复数据库所需的二进制日志文件,如果有多个日志文件,需要全部导出,注意导出时使用追加而不是重定向
mysqlbinlog --start-position=245 /data/logbin/mysql-bin.000002 > /data/incr.sql
mysqlbinlog /data/logbin/mysql-bin.000003 >> /data/incr.sql
mysqlbinlog /data/logbin/mysql-bin.000004 >> /data/incr.sql
进入数据库,关闭二进制功能,
mysql
MariaDB [(none)]> set sql_log_bin=off;
MariaDB [(none)]> source /data/logbin/incr.sql 导入恢复数据所需的二进制日志文件
MariaDB [hellodb]> set sql_log_bin=on; 开启二进制日志继续记录日志
(6)还原完毕,开放用户访问数据库示例2:恢复误删除的表
恢复虚拟机到初始状态
删除二进制日志,删除备份
rm -rf /data/logbin/incr.sql
rm -rf /data/all.sql
(1)准备工作:
启用二进制日志功能
vim /etc/my.cnf
[mysqld]
log-bin=/data/logbin/mysql-bin
(2)对数据库做完全备份:
mysqldump -A -F --single-transaction --master-data=2|gzip > /data/all.sql.gz
(3)备份后,模拟新增数据修改表
MariaDB [hellodb]> insert teachers values(7,'c',30,'F');
MariaDB [hellodb]> insert teachers values(8,'d',30,'M');
call testlog 调用存储过程,生成testlog表
(4)模拟破坏数据,删除表
MariaDB [hellodb]> drop table testlog;
(5)删除表以后,继续增加数据
(6)禁止用户访问数据库
还原时,为了安全,增加一个全局锁,防止数据库被更改
MariaDB [(none)]> flush tables with read lock;
注意:此时要禁止用户访问数据库,使用防火墙等
(7)还原到备份时状态
注意:使用完全备份还原必须从初始化状态还原
systemctl stop mariadb 关闭服务
rm -rf /var/lib/mysql/* 删除数据库文件
systemctl start mariadb 开启服务,生成数据库文件
关闭二进制功能
mysql
MariaDB [(none)]> set sql_log_bin=off;
注意:此会话不能退出也不能关闭,后续操作开启两一个会话进行
解压备份文件
cd /data
gzip -d all.sql
导入数据库备份,恢复数据库到备份时状态
mysql
MariaDB [(none)]> source /data/all.sql;
(8)分析二进制日志,找到drop table 指令
查看备份时位置信息mysql-bin.000002 245
less /data/all.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=245;
导出mysql-bin.000002日志文件中从245开始的所有二进制日志,分析二进制日志,找到日志中误删除数据库的命令,删除该命令
cd /data/logbin
mysqlbinlog --start-position=245 mysql-bin.000002 > /data/incr.sql
vim /data/incr.sql
#DROP TABLE `testlog` /* generated by server */ 注释掉误删除命令保存并退出
把更改后的二进制日志导出
mysqlbinlog --start-position=245 mysql-bin.000002 > /data/incr.sql
mysqlbinlog mysql-bin.000003 >> /data/incr.sql
mysqlbinlog mysql-bin.000004 >> /data/incr.sql
(9)还原数据库到最新状态
把导出的二进制日志导入数据库
mysql
MariaDB [test]> set sql_log_bin=off;
MariaDB [test]> source /data/incr.sql;
MariaDB [test]> set sql_log_bin=on;
(10)检查数据库数据是否完全恢复
(11)如果数据库数据完全无误,开放用户访问数据库生产环境实战备份策略
- InnoDB建议备份策略
mysqldump –uroot –A –F –E –R --single-transaction --master-data=1 --flush-privileges --triggers --default-character-set=utf8 --hex-blob >$BACKUP/fullbak_$BACKUP_TIME.sql - MyISAM建议备份策略
mysqldump –uroot –A –F –E –R –x --master-data=1 --flush-privileges --triggers --default-character-set=utf8 --hex-blob >$BACKUP/fullbak_$BACKUP_TIME.sql
Xtrabackup
- Percona
官网:www.percona.com
percona-server
InnoDB --> XtraDB - Xtrabackup
percona提供的mysql数据库备份工具,惟一开源的能够对innodb和xtradb数据库进行热备的工具
手册:https://www.percona.com/doc/percona-xtrabackup/LATEST/index.html - 特点:
备份还原过程快速、可靠
备份过程不会打断正在执行的事务
能够基于压缩等功能节约磁盘空间和流量
自动实现备份检验
开源,免费 - Xtrabackup2.2版之前包括4个可执行文件:
innobackupex: Perl 脚本
xtrabackup: C/C++ 编译的二进制
xbcrypt: 加解密
xbstream: 支持并发写的流文件格式 - xtrabackup 是用来备份 InnoDB 表的,不能备份非 InnoDB 表,和 MySQL Server 没有交互
- innobackupex 脚本用来备份非 InnoDB 表,同时会调用 xtrabackup 命令来备份 InnoDB 表,还会和 MySQL Server 发送命令进行交互,如加全局读锁(FTWRL)、获取位点(SHOW SLAVE STATUS)等。即innobackupex是在 xtrabackup 之上做了一层封装实现的
- 虽然目前一般不用 MyISAM 表,只是 MySQL 库下的系统表是 MyISAM 的,因此备份基本都通过 innobackupex 命令进行
Xtrabackup备份过程

Xtrabackup的新版变化
- xtrabackup版本升级到2.4后,相比之前的2.1有了比较大的变化:
innobackupex 功能全部集成到 xtrabackup 里面,只有一个 binary程序,另外为了兼容考虑,innobackupex作为 xtrabackup 的软链接,即xtrabackup现在支持非Innodb表备份,并且Innobackupex在下一版本中移除,建议通过xtrabackup替换innobackupex - xtrabackup安装:
yum install percona-xtrabackup 在EPEL源中
最新版本下载安装:
https://www.percona.com/downloads/XtraBackup/LATEST/
Xtrabackup
- 备份:innobackupex [option] BACKUP-ROOT-DIR
- 选项说明:https://www.percona.com/doc/percona-xtrabackup/LATEST/genindex.html
--user:该选项表示备份账号
--password:该选项表示备份的密码
--host:该选项表示备份数据库的地址
--databases:该选项接受的参数为数据库名,如果要指定多个数据库,彼此间需要以空格隔开;如:"xtra_testdba_test",同时,在指定某数据库时,也可以只指定其中的某张表。如:"mydatabase.mytable"。该选项对innodb引擎表无效,还是会备份所有innodb表
--defaults-file:该选项指定从哪个文件读取MySQL配置,必须放在命令行第一个选项位置
--incremental:该选项表示创建一个增量备份,需要指定--incremental-basedir
--incremental-basedir:该选项指定为前一次全备份或增量备份的目录,与--incremental同时使用
--incremental-dir:该选项表示还原时增量备份的目录
--include=name:指定表名,格式:databasename.tablename - Prepare:innobackupex --apply-log [option] BACKUP-DIR
- 选项说明:
--apply-log:一般情况下,在备份完成后,数据尚且不能用于恢复操作,因为备份的数据中可能会包含尚未提交的事务或已经提交但尚未同步至数据文件中的事务。因此,此时数据文件仍处理不一致状态。此选项作用是通过回滚未提交的事务及同步已经提交的事务至数据文件使数据文件处于一致性状态
--use-memory:和--apply-log选项一起使用,当prepare 备份时,做crash recovery分配的内存大小,单位字节,也可1MB,1M,1G,1GB等,推荐1G
--export:表示开启可导出单独的表之后再导入其他Mysql中
--redo-only:此选项在prepare base full backup,往其中合并增量备份时候使用,但不包括对最后一个增量备份的合并 - 还原:innobackupex --copy-back [选项] BACKUP-DIR
- innobackupex --move-back [选项] [--defaults-group=GROUP-NAME] BACKUP-DIR
- 选项说明:
--copy-back:做数据恢复时将备份数据文件拷贝到MySQL服务器的datadir
--move-back:这个选项与--copy-back相似,唯一的区别是它不拷贝文件,而是移动文件到目的地。这个选项移除backup文件,用时候必须小心。使用场景:没有足够的磁盘空间同事保留数据文件和Backup副本 - 还原注意事项:
1.datadir目录必须为空。除非指定innobackupex --force-non-empty-directorires选项指定,否则--copy-backup选项不会覆盖
2.在restore之前,必须shutdown MySQL实例,不能将一个运行中的实例restore到datadir目录中
3.由于文件属性会被保留,大部分情况下需要在启动实例之前将文件的属主改为mysql,这些文件将属于创建备份的用户
chown -R mysql:mysql /data/mysql
以上需要在用户调用innobackupex之前完成
--force-non-empty-directories:指定该参数时候,使得innobackupex --copy-back或--move-back选项转移文件到非空目录,已存在的文件不会被覆盖。如果--copy-back和--move-back文件需要从备份目录拷贝一个在datadir已经存在的文件,会报错失败
注意:
增量备份时,事务跨备份存在,如:一个事务在前一次备份中执行了一部分,在下一次备份中执行剩余部分
还原时,如果数据库正常工作,会把前一次备份中执行了一部分的事务进行回滚,那么下一次的备份还原时则无法正常还原,因为事务的前一部分执行动作被回滚
xtrabackup还原时,保持备份时的状态,使其不回滚
xtrabackup还原时,把完全备份和增量备份的数据还原到临时目录中,等数据全部还原完毕,再把临时目录下的数据复制到数据库存目录下
注意:还原时,数据库一定要处于关闭状态
LSN 日志序列号
数据库基础单位:块,16k大小
序列号随着数据的增加而变大,备份时会记录备份文件中序列号的最大值,下一次备份时,以最大值为基础,只需备份序列号大于此最大值的部分即可
如第一次备份时记录的最大值为10000,序列号随着数据的增加而变大,第二次备份时备份序列号大于10000的即可,备份完毕后记录下此次备份序列号的最大值,方便第三次备份备份生成的相关文件
- 使用innobakupex备份时,其会调用xtrabackup备份所有的InnoDB表,复制所有关于表结构定义的相关文件(.frm)、以及MyISAM、MERGE、CSV和ARCHIVE表的相关文件,同时还会备份触发器和数据库配置信息相关的文件。这些文件会被保存至一个以时间命名的目录中,在备份时,innobackupex还会在备份目录中创建如下文件:
(1)xtrabackup_info:innobackupex工具执行时的相关信息,包括版本,备份选项,备份时长,备份LSN(log sequence number日志序列号),BINLOG的位置
(2)xtrabackup_checkpoints:备份类型(如完全或增量)、备份状态(如是否已经为prepared状态)和LSN范围信息,每个InnoDB页(通常为16k大小)都会包含一个日志序列号LSN。LSN是整个数据库系统的系统版本号,每个页面相关的LSN能够表明此页面最近是如何发生改变的
(3)xtrabackup_binlog_info:MySQL服务器当前正在使用的二进制日志文件及至备份这一刻为止二进制日志事件的位置,可利用实现基于binlog的恢复
(4)backup-my.cnf:备份命令用到的配置选项信息
(5)xtrabackup_logfile:备份生成的日志文件
示例1:旧版Xtrabackup完全备份及还原
1、在原主机
innobackupex --user=root /backups
scp -r /backups/2018-02-23_11-55-57/ 目标主机:/data/
2、在目标主机
innobackupex --apply-log /data/2018-02-23_11-55-57/
systemctl stop mariadb
rm -rf /var/lib/mysql/*
innobackupex --copy-back /data/2018-02-23_11-55-57/
chown -R mysql.mysql /var/lib/mysql/
systemctl start mariadb示例2:新版Xtrabackup完全备份及还原
1 在原主机做完全备份到/data/backups
xtrabackup --backup --target-dir=/backups/
scp -r /backups/* 目标主机:/backups
2 在目标主机上
1)预准备:确保数据一致,提交完成的事务,回滚未完成的事务
xtrabackup --prepare --target-dir=/backups/
2)复制到数据库目录
注意:数据库目录必须为空,MySQL服务不能启动
xtrabackup --copy-back --target-dir=/backups/
3)还原属性
chown -R mysql:mysql /var/lib/mysql
4)启动服务
systemctl start mariadb示例3:旧版Xtrabackup完全、增量备份及还原
1、在原主机
innobackupex /backups
mkdir /backups/inc{1,2}
修改数据库内容
innobackupex --incremental /backups/inc1 --incremental-basedir=/backups/2018-02-23_14-21-42(完全备份生成的路径)
再次修改数据库内容
innobackupex --incremental /backups/inc2 --incremental-basedir=/backups/inc1/2018-02-23_14-26-17 (上次增量备份生成的路径)
scp -r /backups/* 目标主机:/data/
2、在目标主机
不启动mariadb
rm -rf /var/lib/mysql/*
innobackupex --apply-log --redo-only /data/2018-02-23_14-21-42/
innobackupex --apply-log --redo-only /data/2018-02-23_14-21-42/ --incremental-dir=/data/inc1/2018-02-23_14-26-17
innobackupex --apply-log /data/2018-02-23_14-21-42/ --incremental-dir=/data/inc2/2018-02-23_14-28-29/
ls /var/lib/mysql/
innobackupex --copy-back /data/2018-02-23_14-21-42/
chown -R mysql.mysql /var/lib/mysql/
systemctl start mariadb示例4:新版Xtrabackup完全、增量备份及还原
1 备份过程
1)完全备份:xtrabackup --backup --target-dir=/backups/base
2)第一次修改数据
3)第一次增量备份
xtrabackup --backup --target-dir=/backups/inc1 --incremental-basedir=/backups/base
4)第二次修改数据
5)第二次增量
xtrabackup --backup --target-dir=/backups/inc2 --incremental-basedir=/backups/inc1
6)scp -r /backups/* 目标主机:/backups/
备份过程生成三个备份目录
/backups/{base,inc1,inc2}
2还原过程
1)预准备完成备份,此选项--apply-log-only阻止回滚未提完成的事务
xtrabackup --prepare --apply-log-only --target-dir=/backups/base
2)合并第1次增量备份到完全备份,
xtrabackup --prepare --apply-log-only --target-dir=/backups/base --incremental-dir=/backups/inc1
3)合并第2次增量备份到完全备份:最后一次还原不需要加选项--apply-log-only
xtrabackup --prepare --target-dir=/backups/base --incremental-dir=/backups/inc2
4)复制到数据库目录,注意数据库目录必须为空,MySQL服务不能启动
xtrabackup --copy-back --target-dir=/data/backups/base
5)还原属性:chown -R mysql:mysql /var/lib/mysql
6)启动服务:systemctl start mariadb示例5:Xtrabackup单表导出导入
1 单表备份
innobackupex --include='hellodb.students' /backups
2 备份表结构
mysql -e 'show create table hellodb.students' > student.sql
3 删除表
mysql -e 'drop table hellodb.students‘
4 innobackupex --apply-log --export /backups/2018-02-23_15-03-23/
5 创建表
mysql>CREATE TABLE `students` (
`StuID` int(10) unsigned NOT NULL AUTO_INCREMENT,
`Name` varchar(50) NOT NULL,
`Age` tinyint(3) unsigned NOT NULL,
`Gender` enum('F','M') NOT NULL,
`ClassID` tinyint(3) unsigned DEFAULT NULL,
`TeacherID` int(10) unsigned DEFAULT NULL,
PRIMARY KEY (`StuID`)
) ENGINE=InnoDB AUTO_INCREMENT=26 DEFAULT CHARSET=utf8
6 删除表空间
alter table students discard tablespace;
7 cp /backups/2018-02-23_15-03-23/hellodb/students.{cfg,exp,ibd} /var/lib/mysql/hellodb/
8 chown -R mysql.mysql /var/lib/mysql/hellodb/
9 mysql>alter table students import tablespace;MySQL复制
- 扩展方式: Scale Up(向上扩展) ,Scale Out(向外扩展)
- MySQL的扩展
读写分离
复制:每个节点都有相同的数据集
向外扩展
二进制日志
单向 - 复制的功用:
数据分布
负载均衡读
备份
高可用和故障切换
MySQL升级测试 - 缺点:
用户访问从客户端到主服务器为并行写(支持事务,使用事务可以同时写),效率高;从主服务器复制到从服务器为串行写(二进制日志为累加写入,并不是同时进行,而是需要一个一个的写入从服务器),效率较低;这样一来主从同步就产生了很大的延迟
MySQL读写分离
-
读写分离应用:
mysql-proxy:Oracle,https://downloads.mysql.com/archives/proxy/
Atlas:Qihoo,https://github.com/Qihoo360/Atlas/blob/master/README_ZH.md
dbproxy:美团,https://github.com/Meituan-Dianping/DBProxy
Cetus:网易乐得,https://github.com/Lede-Inc/cetus
Amoeba:https://sourceforge.net/projects/amoeba/
Cobar:阿里巴巴,Amoeba的升级版
Mycat:基于Cobar, http://www.mycat.io/
ProxySQL:https://proxysql.com/ -
一主一从
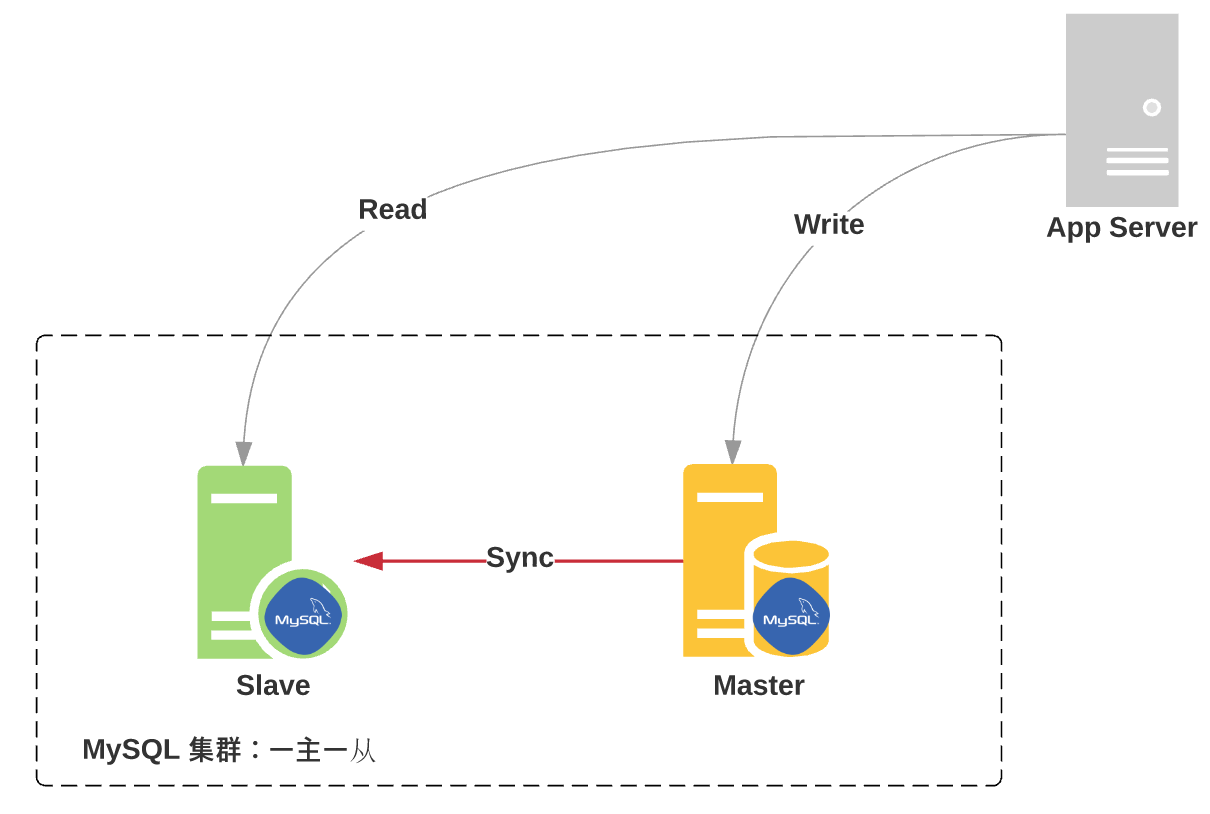
- 一主多从
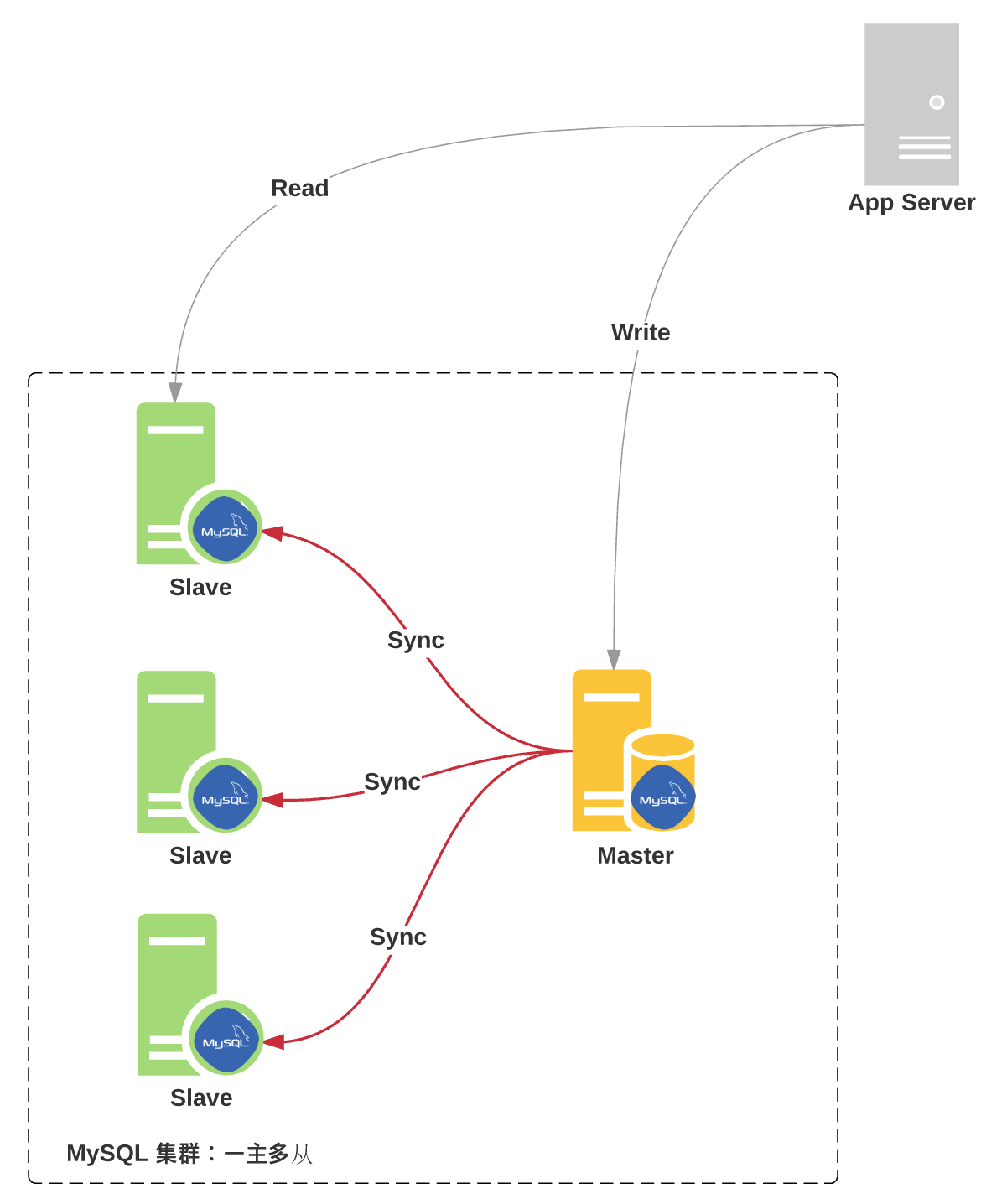
- 主从复制原理
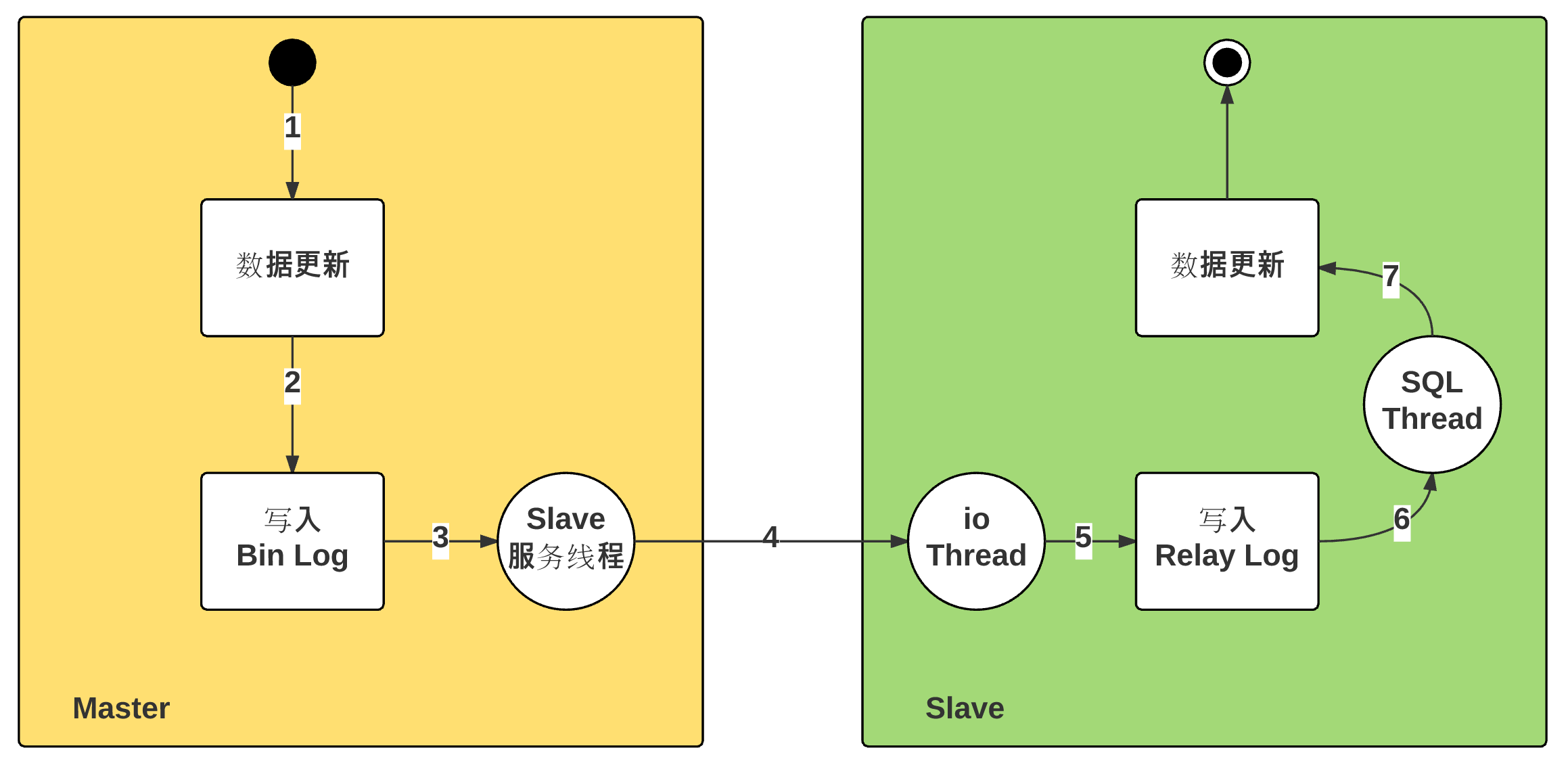
主从复制机制:
异步复制
客户端向主服务器写入数据,主服务器向从服务器发起数据同步,只要从服务器数据发生改变,无论后续从服务器数据是否同步成功,主服务器都返回同步成功的结果给客户端
同步复制
客户端向主服务器写入数据,主服务器向从服务器发起数据同步,只有当从服务器数据同步成功后,主服务器才会返回同步成功结果给客户端
缺点:同步效率很低,不推荐这种做法
- MySQL垂直分区
把一个表拆分为多个表,不同的表存放在不同的数据库服务器上,减轻服务器压力,提升性能
缺点:无法进行多表查询
- MySQL水平分片(Sharding)
把同一个表横向切分为多片,根据需求按照步进方式(如:奇数行或偶数行)进行分片,存在不同服务器上
需要分片管理器
- 对应shard中查询相关数据
- 主从复制线程:
主节点:
dump Thread:为每个Slave的I/O Thread启动一个dump线程,用于向其发送binary log events
从节点:
I/O Thread:向Master请求二进制日志事件,并保存于中继日志中
SQL Thread:从中继日志中读取日志事件,在本地完成重放 - 跟复制功能相关的文件:
master.info:用于保存slave连接至master时的相关信息,例如账号、密码、服务器地址等
relay-log.info:保存在当前slave节点上已经复制的当前二进制日志和本地replay log日志的对应关系 - 主从复制特点:
异步复制
主从数据不一致比较常见 - 复制架构:
Master/Slave, Master/Master, 环状复制
一主多从
从服务器还可以再有从服务器
一从多主:适用于多个不同数据库 - 复制需要考虑二进制日志事件记录格式
STATEMENT(5.0之前)
ROW(5.1之后,推荐)
MIXED - MySQL复制模型
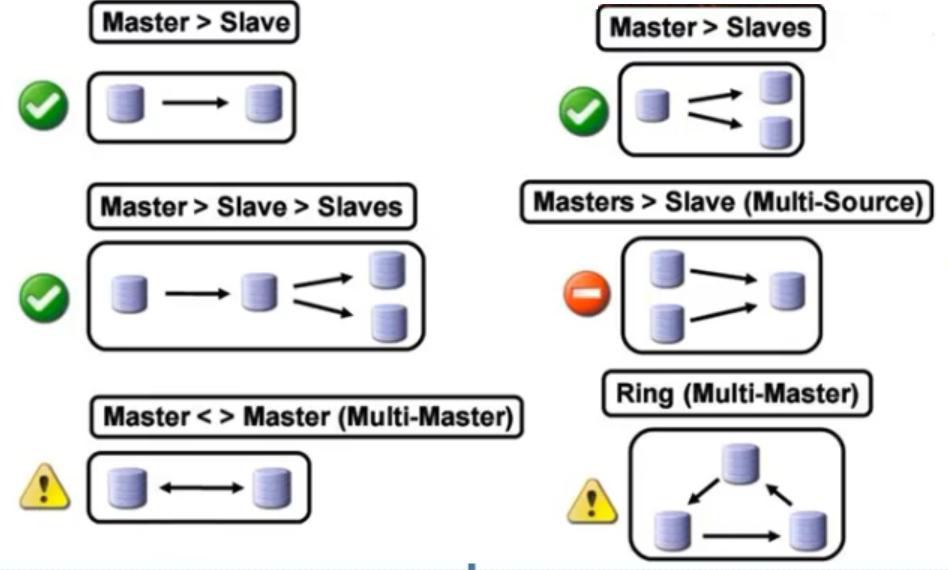
从服务器收到主服务器发来的二进制日志后,在执行过程中需要搞清楚事件是在本机发生的事件还是在别的主服务器上发生的事件
对于数据服务器来说,最终是把数据写入从服务器的数据库中,在写的时候需要分清楚对数据库的更新操作是来自于自身的更改还是来自于主服务器的更改,因此需要标识主服务器和从服务器的身份
这种标志称为server_id
- 主从配置过程:参看官网
https://mariadb.com/kb/en/library/setting-up-replication/
https://dev.mysql.com/doc/refman/5.5/en/replication-configuration.html - 主节点配置:
(1) 启用二进制日志
[mysqld]
log_bin
(2) 为当前节点设置一个全局惟一的ID号
[mysqld]
server_id=#
log-basename=master 可选项,设置datadir中日志名称,确保不依赖主机名
(3) 创建有复制权限的用户账号
GRANT REPLICATION SLAVE ON . TO 'repluser'@'HOST' IDENTIFIED BY 'replpass'; - 从节点配置:
(1) 启动中继日志
[mysqld]
server_id=# 为当前节点设置一个全局惟的ID号
relay_log=relay-log relay log的文件路径,默认值hostname-relay-bin
relay_log_index=relay-log.index 默认值hostname-relay-bin.index
(2) 使用有复制权限的用户账号连接至主服务器,并启动复制线程
mysql> CHANGE MASTER TO MASTER_HOST='host', MASTER_USER='repluser', MASTER_PASSWORD='replpass', MASTER_LOG_FILE='mysql-bin.xxxxx', MASTER_LOG_POS=#;
mysql> START SLAVE [IO_THREAD|SQL_THREAD];
示例:主从复制
实验环境:
master主机:192.168.32.200
slave01主机:192.168.32.201
主节点slave配置:
配置文件:
[root@master ~]# vim /etc/my.cnf
[mysqld]
server_id=1 #指定serverid
innodb_file_per_table #分表显示,可省略,建议添加
log_bin #开启二进制日志
skip_name_resolve #关闭ip地址反解,建议添加
启动数据库
systemctl start mariadb
授权从服务器:
[root@master ~]# mysql
MariaDB [(none)]> show master status; #查看二进制日志位置,便于确定日志复制位置
+--------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+--------------------+----------+--------------+------------------+
| mariadb-bin.000001 | 245 | | |
+--------------------+----------+--------------+------------------+
注意:如果从此位置开始复制,将会把后续的创建账号的操作同步到从服务器,如果不需要从服务器有此操作,可以在授权从服务器权限后的位置开始同步
把该操作同步到从服务器的好处是当主服务器出现故障,从服务器提升为主服务器时,其他从服务器可以使用该账号,而无需再次创建
MariaDB [(none)]> grant replication slave on *.* to 'repluser'@'192.168.32.%' identified by 'centos'; #授权从服务器能够从主服务器同步数据库的权限
导入数据库
[root@master ~]# mysql < hellodb_innodb.sql #导入数据库用于测试
[root@master ~]# mysql
MariaDB [(none)]> show master status;
+--------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+--------------------+----------+--------------+------------------+
| mariadb-bin.000001 | 7814 | | |
+--------------------+----------+--------------+------------------+
从节点slave01配置
配置文件:
[root@slave01 ~]# vim /etc/my.cnf
[mysqld]
server_id=2 #指定从服务器serverid
relay_log=relay-log
relay_log_index=relay-log.index
innodb_file_per_table
skip_name_resolve
启动数据库
systemctl start mariadb
使用有复制权限的用户账号连接至主服务器,并启动复制线程
MariaDB [(none)]> help change master to #使用帮助查看具体复制命令,根据示例进行更改即可
MariaDB [(none)]> change master to
-> MASTER_HOST='192.168.32.200',
-> MASTER_USER='repluser',
-> MASTER_PASSWORD='centos',
-> MASTER_PORT=3306,
-> MASTER_LOG_FILE='mariadb-bin.000001 ',
-> MASTER_LOG_POS=245;
MariaDB [(none)]> show slave status\G #查看从服务器状态
MariaDB [(none)]> start slave; #开始复制
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.32.200
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000001
Read_Master_Log_Pos: 7812 #读取主节点日志位置
Relay_Log_File: relay-log.000002
Relay_Log_Pos: 8098
Relay_Master_Log_File: mariadb-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 7812 #同步主节点日志位置
Relay_Log_Space: 8386
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
1 row in set (0.00 sec)
注意:在该状态中Read_Master_Log_Pos: 7812和Exec_Master_Log_Pos: 7812 有可能会不一致,这是因为主从复制可能存在延迟,处于正在复制过程中,当同步完成后,二者位置会变为一样
查看数据库是否同步到从节点
MariaDB [(none)]> use hellodb
MariaDB [hellodb]> show tables; #查看数据中的表是否同步
+-------------------+
| Tables_in_hellodb |
+-------------------+
| classes |
| coc |
| courses |
| scores |
| students |
| teachers |
| toc |
+-------------------+
7 rows in set (0.00 sec)
MariaDB [hellodb]> select user,host from mysql.user; #查看授权账号是否同步
+----------+--------------+
| user | host |
+----------+--------------+
| root | 127.0.0.1 |
| repluser | 192.168.32.% |
| root | ::1 |
| | centos7 |
| root | centos7 |
| | localhost |
| root | localhost |
+----------+--------------+
7 rows in set (0.00 sec)
在主节点插入数据测试同步
MariaDB [hellodb]> insert teachers values(5,'a',20,'M');
查看日志信息
MariaDB [hellodb]> show master status;
+--------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+--------------------+----------+--------------+------------------+
| mariadb-bin.000001 | 8012 | | |
+--------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
在从节点查看同步信息
MariaDB [hellodb]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.32.200
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000001
Read_Master_Log_Pos: 8012
Relay_Log_File: relay-log.000002
Relay_Log_Pos: 8298
Relay_Master_Log_File: mariadb-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 8012
Relay_Log_Space: 8586
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
查看相关日志文件内容
[root@slave01 ~]# cd /var/lib/mysql
[root@slave01 mysql]# ll #查看生成的日志文件
-rw-rw---- 1 mysql mysql 89 Dec 23 17:16 master.info
-rw-rw---- 1 mysql mysql 245 Dec 23 17:16 relay-log.000001
-rw-rw---- 1 mysql mysql 19 Dec 23 17:16 relay-log.index
-rw-rw---- 1 mysql mysql 45 Dec 23 17:16 relay-log.info
[root@slave01 mysql]# cat master.info #记录授权信息
18
mariadb-bin.000001
245
192.168.32.200
repluser
centos
3306
60
0
0
1800.000
0
[root@slave01 mysql]# cat relay-log.in
relay-log.index relay-log.info
[root@slave01 mysql]# cat relay-log.info #记录二进制日志位置信息
./relay-log.000001
4
mariadb-bin.000001
245
[root@slave01 mysql]# cat relay-log.index #中继日志名称
./relay-log.000001- 如果主节点已经运行了一段时间,且有大量数据时,如何配置并启动slave节点
通过备份恢复数据至从服务器
复制起始位置为备份时,二进制日志文件及其POS
示例:
实验环境:
master主机:192.168.32.200
slave01主机:192.168.32.201
新增slave02节点:192.168.32.202
配置文件:
[root@slave02 ~]# vim /etc/my.cnf
[mysqld]
server_id=3
relay_log=relay-log
relay_log_index=relay-log.index
innodb_file_per_table
skip_name_resolve
在主节点192.168.32.200上
数据库完全备份:
mysqldump -A -F --single-transaction --master-data=1 >all.sql
复制到新增slave02节点上
scp all.sql 192.168.32.202:/root/
在新增slave02节点上
需要对all.sql中的语句进行修改,就可以同步到最新状态,而无需执行同步语句
vim all.sql
CHANGE MASTER TO MASTER_LOG_FILE='mariadb-bin.000002', MASTER_LOG_POS=245;
可以发现以上语句就是从节点进行同步时执行的sql语句,但是缺少授权的用户,密码以及主机名,
只需把这三项信息添加进去后,然后把all.sql导入新增节点数据库即可把数据同步到最新状态
不需要在完全备份的基础上进行同步操作
更改后的语句为:
CHANGE MASTER TO MASTER_HOST='192.168.32.200', MASTER_USER='repluser',MASTER_PASSWORD='centos',MASTER_PORT=3306,MASTER_LOG_FILE='mariadb-bin.000002', MASTER_LOG_POS=245;
把all.sql导入slave02从节点数据库
[root@slave02 ~]# systemctl start mariadb
[root@slave02 ~]# mysql < all.sql
启动主从同步
MariaDB [(none)]> start slave;
查看同步状态
MariaDB [(none)]> show slave status\G
在主节点新增一条记录测试,是否能够同步
在hellodb数据库teachers表添加一条记录
MariaDB [hellodb]> insert teachers values(6,'b',30,'F');
在slave02节点上查看同步信息
MariaDB [hellodb]> use hellodb;
MariaDB [hellodb]> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
+-----+---------------+-----+--------+- 如果主服务器宕机,如何提升一个从服务器代替主服务器工作
提升数据库内容最新的从服务器为主服务器,丢失数据较少
如何确定哪个从服务器上的数据库内容最新
查看同步信息,即查看/var/lib/mysql/master.info
示例:
思路:清除从服务器上的信息,更改其他从服务器上主服务器的信息。另外,在配置过程中要禁止其他用户对数据库进行操作,要对数据库加锁
实验环境
master主机:192.168.32.200 出现故障
slave01主机:192.168.32.201 提升该从节点为主节点
slave02主机:192.168.32.202
假设提升slave01节点192.168.32.201位主节点
在主节点192.168.32.200:
模拟主节点mariadb服务出现故障,关闭主服务器192.168.32.200的maridb服务
在从节点slave01 192.168.32.201上
查看同步状态
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Reconnecting after a failed master event read
Master_Host: 192.168.32.200
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000002
Read_Master_Log_Pos: 445
Relay_Log_File: relay-log.000006
Relay_Log_Pos: 531
Relay_Master_Log_File: mariadb-bin.000002
Slave_IO_Running: Connecting
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 445
Relay_Log_Space: 819
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'repluser@192.168.32.200:3306' - retry-time: 60 retries: 86400 message: Can't connect to MySQL server on '192.168.32.200' (111)
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
1 row in set (0.00 sec)
报错提示无法连接主服务器
在数据库中清除从服务器原有信息
MariaDB [(none)]> stop slave; #要先停止同步
MariaDB [(none)]> reset slave all; #清除从服务器的原有信息
更改配置文件:启用二进制日志,删除中继日志,read_only选项
vim /etc/my.cnf
[mysqld]
server_id=2
log_bin
innodb_file_per_table
skip_name_resolve
重启mariadb服务
systemctl restart mariadb
注意:此时要授权用户从服务器能够从本机同步数据,这是可以使用从原主服务器同步过来的已授权的账号,即repluser
MariaDB [(none)]> select user,host from mysql.user;
+----------+--------------+
| user | host |
+----------+--------------+
| root | 127.0.0.1 |
| repluser | 192.168.32.% |
| root | ::1 |
| | centos7 |
| root | centos7 |
| | localhost |
| root | localhost |
+----------+--------------+
此时,作为主节点的主备工作已经完成
查看并记录位置信息
MariaDB [(none)]> show master status;
+--------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+--------------------+----------+--------------+------------------+
| mariadb-bin.000001 | 245 | | |
+--------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
在slave02节点192.168.32.202上
配置文件无需更改
可以添加read_only选项
[mysqld]
server_id=3
read_only=on #从服务器设为只读,只对普通用户生效
relay_log=relay-log
relay_log_index=relay-log.index
innodb_file_per_table
skip_name_resolve
如果配置文件没有更改,则无需重启服务,如果配置文件有更改则需要重启服务生效
systemctl restart mariadb
把从节点的主节点位置(ip)指向新的主节点
MariaDB [hellodb]> stop slave;
MariaDB [hellodb]> reset slave all;
MariaDB [hellodb]> CHANGE MASTER TO
MASTER_HOST='192.168.32.201',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
MariaDB [hellodb]> start slave;
查看同步状态
MariaDB [hellodb]> show slave status\G
在新的主节点192.168.32.201上插入数据进行测试
在hellodb数据库的teachers表中插入数据
MariaDB [hellodb]> insert hellodb.teachers values(7,'c',35,'F');
在slave02从节点查看teacher表内容
MariaDB [none]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
| 7 | c | 35 | F |
+-----+---------------+-----+--------+
此时,旧的主服务器再次启动后,将不会有从服务器从其同步信息,可以把此主节点变为从节点
更改配置文件,增加中继日志,配置read_only选项,log_bin日志不删除也可以
[mysqld]
server_id=1
innodb_file_per_table
log_bin
read_only=on
relay_log=relay-log
relay_log_index=relay-log.index
innodb_file_per_table
skip_name_resolve
重启服务生效
systemctl restart mariadb
清除主节点原有相关信息
[root@centos7 ~]# mysql
MariaDB [(none)]> reset master;
配置同步指令
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.201',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
启动同步
MariaDB [(none)]> start slave;
查看同步信息
MariaDB [(none)]> show slave status\G
查看同步的数据
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
| 7 | c | 35 | F |
+-----+---------------+-----+--------+- 主从复制:级联复制
用于减轻主服务器的压力
为了分担主服务器的压力,专门设置一个从服务器,主服务器只需向该从服务器写入数据,而该从服务器则用于向其他从服务器写入数据
结构:master --> slave --> slave1,slave2
示例:
实验环境
master主机:192.168.32.201 主节点
slave01主机:192.168.32.200 从节点
slave02主机:192.168.32.202 从节点192.168.32.202下属的从
在中间slave服务器上添加以下选项
vim /etc/my.cnf
[mysqld]
log_bin #启动二进制日志
log_slave_updates
重启mariadb服务生效
systemctl restart mariadb
在主节点192.168.32.201上查看并记录二进制日志位置信息
MariaDB [(none)]> show master status;
+--------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+--------------------+----------+--------------+------------------+
| mariadb-bin.000001 | 245 | | |
+--------------------+----------+--------------+------------------+
在slave02从节点上进行以下配置:
进入数据库进行相关同步配置
[root@centos7 ~]# mysql
MariaDB [(none)]> stop slave;
MariaDB [(none)]> reset slave all;
注意:如果从节点slave02服务器上数据库为空,则需要把主节点服务器的完全备份导入该服务器,把数据同步到与中间服务器slave01一致,然后再配置同步信息,这里数据已经一致,不再配置
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
MariaDB [(none)]> show slave status\G
此时在主服务器192.168.32.201上添加数据,测试同步效果
可以发现中间服务器的数据库发生改变,但是从的从却并没有收到数据进行同步
原因:主服务器添加数据,生成二进制日志,发送给中间服务器,中间服务器拿到二进制日志后在本地执行一次生成数据写入本地数据库;
但二进制日志只有对本地数据库进行直接的增删改操作才会生成,而中间数据库却是通过执行中继日志中的二进制日志进行的数据库更改操作,因此中间服务器并不会把更改操作写入本地二进制日志里,那么从的从slave02也不会同步中间服务器所做的更改
解决方法:
在中间服务器slave01 192.168.32.200上配置文件中添加选项:
[mysqld]
log_slave_updates
重启服务器生效
systemctl restart mariadb
注意:虽然已经添加该选项,但是之前添加的第八条记录将会丢失
测试:再次在主服务器上插入数据进行测试
主服务器192.168.32.201上
MariaDB [(none)]> insert hellodb.teachers values(9,'3',25,'F');
MariaDB [(none)]> insert hellodb.teachers values(10,'f',33,'F');
在从的从节点192.168.32.202上查看同步效果
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
| 7 | c | 35 | M |
| 9 | 3 | 25 | F |
| 10 | f | 33 | F |
+-----+---------------+-----+--------+- 复制架构中应该注意的问题:
1、限制从服务器为只读
在从服务器上设置read_only=ON
注意:此限制对拥有SUPER权限的用户均无效
阻止所有用户, 包括主服务器复制的更新
mysql> FLUSH TABLES WITH READ LOCK;
2、RESET SLAVE
在从服务器清除master.info ,relay-log.info, relay log ,开始新的relay log ,注意:需要先STOP SLAVE
RESET SLAVE ALL 清除所有从服务器上设置的主服务器同步信息如:PORT, HOST, USER和 PASSWORD 等
3、sql_slave_skip_counter = N 从服务器忽略几个主服务器的复制事件,global变量
示例:
以root身份为例:
先在中间从服务器192.168.32.200上添加一条新记录,
insert hellodb.teachers values(11,'g',33,'F');
然后主服务器192.168.32.201上也添加一条新纪录
insert hellodb.teachers values(11,'g',33,'F');
此时主服务器上添加记录的id号与从服务器上添加记录的id号产生冲突,导致从服务器无法从主服务器上同步新产生的记录
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.32.201
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000003
Read_Master_Log_Pos: 1023
Relay_Log_File: relay-log.000004
Relay_Log_Pos: 920
Relay_Master_Log_File: mariadb-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1062
Last_Error: Error 'Duplicate entry '11' for key 'PRIMARY'' on query. Default database: ''. Query: 'insert hellodb.teachers values(11,'g',33,'F')'
Skip_Counter: 0
Exec_Master_Log_Pos: 828
Relay_Log_Space: 1403
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1062
Last_SQL_Error: Error 'Duplicate entry '11' for key 'PRIMARY'' on query. Default database: ''. Query: 'insert hellodb.teachers values(11,'g',33,'F')'
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
1 row in set (0.00 sec
而且主服务器上后续新增的记录也无法复制到从服务器上
在主服务器上再次添加一条新纪录
MariaDB [(none)]> insert hellodb.teachers values(12,'h',36,'F');
Query OK, 1 row affected (0.07 sec)
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
| 7 | c | 35 | M |
| 8 | d | 30 | F |
| 9 | 3 | 25 | F |
| 10 | f | 33 | F |
| 11 | g | 33 | F |
| 12 | h | 36 | F |
+-----+---------------+-----+--------+
在中间从服务器上查看,发现并没有把第12条信息同步过来
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
| 7 | c | 35 | M |
| 8 | d | 30 | F |
| 9 | 3 | 25 | F |
| 10 | f | 33 | F |
| 11 | g | 33 | F |
+-----+---------------+-----+--------+
解决方法:
在从服务器上:
MariaDB [(none)]> stop slave;
MariaDB [(none)]> set global sql_slave_skip_counter = 1 ; #注意1为自定义数值,可以根据需要进行设置
MariaDB [(none)]> start slave;
查看同步状态
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.32.201
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000003
Read_Master_Log_Pos: 1218
Relay_Log_File: relay-log.000005
Relay_Log_Pos: 531
Relay_Master_Log_File: mariadb-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1218
Relay_Log_Space: 1884
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
查看主服务器信息是否同步过来:
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
| 7 | c | 35 | M |
| 8 | d | 30 | F |
| 9 | 3 | 25 | F |
| 10 | f | 33 | F |
| 11 | g | 33 | F |
| 12 | h | 36 | F |
+-----+---------------+-----+--------+
在主服务器192.168.32.201上再次插入新数据进行测试
insert hellodb.teachers values(13,'i',40,'F');
在中间从服务器192.168.32.200上查看同步状态
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
| 7 | c | 35 | M |
| 8 | d | 30 | F |
| 9 | 3 | 25 | F |
| 10 | f | 33 | F |
| 11 | g | 33 | F |
| 12 | h | 36 | F |
| 13 | i | 40 | F |
+-----+---------------+-----+--------+
查看从的从节点192.168.32.202上同步信息状态
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 20 | M |
| 6 | b | 30 | F |
| 7 | c | 35 | M |
| 9 | 3 | 25 | F |
| 10 | f | 33 | F |
| 11 | g | 33 | F |
| 12 | h | 36 | F |
| 13 | i | 40 | F |
+-----+---------------+-----+--------+4、如何保证主从复制的事务安全
参看https://mariadb.com/kb/en/library/server-system-variables/
在master节点启用参数:
sync_binlog=1 每次写后立即同步二进制日志到磁盘,性能差
如果用到的为InnoDB存储引擎:
innodb_flush_log_at_trx_commit=1 每次事务提交立即同步日志写磁盘
innodb_support_xa=ON 默认值,分布式事务MariaDB10.3.0废除
sync_master_info=# #次事件后master.info同步到磁盘
在slave节点启用服务器选项:
skip_slave_start=ON 不自动启动slave
在slave节点启用参数:
sync_relay_log=# #次写后同步relay log到磁盘
sync_relay_log_info=# #次事务后同步relay-log.info到磁盘
主主复制
- 主主复制:互为主从
容易产生的问题:数据不一致;因此慎用
考虑要点:自动增长id
配置一个节点使用奇数id
auto_increment_offset=1 开始点
auto_increment_increment=2 增长幅度
另一个节点使用偶数id
auto_increment_offset=2
auto_increment_increment=2 - 主主复制的配置步骤:
(1) 各节点使用一个惟一server_id
(2) 都启动binary log和relay log
(3) 创建拥有复制权限的用户账号
(4) 定义自动增长id字段的数值范围各为奇偶
(5) 均把对方指定为主节点,并启动复制线程
示例:
实验环境:
master1主机:192.168.32.201
master2主机:192.168.32.200
初始化实验环境:(实验需要,真实环境此步骤可省略)
在两台主机上执行以下命令:
systemctl stop mariadb
rm -rf /var/lib/mysql/*
在主机192.168.32.200上添加以下选项
[root@centos7 ~]# vim /etc/my.cnf
[mysqld]
server_id=1
innodb_file_per_table
log_bin
skip_name_resolve
auto_increment_offset=1
auto_increment_increment=2
启动服务
systemctl start mariadb
在主机192.168.32.201上添加以下选项
[root@centos7 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
log_bin
innodb_file_per_table
skip_name_resolve
auto_increment_offset=2
auto_increment_increment=2
启动服务
systemctl start mariadb
先建立单项主从复制
以192.168.32.200为主
在主机192.168.32.200上
[root@centos7 ~]# mysql
MariaDB [(none)]> show master status;
+--------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+--------------------+----------+--------------+------------------+
| mariadb-bin.000001 | 245 | | |
+--------------------+----------+--------------+------------------+
MariaDB [(none)]> grant replication slave on *.* to 'repluser'@'192.168.32.%' identified by 'centos';
在主机192.168.32.201主机上
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.32.200
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000001
Read_Master_Log_Pos: 407
Relay_Log_File: mariadb-relay-bin.000002
Relay_Log_Pos: 693
Relay_Master_Log_File: mariadb-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 407
Relay_Log_Space: 989
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
此时,单项主从已经建立,只需要再次建立以192.168.32.201为主的主从关系即可
由于授权账户已经同步过来,而且配置文件已经准备完毕,因此只需在192.168.32.200主机数据库中建立以192.168.32.201为主的同步信息即可
在主机192.168.32.200主机上
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.201',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.32.201
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000001
Read_Master_Log_Pos: 245
Relay_Log_File: mariadb-relay-bin.000002
Relay_Log_Pos: 531
Relay_Master_Log_File: mariadb-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 245
Relay_Log_Space: 827
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
此时,主主复制已经成功建立
建立新表进行测试:
导入测试数据库
[root@centos7 ~]# mysql < hellodb_innodb.sql
在数据库中建立新表
MariaDB [(none)]> use hellodb
MariaDB [hellodb]> create table test (id int auto_increment primary key,name char(20));
插入数据进行测试:
在主机192.168.32.200上插入数据,以奇数递增
MariaDB [hellodb]> insert test (name)values('a'),('b');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
MariaDB [hellodb]> select * from test;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 3 | b |
+----+------+
2 rows in set (0.00 sec)
在主机192.168.32.201上插入数据,以偶数递增
MariaDB [hellodb]> insert test (name)values('c'),('d');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
MariaDB [hellodb]> select * from test;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 3 | b |
| 4 | c |
| 6 | d |
+----+------+
4 rows in set (0.00 sec)
这样一来就避免了id的相互冲突半同步复制
- 默认情况下,MySQL的复制功能是异步的,异步复制可以提供最佳的性能,主库把binlog日志发送给从库即结束,并不验证从库是否接收完毕。这意味着当主服务器或从服务器端发生故障时,有可能从服务器没有接收到主服务器发送过来的binlog日志,这就会造成主服务器和从服务器的数据不一致,甚至在恢复时造成数据的丢失
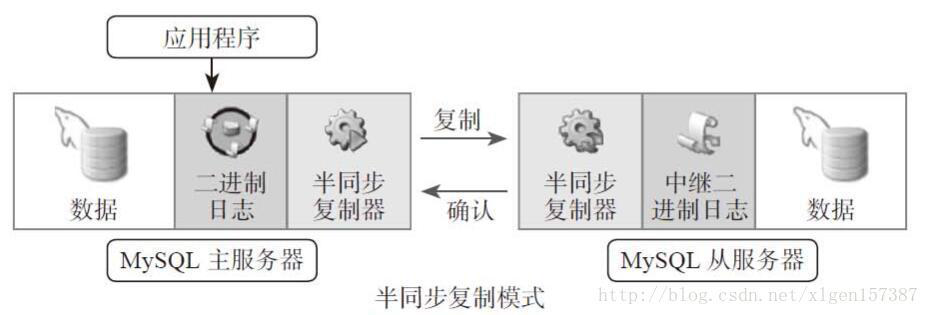
- 半同步复制实现:
配置步骤如下:
主服务器配置:
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql>SET GLOBAL rpl_semi_sync_master_enabled=1;
mysql>SET GLOBAL rpl_semi_sync_master_timeout = 1000;超时长为1s
mysql>SHOW GLOBAL VARIABLES LIKE '%semi%';
mysql>SHOW GLOBAL STATUS LIKE '%semi%‘;
从服务器配置:
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> SET GLOBAL rpl_semi_sync_slave_enabled=1; 示例:
实验环境:一主两从
master主机:192.168.32.200
slave01主机:192.168.32.201
slave02主机:192.168.32.202
初始化环境:
停止mariadb服务
systemctl stop mariadb
删除库文件
rm -rf /var/lib/mysql/*
准备配置文件,配置主从同步
主服务器192.168.32.200
[root@centos7 ~]# vim /etc/my.cnf
[mysqld]
server_id=1
innodb_file_per_table
log_bin
skip_name_resolve
启动mariadb服务
systemctl start mariadb
创建授权账号
MariaDB [(none)]> mysql
MariaDB [(none)]> show master logs;
+--------------------+-----------+
| Log_name | File_size |
+--------------------+-----------+
| mariadb-bin.000001 | 402 |
+--------------------+-----------+
MariaDB [(none)]> grant replication slave on *.* to 'repluser'@'192.168.32.%' identified by 'centos';
从服务器slave01 192.168.32.201
[root@centos7 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
innodb_file_per_table
skip_name_resolve
启动mariadb服务
systemctl start mariadb
配置从服务器同步信息
[root@centos7 ~]# mysql
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G
从服务器slave01 192.168.32.202
[root@centos7 ~]# vim /etc/my.cnf
[mysqld]
server_id=3
innodb_file_per_table
skip_name_resolve
启动mariadb服务
systemctl start mariadb
配置从服务器同步信息
[root@centos7 ~]# mysql
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G
配置半同步复制
在mysql数据库中执行以下命令查看已存在的插件
show plugins 查看已安装的插件
主服务器192.168.32.200上配置:
MariaDB [(none)]> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
#安装主服务器半同步复制插件
MariaDB [(none)]> SET GLOBAL rpl_semi_sync_master_enabled=1;
#注意:在生产环境中要把rpl_semi_sync_master_enabled=1写入/etc/my.cnf配置文件后重启服务才能永久生效,建议写入配置文件
MariaDB [(none)]> SET GLOBAL rpl_semi_sync_master_timeout = 1000;
#设置超时时长
MariaDB [(none)]> SHOW GLOBAL VARIABLES LIKE '%semi%';
#查看半同步复制相关变量
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE '%semi%';
#查看和半同步相关的状态变量
从服务器192.168.32.201和192.168.32.202上进行以下配置:
MariaDB [(none)]> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
#安装从服务器半同步复制插件
MariaDB [(none)]> SET GLOBAL rpl_semi_sync_slave_enabled=1;
#注意:在生产环境中要把rpl_semi_sync_master_enabled=1写入/etc/my.cnf配置文件后重启服务才能永久生效,建议写入配置文件
注意:此时,需要重启从服务器的两个同步线程
MariaDB [(none)]> stop slave;
MariaDB [(none)]> start slave;
查看插件是否启用
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE '%semi%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
测试:是否能够同步
导入测试数据库
[root@centos7 ~]# mysql < hellodb_innodb.sql
[root@centos7 ~]# mysql
MariaDB [(none)]> use hellodb
MariaDB [hellodb]> insert teachers values(5,'a',30,'M');
在从服务器192.168.32.201上查看同步状态
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 30 | M |
+-----+---------------+-----+--------+
验证半同步:
1.同步成功
2.等待超时
关闭从服务器slave01,等待一个超时时长
在从服务器slave01 192.168.32.201上
systemctl stop mariadb
在主服务器192.168.32.200上插入新的数据进行测试
MariaDB [hellodb]> insert teachers values(6,'b',30,'F');
Query OK, 1 row affected (1.00 sec)
注意:可以看到等待时间为1秒,1秒就是之前设置过的超时时长,即SET GLOBAL rpl_semi_sync_master_timeout = 1000;该时间单位默认为毫秒。另外,超时时长默认为10s,可以通过该选项进行设置
在从服务器上,重启mariadb服务,发现数据会继续同步到从服务器上
[root@centos7 ~]# systemctl start mariadb
[root@centos7 ~]# mysql
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 30 | M |
| 6 | b | 30 | F |
+-----+---------------+-----+--------+
注意:由于重启mariadb服务,因此半同步插件状态会变为OFF状态,因此需要重新启用半同步插件,即SET GLOBAL rpl_semi_sync_slave_enabled=1
在主服务器上查看半同步插件状态
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE '%semi%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 2 |
| Rpl_semi_sync_master_net_avg_wait_time | 493 |
| Rpl_semi_sync_master_net_wait_time | 18247 |
| Rpl_semi_sync_master_net_waits | 37 |
| Rpl_semi_sync_master_no_times | 1 |
| Rpl_semi_sync_master_no_tx | 1 |
| Rpl_semi_sync_master_status | ON |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 656 |
| Rpl_semi_sync_master_tx_wait_time | 21015 |
| Rpl_semi_sync_master_tx_waits | 32 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 36 |
+--------------------------------------------+-------+
注意:此时两个从服务器已经同步成功,即使其中一台服务器出现故障,主服务器同步也会立即返回同步成功,如果两台从服务器都出现故障,主服务器将会在一个超时时长之后返回同步成功
在生产中,可以把一主多从和半同步结合起来
即master ---> slave(半同步) ---> slave1,slave2,slave3- 复制过滤器:
让从节点仅复制指定的数据库,或指定数据库的指定表 - 两种实现方式:
(1) 服务器选项:主服务器仅向二进制日志中记录与特定数据库相关的事件
注意:此项和binlog_format相关
参看:https://mariadb.com/kb/en/library/mysqld-options/#-binlog-ignore-db
binlog_do_db = 数据库白名单列表,多个数据库需多行实现
binlog_ignore_db = 数据库黑名单列表
问题:基于二进制还原将无法实现;不建议使用
(2) 从服务器SQL_THREAD在replay中继日志中的事件时,仅读取与特定数据库(特定表)相关的事件并应用于本地
问题:会造成网络及磁盘IO浪费 - 从服务器上的复制过滤器相关变量
replicate_do_db= 指定复制库的白名单
replicate_ignore_db= 指定复制库黑名单
replicate_do_table= 指定复制表的白名单
replicate_ignore_table= 指定复制表的黑名单
replicate_wild_do_table= foo%.bar% 支持通配符
replicate_wild_ignore_table=
示例:
实验环境:半同步复制,一主两从
master主机:192.168.32.200
slave01主机:192.168.32.201
slave02主机:192.168.32.202
在主服务器192.168.32.200中test数据库中创建新表t1,并插入数据用于测试
MariaDB [(none)]> use test
MariaDB [test]> create table ta(id int);
MariaDB [test]> insert t1 values(1);
MariaDB [test]> select * from t1;
+------+
| id |
+------+
| 1 |
+------+
在从服务器192.168.32.201和192.168.32.202上设置复制库的白名单
MariaDB [(none)]> stop slave;
MariaDB [(none)]> set global replicate_do_db=hellodb;
MariaDB [(none)]> start slave;
MariaDB [(none)]> show variables like 'replicate_do_db';
+-----------------+---------+
| Variable_name | Value |
+-----------------+---------+
| replicate_do_db | hellodb |
+-----------------+---------+
注意:此时白名单为hellodb,说明只复制hellodb数据库的更改,不复制其他数据库的更改
测试:
在主服务器192.168.32.200上hellodb数据库teachers表中插入数据
MariaDB [hellodb]> use hellodb #注意设置数据库白名单以后,必须要先切换到该数据库以后插入数据才可以同步到从服务器,否则修改的信息将不会被复制到从服务器,如数据库白名单为hellodb,则必须先切换到hellodb数据库,然后才能插入新数据
MariaDB [hellodb]> insert hellodb.teachers values(8,'d',25,'M');
在从服务器上查看是否能够同步
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 30 | M |
| 6 | b | 30 | F |
| 7 | c | 25 | M |
+-----+---------------+-----+--------+
在主服务器192.168.32.200上test数据库t1表中插入数据
MariaDB [test]> use test; #注意要先切换数据库,才能插入数据
MariaDB [test]> insert t1 values(3);
在从服务器上查看是否同步,发现第三条信息并没有同步过来,说明设置生效
MariaDB [(none)]> select * from test.t1;
+------+
| id |
+------+
| 1 |
| 2 |
+------+MySQL复制加密
- 基于SSL复制:
在默认的主从复制过程或远程连接到MySQL/MariaDB所有的链接通信中的数据都是明文的,外网里访问数据或则复制,存在安全隐患。通过SSL/TLS加密的方式进行复制的方法,来进一步提高数据的安全性 - 配置实现:
参看:https://mariadb.com/kb/en/library/replication-with-secure-connections/
主服务器开启SSL:[mysqld] 加一行ssl
主服务器配置证书和私钥;并且创建一个要求必须使用SSL连接的复制账号
从服务器使用CHANGER MASTER TO 命令时指明ssl相关选项
具体配置信息:
Master服务器配置
[mysqld]
log-bin
server_id=1
ssl
ssl-ca=/etc/my.cnf.d/ssl/cacert.pem
ssl-cert=/etc/my.cnf.d/ssl/master.crt
ssl-key=/etc/my.cnf.d/ssl/master.key
Slave服务器配置
mysql>
CHANGE MASTER TO
MASTER_HOST='MASTERIP',
MASTER_USER='rep',
MASTER_PASSWORD='centos',
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245,
MASTER_SSL=1,
MASTER_SSL_CA = '/etc/my.cnf.d/ssl/cacert.pem',
MASTER_SSL_CERT = '/etc/my.cnf.d/ssl/slave.crt',
MASTER_SSL_KEY = '/etc/my.cnf.d/ssl/slave.key';示例:
初始化实验环境(这里做实验需要此设置,实际中无需此步骤)
主服务器192.168.32.200
在配置文件中中删除binlog_do_db=hellodb选项
重启服务
systemctl restart mariadb
实验环境:这里以一主一从为例
master主机:192.168.32.200
slave主机:192.168.32.201
CA主机:192.168.32.202
一般情况下,需要CA主机生成自签名证书,主从服务器生成私钥和证书申请,然后传递给CA主机,CA主机根据其私钥和证书申请颁发证书给主从服务器
这里为了方便实验,在CA主机生成私钥和证书直接传递给主从服务器使用即可
生成证书:
创建存放证书的目录
mkdir -p /etc/my.cnf.d/ssl
创建CA的私钥和自签名证书
cd /etc/my.cnf.d/ssl
[root@slave02 ssl]# openssl genrsa 2048 > cakey.pem
[root@slave02 ssl]# openssl req -new -x509 -key cakey.pem -out cacert.pem -days 3650
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:beijing
Locality Name (eg, city) [Default City]:beijing
Organization Name (eg, company) [Default Company Ltd]:magedu
Organizational Unit Name (eg, section) []:opt
Common Name (eg, your name or your server's hostname) []:ca.magedu.com
Email Address []:
创建主服务器的私钥和证书
生成主服务器私钥并创建证书申请
[root@slave02 ssl]# req -newkey rsa:1024 -days 100 -nodes -keyout master.key > master.csr
Generating a 1024 bit RSA private key
..............................++++++
......++++++
writing new private key to 'master.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:beijing
Locality Name (eg, city) [Default City]:beijing
Organization Name (eg, company) [Default Company Ltd]:magedu
Organizational Unit Name (eg, section) []:opt
Common Name (eg, your name or your server's hostname) []:master.magedu.com
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
颁发主服务器证书
[root@slave02 ssl]# openssl x509 -req -in master.csr -days 100 -CA cacert.pem -CAkey cakey.pem -set_serial 01 > master.crt
Signature ok
subject=/C=CN/ST=beijing/L=beijing/O=magedu/OU=opt/CN=master.magedu.com
Getting CA Private Key
创建从服务器的私钥和证书
生成从服务器私钥并创建证书申请
[root@slave02 ssl]# openssl req -newkey rsa:1024 -days 100 -nodes -keyout slave.key > slave.csr
Generating a 1024 bit RSA private key
............++++++
.++++++
writing new private key to 'slave.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:beijing
Locality Name (eg, city) [Default City]:beijing
Organization Name (eg, company) [Default Company Ltd]:magedu
Organizational Unit Name (eg, section) []:opt
Common Name (eg, your name or your server's hostname) []:slave.magedu.com
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
颁发从服务器证书
[root@slave02 ssl]# openssl x509 -req -in slave.csr -days 100 -CA cacert.pem -CAkey cakey.pem -set_serial 02 > slave.crt
Signature ok
subject=/C=CN/ST=beijing/L=beijing/O=magedu/OU=opt/CN=slave.magedu.com
Getting CA Private Key
查看所有证书文件
[root@slave02 ssl]# ll
total 32
-rw-r--r-- 1 root root 1322 Dec 25 15:25 cacert.pem
-rw-r--r-- 1 root root 1675 Dec 25 15:24 cakey.pem
-rw-r--r-- 1 root root 1021 Dec 25 15:35 master.crt
-rw-r--r-- 1 root root 655 Dec 25 15:30 master.csr
-rw-r--r-- 1 root root 912 Dec 25 15:30 master.key
-rw-r--r-- 1 root root 1017 Dec 25 15:38 slave.crt
-rw-r--r-- 1 root root 655 Dec 25 15:37 slave.csr
-rw-r--r-- 1 root root 916 Dec 25 15:37 slave.key
把主从复制加密所需的证书复制到对应服务器上即可
注意:在主从服务器上创建对应的存放证书的目录,即/etc/my.cnf.d/ssl
scp cacert.pem master.crt master.key 192.168.32.200:/etc/my.cnf.d/ssl/
scp cacert.pem slave.crt slave.key 192.168.32.201:/etc/my.cnf.d/ssl/
主从服务器配置:
主服务器配置文件添加以下几项:
vim /etc/my.cnf
[mysqld]
ssl
ssl-ca=/etc/my.cnf.d/ssl/cacert.pem
ssl-cert=/etc/my.cnf.d/ssl/master.crt
ssl-key=/etc/my.cnf.d/ssl/master.key
重启服务生效
systemctl restart mariadb
进入数据库查看相关变量是否已经启用
[root@centos7 ~]# mysql
MariaDB [(none)]> show variables like '%ssl%';
+---------------+------------------------------+
| Variable_name | Value |
+---------------+------------------------------+
| have_openssl | YES |
| have_ssl | YES |
| ssl_ca | /etc/my.cnf.d/ssl/cacert.pem |
| ssl_capath | |
| ssl_cert | /etc/my.cnf.d/ssl/master.crt |
| ssl_cipher | |
| ssl_key | /etc/my.cnf.d/ssl/master.key |
+---------------+------------------------------+
创建强制加密的账号
MariaDB [(none)]> grant replication slave on *.* to 'ssluser'@'192.168.32.%' identified by 'centos' require ssl;
注意:由于主从复制仍然存在,因此该账号会被同步到从服务器上
查看并记录二进制日志位置
MariaDB [(none)]> show master logs;
+--------------------+-----------+
| Log_name | File_size |
+--------------------+-----------+
| mariadb-bin.000001 | 10832 |
| mariadb-bin.000002 | 464 |
| mariadb-bin.000003 | 264 |
| mariadb-bin.000004 | 413 |
+--------------------+-----------+
测试:通过加密账号同步数据
在从服务器192.168.32.201上进行测试,通过证书连接主服务器数据库
cd /etc/my.cnf.d/ssl
mysql --ssl-ca=cacert.pem --ssl-cert=slave.crt --ssl-key=slave.key -ussluser -pcentos -h192.168.32.200
注意:ssluser如果不使用证书则无法连接主服务器数据库,说明该账号必须强制加密连接
从服务器配置:
进入数据库进行同步相关配置
[root@centos7 ssl]# mysql
MariaDB [(none)]> stop slave;
MariaDB [(none)]> reset slave all;
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='ssluser',
MASTER_PASSWORD='centos',
MASTER_LOG_FILE='mariadb-bin.000004',
MASTER_LOG_POS=413,
MASTER_SSL=1,
MASTER_SSL_CA = '/etc/my.cnf.d/ssl/cacert.pem',
MASTER_SSL_CERT = '/etc/my.cnf.d/ssl/slave.crt',
MASTER_SSL_KEY = '/etc/my.cnf.d/ssl/slave.key';
MariaDB [(none)]> start slave;
查看同步状态信息
MariaDB [(none)]> show slave status\G
测试:在主服务器插入数据,并使用抓包工具抓包测试能否抓取到相关内容
MariaDB [(none)]> use test
MariaDB [test]> insert t1 values(5);复制的监控和维护
- (1) 清理日志
PURGE { BINARY | MASTER } LOGS { TO 'log_name' | BEFORE datetime_expr }
RESET MASTER
RESET SLAVE - (2) 复制监控
SHOW MASTER STATUS
SHOW BINLOG EVENTS
SHOW BINARY LOGS
SHOW SLAVE STATUS
SHOW PROCESSLIST - (3) 从服务器是否落后于主服务
Seconds_Behind_Master: 0 - (4) 如何确定主从节点数据是否一致
percona-tools - (5) 数据不一致如何修复
删除从数据库,重新复制
13、MySQL读写分离
使用Proxysql实现mysql读写分离
具体实验步骤如下:
- 思路:先配置完成主从复制,在读写分离节点配置Proxysql
- 实验环境:
读写分离节点:192.168.32.203
master主机:192.168.32.200
slave01主机:192.168.32.201
slave02:192.168.32.202
示例:
主从复制配置:
主节点配置:
master主机:192.168.32.200配置:
更改mysql配置文件
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
innodb_file_per_table
skip_name_resolve
server_id=1
log_bin
启动mysql服务
systemctl start mariadb
授权从节点能够访问主节点
MariaDB [(none)]> grant replication slave on *.* to 'repluser'@'192.168.32.%' identified by 'centos';
查看主节点日志位置
MariaDB [(none)]> show master status;
+--------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+--------------------+----------+--------------+------------------+
| mariadb-bin.000001 | 402 | | |
+--------------------+----------+--------------+------------------+
slave01主机:192.168.32.201配置:
更改配置文件
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
innodb_file_per_table
skip_name_resolve
server_id=2
relay_log=relay_log
relay_log_index=relay-log.index
指定从节点的主节点位置和日志信息
CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=402;
启动主从复制并查看主从复制创泰
start slave;
show slave status\G
slave02主机:192.168.32.202配置:
更改配置文件
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
innodb_file_per_table
skip_name_resolve
server_id=3 #注意server_id必须唯一
relay_log=relay_log
relay_log_index=relay-log.index
指定从节点的主节点位置和日志信息
CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='repluser',
MASTER_PASSWORD='centos',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=402;
启动主从复制并查看主从复制创泰
start slave;
show slave status\G读写分离节点配置
读写分离节点:192.168.32.203配置:
思路:配置读写分离,主节点只负责写操作,读操作全部调度到从节点上
注意:在配置前一定要在从节点配置文件中添加read-only选项,否则
proxysql节点无法判断该节点充当的角色
从节点192.16.32.201
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
innodb_file_per_table
skip_name_resolve
server_id=2 #注意server_id必须唯一
relay_log=relay_log
relay_log_index=relay-log.index
read-only #注意读写分离时从节点必须添加该选项
从节点192.16.32.202
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
innodb_file_per_table
skip_name_resolve
server_id=3 #注意server_id必须唯一
relay_log=relay_log
relay_log_index=relay-log.index
read-only #注意读写分离时从节点必须添加该选项
proxysql的安装:
使用官方提供的yum源直接安装即可
vim /etc/yum.repos.d/proxysql.repo
[proxysql_repo]
name= ProxySQL YUM repository
baseurl=http://repo.proxysql.com/ProxySQL/proxysql-1.4.x/centos/\$releasever
gpgcheck=1
gpgkey=http://repo.proxysql.com/ProxySQL/repo_pub_key
使用yum安装proxysql
yum -y install proxysql
启动服务
service proxysql start
默认监听端口
6032 proxysql的配置端口
6033:ProxySQL对外提供服务的端口
使用mysql客户端连接到ProxySQL的管理接口6032,默认管理员用户和密码都是admin:
mysql -uadmin -padmin -P6032 -h127.0.0.1
MySQL [(none)]> status #查看连接状态信息
--------------
mysql Ver 15.1 Distrib 5.5.60-MariaDB, for Linux (x86_64) using readline 5.1
Connection id: 1
Current database: admin
Current user: admin
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server: MySQL
Server version: 5.5.30 (ProxySQL Admin Module)
Protocol version: 10
Connection: 127.0.0.1 via TCP/IP
Server characterset: utf8
Db characterset: utf8
Client characterset: utf8
Conn. characterset: utf8
TCP port: 6032
Uptime: 12 min 15 sec
查看数据库信息
MySQL [(none)]> show databases;
+-----+---------------+-------------------------------------+
| seq | name | file |
+-----+---------------+-------------------------------------+
| 0 | main | |
| 2 | disk | /var/lib/proxysql/proxysql.db |
| 3 | stats | |
| 4 | monitor | |
| 5 | stats_history | /var/lib/proxysql/proxysql_stats.db |
+-----+---------------+-------------------------------------+
5 rows in set (0.00 sec)
MySQL [(none)]> use main;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MySQL [main]> show tables;
+--------------------------------------------+
| tables |
+--------------------------------------------+
| global_variables |
| mysql_collations |
| mysql_group_replication_hostgroups |
| mysql_query_rules |
| mysql_query_rules_fast_routing |
| mysql_replication_hostgroups |
| mysql_servers |
| mysql_users |
| proxysql_servers |
| runtime_checksums_values |
| runtime_global_variables |
| runtime_mysql_group_replication_hostgroups |
| runtime_mysql_query_rules |
| runtime_mysql_query_rules_fast_routing |
| runtime_mysql_replication_hostgroups |
| runtime_mysql_servers |
| runtime_mysql_users |
| runtime_proxysql_servers |
| runtime_scheduler |
| scheduler |
+--------------------------------------------+
20 rows in set (0.00 sec)
说明:在main和monitor数据库中的表, runtime_开头的是运行时的配置,不能修改,只能修改非runtime_表,修改后必须执行LOAD (数据库名) TO RUNTIME才能加载到RUNTIME生效,执行save (数据库名) to disk将配置持久化保存到磁盘
为了让proxysql能够调度三台主从节点服务器,需要把三台主从节点的ip地址加入proxysql的mysql_servers表中
MySQL > select * from mysql_servers; #查看表的内容,为空
MySQL > insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.32.200',3306);
MySQL > insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.32.201',3306);
MySQL > insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.32.202',3306); #hostgroup_id是指把服务器进行分组,分为读组和写组便于区分主节点和从节点进行读写调度;如果没有进行分组,则会根据从节点配置文件中的read-only选项来判断主从节点进行读写调度
MySQL [main]> select * from mysql_servers\G #查看表的内容
*************************** 1. row ***************************
hostgroup_id: 10
hostname: 192.168.32.200
port: 3306
status: ONLINE #online说明加入成功
weight: 1
compression: 0
max_connections: 1000
max_replication_lag: 0
use_ssl: 0
max_latency_ms: 0
comment:
*************************** 2. row ***************************
hostgroup_id: 10
hostname: 192.168.32.201
port: 3306
status: ONLINE
weight: 1
compression: 0
max_connections: 1000
max_replication_lag: 0
use_ssl: 0
max_latency_ms: 0
comment:
*************************** 3. row ***************************
hostgroup_id: 10
hostname: 192.168.32.202
port: 3306
status: ONLINE
weight: 1
compression: 0
max_connections: 1000
max_replication_lag: 0
use_ssl: 0
max_latency_ms: 0
comment:
3 rows in set (0.00 sec)
MySQL > load mysql servers to runtime; #注意表名中不带下划线
MySQL > save mysql servers to disk; #保存到硬盘
添加监控后端节点的用户。ProxySQL通过每个节点的read_only值来自动调整它们是属于读组还是写组
在master节点192.168.32.200上执行:
mysql> grant replication client on *.* to monitor@'192.168.32.%' identified by 'centos'; #由于做了主从复制,因此该账号会自动被复制到从节点上
在ProxySQL节点192.168.32.203上配置监控
MySQL [(none)]> set mysql-monitor_username='monitor'; #如果为监控账号为自定义账号,则需要更改此选项,因为默认监控账号即为monitor,如果监控账号为monitor,则无需修改
MySQL [(none)]> set mysql-monitor_password='centos'; #更改监控账号的密码,该选项来自于main数据库的global_variables表,该表中的该账号的默认密码为monitor,因此要更改该密码为自定义密码
加载到RUNTIME,并保存到disk
MySQL [(none)]> load mysql variables to runtime;
MySQL [(none)]> save mysql variables to disk;
监控模块的指标保存在monitor库的log表中
查看监控连接是否正常的 (对connect指标的监控):(如果connect_error的结果为NULL则表示正常)
MySQL [(none)]> select * from mysql_server_connect_log;
查看监控心跳信息 (对ping指标的监控):
MySQL [(none)]> select * from mysql_server_ping_log;
查看read_only和replication_lag的监控日志
MySQL [(none)]> select * from mysql_server_read_only_log;
MySQL [(none)]> select * from mysql_server_replication_lag_log;
设置分组信息
需要修改的是main库中的mysql_replication_hostgroups表,该表有3个字段:writer_hostgroup,reader_hostgroup,comment, 指定写组的id为10,读组的id为20
MySQL [(none)]> insert into mysql_replication_hostgroups values(10,20,"test");
将mysql_replication_hostgroups表的修改加载到RUNTIME生效
MySQL [(none)]> load mysql servers to runtime;
MySQL [(none)]> save mysql servers to disk;
Monitor模块监控后端的read_only值,按照read_only的值将节点自动移动到读/写组
MySQL [(none)]> select hostgroup_id,hostname,port,status,weight from mysql_servers;
+--------------+----------------+------+--------+--------+
| hostgroup_id | hostname | port | status | weight |
+--------------+----------------+------+--------+--------+
| 10 | 192.168.32.200 | 3306 | ONLINE | 1 |
| 20 | 192.168.32.201 | 3306 | ONLINE | 1 |
| 20 | 192.168.32.202 | 3306 | ONLINE | 1 |
+--------------+----------------+------+--------+--------+
上表中,可以看到已经自动进行分组,从节点201和202为从节点负责读操作,200为主节点负责写操作
配置发送SQL语句的用户
在master主节点上创建访问数据库的用户
grant all on *.* to sqluser@'192.168.32.%' identified by 'centos'; #由于配置了主从复制,在从节点也存在该账户
在ProxySQL读写分离节点192.168.32.203上进行配置,将用户sqluser添加到mysql_users表中,监控该用户,对该用户的访问进行读写调度。default_hostgroup默认组设置为写组10,当读写分离的路由规则不符合时,会访问默认组的数据库,即主节点
insert into mysql_users(username,password,default_hostgroup) values('sqluser','centos',10);
load mysql users to runtime;
save mysql users to disk;
使用sqluser用户测试是否能路由到默认的10写组实现读、写数据
注意:此时要另外打开一个窗口进行数据库连接测试,防止与使用mysql -uadmin -padmin -P6032 -h127.0.0.1命令连接的数据库进行的相关操作混淆
mysql -usqluser -pcentos -P6033 -h127.0.0.1 #测试连接数据库
MySQL [(none)]> select @@server_id; #查看mysql服务器的server_id
+-------------+
| @@server_id |
+-------------+
| 1 |
+-------------+
注意:此时对数据库做的操作都是在master节点上进行,因此还需要定义调度策略
创建测试数据库和表查看效果
MySQL [(none)]> use testdb;
MySQL [testdb]> create table t(id int);
配置路由调度规则,实现读写分离
在读写分离节点192.168.32.203上配置,注意:此时要在mysql -uadmin -padmin -P6032 -h127.0.0.1命令连接的窗口进行配置
与规则有关的表:mysql_query_rules和mysql_query_rules_fast_routing,后者是前者的扩展表,1.4.7之后支持
插入路由规则:将select语句分离到20的读组,select语句中有一个特殊语句SELECT...FOR UPDATE它会申请写锁,应路由到10的写组
insert into mysql_query_rules
(rule_id,active,match_digest,destination_hostgroup,apply)VALUES
(1,1,'^SELECT.*FOR UPDATE$',10,1),(2,1,'^SELECT',20,1); #注意:SELECT.*FOR UPDATE虽然以select命令开头,但属于写操作,属于分组10。其他以select开头的命令都属于读(查询)操作,因此属于分组20。
load mysql query rules to runtime;
save mysql query rules to disk;
注意:因ProxySQL根据rule_id顺序进行规则匹配,select ... for update规则的rule_id必须要小于普通的select规则的rule_id
查看路由规则表
MySQL [(none)]> select * from mysql_query_rules\G验证
测试读操作是否路由给20的读组,server_id为2或3,说明在从节点,也就是读组。
[root@centos7 ~]# mysql -usqluser -pcentos -P6033 -h127.0.0.1 -e 'select @@server_id'
+-------------+
| @@server_id |
+-------------+
| 2 |
+-------------+
[root@centos7 ~]# mysql -usqluser -pcentos -P6033 -h127.0.0.1 -e 'select @@server_id'
+-------------+
| @@server_id |
+-------------+
| 3 |
+-------------+
测试写操作,以事务方式进行测试,server_id为1,说明在主节点,也就是写组
[root@centos7 ~]# mysql -usqluser -pcentos -P6033 -h127.0.0.1 -e 'begin;select @@server_id;commit;'
+-------------+
| @@server_id |
+-------------+
| 1 |
+-------------+
mysql -usqluser -pcentos -P6033 -h127.0.0.1 -e 'insert testdb.t values (1)'
mysql -usqluser -pcentos -P6033 -h127.0.0.1 -e 'select id from testdb.t'
路由的信息:查询stats库中的stats_mysql_query_digest表
SELECT hostgroup hg,sum_time, count_star, digest_text FROM stats_mysql_query_digest ORDER BY sum_time DESC;14、MySQL集群
MySQL高可用
- MMM: Multi-Master Replication Manager for MySQL,Mysql主主复制管理器是一套灵活的脚本程序,基于perl实现,用来对mysql replication进行监控和故障迁移,并能管理mysql Master-Master复制的配置(同一时间只有一个节点是可写的)
官网: http://www.mysql-mmm.org
https://code.google.com/archive/p/mysql-master-master/downloads - MHA: Master High Availability,对主节点进行监控,可实现自动故障转移至其它从节点;通过提升某一从节点为新的主节点,基于主从复制实现,还需要客户端配合实现,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,出于机器成本的考虑,淘宝进行了改造,目前淘宝TMHA已经支持一主一从
官网:https://code.google.com/archive/p/mysql-master-ha/ - Galera Cluster:wsrep(MySQL extended with the Write Set Replication)
通过wsrep协议在全局实现复制;任何一节点都可读写,不需要主从复制,实现多主读写
MHA集群架构
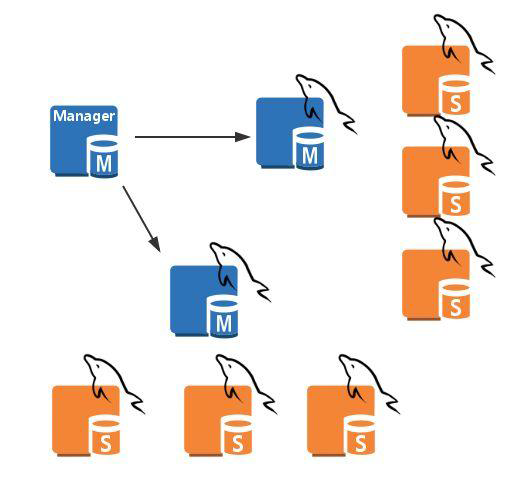
- MHA
MHA工作原理
- MHA工作原理
1 从宕机崩溃的master保存二进制日志事件(binlog events)
2 识别含有最新更新的slave
3 应用差异的中继日志(relay log)到其他的slave
4 应用从master保存的二进制日志事件(binlog events)
5 提升一个slave为新的master
6 使其他的slave连接新的master进行复制
MHA
- MHA软件由两部分组成,Manager工具包和Node工具包
- Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 故障转移(自动或手动)
masterha_conf_host 添加或删除配置的server信息 - Node工具包:这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用此工具)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
注意:为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL 5.5的半同步复制 - 自定义扩展:
secondary_check_script: 通过多条网络路由检测master的可用性
master_ip_ailover_script: 更新Application使用的masterip
shutdown_script: 强制关闭master节点
report_script: 发送报告
init_conf_load_script: 加载初始配置参数
master_ip_online_change_script:更新master节点ip地址 - 配置文件:
global配置,为各application提供默认配置
application配置:为每个主从复制集群
实现MHA
- 在管理节点上安装两个包:
mha4mysql-manager
mha4mysql-node - 在被管理节点安装:
mha4mysql-node
注意:软件包需要在互联网下载
示例:
实验环境
需要四台机器:管理节点,一主两从
管理节点:192.168.32.203
master主机:192.168.32.200
slave01主机:192.168.32.201
slave02:192.168.32.202
初始化环境:
主从服务器停止mariadb服务,删除数据库,启动mariadb服务
关闭selinux,关闭iptables防火墙
时间必须同步
实现免密钥认证
在管理节点192.168.32.203上
生成密钥文件
ssh-keygen
接下来的选项直接确认即可,即连续按三下enter键
把密钥文件复制到本机
ssh-copy-id 192.168.32.203
查看生成的文件
cd .ssh
[root@ma .ssh]# ll
total 16
-rw------- 1 root root 389 Dec 25 20:48 authorized_keys
-rw------- 1 root root 1675 Dec 25 20:47 id_rsa
-rw-r--r-- 1 root root 389 Dec 25 20:47 id_rsa.pub
-rw-r--r--. 1 root root 352 Dec 25 20:48 known_hosts
把/root/.ssh文件复制给其他三个节点即可实现免密钥认证
scp -rp /root/.ssh 192.168.32.200:/root/
scp -rp /root/.ssh 192.168.32.201:/root/
scp -rp /root/.ssh 192.168.32.202:/root/
准备主从复制的配置文件
主服务器配置文件:
vim /etc/my.cnf
[mysqld]
server_id=1
innodb_file_per_table
log_bin
skip_name_resolve #注意:该选项必须添加,否则MHA可能会失败
重启mariadb服务
systemctl restart mariadb
创建复制账号
[root@master ~]# mysql
MariaDB [(none)]> grant replication slave on *.* to repluser@'192.168.32.%' identified by 'magedu';
创建管理账号
MariaDB [(none)]> grant all on *.* to mhauser@'192.168.32.%' identified by 'magedu';
从服务器192.168.32.201配置文件:
vim /etc/my.cnf
[mysqld]
server_id=2
innodb_file_per_table
log_bin #从节点有可能被提升为主节点,因此必须启用二进制日志
read_only #一旦从节点被提升为主节点,将会自动更改只读为可读写状态,因此该选项可以添加到从服务器配置文件中
relay_log_purge=0 #中继日志
skip_name_resolve
重启mariadb服务
systemctl restart mariadb
从服务器192.168.32.202配置文件:
vim /etc/my.cnf
[mysqld]
server_id=3
innodb_file_per_table
log_bin #从节点有可能被提升为主节点,因此必须启用二进制日志
read_only #一旦从节点被提升为主节点,将会自动更改只读为可读写状态,因此该选项可以添加到从服务器配置文件中
relay_log_purge=0 #中继日志
skip_name_resolve
重启mariadb服务
systemctl restart mariadb
实验主从复制
在从服务器192.168.32.201和192.168.32.202上进行以下配置:
[root@slave02 ssl]# mysql
MariaDB [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.32.200',
MASTER_USER='repluser',
MASTER_PASSWORD='magedu',
MASTER_LOG_FILE='mariadb-bin.000001',
MASTER_LOG_POS=245;
#注意:主从复制要从初始点开始复制,要把创建的复制账号信息一并复制给从节点
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G
测试:能否实现主从同步
在主服务器上导入测试数据库
mysql < hellodb_innodb.sql
在从服务器查看导入主服务器的测试数据库是否同步到从服务器
配置MHA
在管理节点上需要安装manager软件包和node软件包
把下载的软件包复制到管理节点上
软件包名:
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56-0.el6.noarch.rpm
在管理节点192.168.32.203主机上
yum -y install mha4mysql-manager-0.56-0.el6.noarch.rpm mha4mysql-node-0.56-0.el6.noarch.rpm
注意:软件包的安装必须启用epel源,解决依赖关系
在被管理节点上需要安装node软件包
分别在192.168.32.200、192.168.32.201、192.168.32.202三台主机上安装node软件包
软件包名为:mha4mysql-node-0.56-0.el6.noarch.rpm
yum -y install mha4mysql-node-0.56-0.el6.noarch.rpm
创建MHA配置文件
在管理节点192.168.32.203上
mkdir /etc/mha
vim /etc/mastermha/app1.cnf
[server default] #管理节点默认配置
user=mhauser #管理主从集群的账号
password=magedu #管理账号的密码
manager_workdir=/data/mastermha/app1/ #管理节点工作目录
manager_log=/data/mastermha/app1/manager.log #管理节点日志,有助于排错
remote_workdir=/data/mastermha/app1/ #被管理节点工作目录
ssh_user=root #远程ssh连接用户身份
repl_user=repluser #远程复制账号
repl_password=magedu #远程复制账号的密码
ping_interval=1 #监控被管理节点状态,一秒钟探测一次,如果发现故障就提升从服务器为新的主服务器
#以下为被管理的三个节点
[server1] #被管理节点
hostname=192.168.32.200
candidate_master=1 #有资格充当master的从服务器
[server2] #被管理节点
hostname=192.168.32.201
candidate_master=1 #有资格充当master的从服务器
[server3] #被管理节点
hostname=192.168.32.202
使用脚本进行MHA验证和启动
masterha_check_ssh --conf=/etc/mha/app1.conf #验证ssh连接
masterha_check_repl --conf=/etc/mha/app1.conf #验证复制账号连接
masterha_manager --conf=/etc/mastermha/app1.cnf #启用MHA
注意:该启动脚本以前台方式启动,如果中断关闭则MHA将会关闭,可以使用screen或nohup确保连接不能中断
测试:验证MHA是否成功启用
模拟主节点出现故障:
1.主节点服务器数据库服务出现故障
2.主节点物理服务器出现故障宕机
在主节点192.168.32.200主机上
强制关闭mysql服务,查看是否启用从服务器为新的主节点
killall mysqld
在管理节点192.168.32.203上
MHA前台进程自动关闭,该进程是一次性任务,完成任务就会结束,如果想要使用MHA,需要再次启动
查看日志
tail -50 /data/mastermha/app1/manager.log
----- Failover Report -----
app1: MySQL Master failover 192.168.32.200(192.168.32.200:3306) to 192.168.32.201(192.168.32.201:3306) succeeded
Master 192.168.32.200(192.168.32.200:3306) is down!
Check MHA Manager logs at ma:/data/mastermha/app1/manager.log for details.
Started automated(non-interactive) failover.
The latest slave 192.168.32.201(192.168.32.201:3306) has all relay logs for recovery.
Selected 192.168.32.201(192.168.32.201:3306) as a new master.
192.168.32.201(192.168.32.201:3306): OK: Applying all logs succeeded.
192.168.32.202(192.168.32.202:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.32.202(192.168.32.202:3306): OK: Applying all logs succeeded. Slave started, replicating from 192.168.32.201(192.168.32.201:3306)
192.168.32.201(192.168.32.201:3306): Resetting slave info succeeded.
Master failover to 192.168.32.201(192.168.32.201:3306) completed successfully.
从日志可以看出192.168.32.201称为新的主服务器,而从服务器192.168.32.202也指向新的主服务器192.168.32.201
在从服务器192.168.32.202验证
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.32.201
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000001
Read_Master_Log_Pos: 245
Relay_Log_File: mariadb-relay-bin.000002
Relay_Log_Pos: 531
Relay_Master_Log_File: mariadb-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 245
Relay_Log_Space: 827
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
在配置文件中,从服务器设置为read_only只读状态,现在查看新的主服务器是否为只读状态
MariaDB [none]> show variables like 'read_only';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+
可以发现,read_only只读状态自动被关闭
注意:此时要把配置文件中的read_only选项删除,更改后无需重启服务
在新的主服务器192.168.32.201上插入数据查看能否同步
MariaDB [(none)]> use hellodb
MariaDB [hellodb]> insert teachers values(6,'b',30,'M');
在从服务器192.168.32.202上查看信息是否同步
MariaDB [(none)]> select * from hellodb.teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | a | 30 | F |
| 6 | b | 30 | M |
+-----+---------------+-----+--------+Galera Cluster
- Galera Cluster:集成了Galera插件的MySQL集群,是一种新型的,数据不共享的,高度冗余的高可用方案,目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster,Galera本身是具有多主特性的,即采用multi-master的集群架构,是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案
- 下图图示:三个节点组成了一个集群,与普通的主从架构不同,它们都可以作为主节点,三个节点是对等的,称为multi-master架构,当有客户端要写入或者读取数据时,连接哪个实例都是一样的,读到的数据是相同的,写入某一个节点之后,集群自己会将新数据同步到其它节点上面,这种架构不共享任何数据,是一种高冗余架构
-
Galera Cluster特点
多主架构:真正的多点读写的集群,在任何时候读写数据,都是最新的
同步复制:集群不同节点之间数据同步,没有延迟,在数据库挂掉之后,数据不会丢失
并发复制:从节点APPLY数据时,支持并行执行,更好的性能
故障切换:在出现数据库故障时,因支持多点写入,切换容易
热插拔:在服务期间,如果数据库挂了,只要监控程序发现的够快,不可服务时间就会非常少。在节点故障期间,节点本身对集群的影响非常小
自动节点克隆:在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,Galera Cluster会自动拉取在线节点数据,最终集群会变为一致
对应用透明:集群的维护,对应用程序是透明的 -
Galera Cluster工作过程
- Galera Cluster官方文档:
http://galeracluster.com/documentation-webpages/galera-documentation.pdf
http://galeracluster.com/documentation-webpages/index.html
https://mariadb.com/kb/en/mariadb/getting-started-with-mariadb-galera-cluster/ - Galera Cluster包括两个组件
Galera replication library (galera-3)
WSREP:MySQL extended with the Write Set Replication - WSREP复制实现:
percona-cluster
MariaDB-Cluster
注意:都至少需要三个节点,不能安装mariadb-server
Galera Cluster实现
示例:
实验环境
master01主机:192.168.32.200
master02主机:192.168.32.201
master03主机:192.168.32.202
配置Galera Cluster:
分别在三台主机上安装软件包MariaDB-Galera-server
配置yum仓库如下:
vim /etc/yum.repos.d/mysql.repo
[mysql]
name=Galera-Cluster.repo
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-5.5.62/yum/centos7-amd64/
gpgcheck=0
安装软件包:
yum -y install MariaDB-Galera-server #注意大小写
在master01主机192.168.32.200上
vim /etc/my.cnf.d/server.cnf
[galera]
# Mandatory settings
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address="gcomm://192.168.32.200,192.168.32.201,192.168.32.202"
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
配置完成后,把配置文件复制到另外两台主机上
scp /etc/my.cnf.d/server.cnf 192.168.32.201:/etc/my.cnf.d/
scp /etc/my.cnf.d/server.cnf 192.168.32.202:/etc/my.cnf.d/
首次启动时,需要初始化集群,在其中一个节点上执行命令
/etc/init.d/mysql start --wsrep-new-cluster
而后正常启动其它节点
service mysql start
查看集群中相关系统变量和状态变量
SHOW VARIABLES LIKE 'wsrep_%';
SHOW STATUS LIKE 'wsrep_%';
SHOW STATUS LIKE 'wsrep_cluster_size';
测试:查看集群能否同步
在master01上导入测试数据库
mysql < hellodb_innodb.sql #导入hellodb数据库
在其他节点上查看能否自动同步
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hellodb |
| mysql |
| performance_schema |
| test |
+--------------------+
测试:主主模型,在加入数据时,会出现id号冲突现象,现在在两个节点同时加入数据查看是否能够解决冲突问题
在SecureCRT上同时向三个终端窗口发送插入数据的命令
MariaDB [(none)]> use hellodb
MariaDB [hellodb]> insert teachers(name,age,gender)values('a',30,'M');
查看结果,发现自动解决冲突问题
MariaDB [hellodb]> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 6 | a | 30 | M |
| 7 | a | 30 | M |
| 8 | a | 30 | M |
+-----+---------------+-----+--------+复制的问题和解决方案
- 复制的问题和解决方案:
(1) 数据损坏或丢失
Master: MHA + semi repl,即MHA加半同步复制
Slave: 重新复制
(2) 混合使用存储引擎,MyISAM即将淘汰,不推荐使用
MyISAM:不支持事务
InnoDB: 支持事务
(3) 不惟一的server id
重新复制
(4) 复制延迟
需要额外的监控工具的辅助
一从多主:mariadb10版后支持
多线程复制:对多个数据库复制

文章评论